Golang 递归处理HTML
摘自《Go语言圣经》第五章
函数可以是递归的,这意味着函数可以直接或间接的调用自身。对许多问题而言,递归是一种强有力的技术,例如处理递归的数据结构。
尝试使用非标准包 golang.org/x/net/html ,解析HTML。golang.org/x/… 目录下存储了一些由Go团队设计、维护,对网络编程、国际化文件处理、移动平台、图像处理、加密解密、开发者工具提供支持的扩展包。未将这些扩展包加入到标准库原因有二,一是部分包仍在开发中,二是对大多数Go语言的开发者而言,扩展包提供的功能很少被使用。
例子中调用golang.org/x/net/html的部分api如下所示。html.Parse函数读入一组bytes.解析后,返回html.node类型的HTML页面树状结构根节点。HTML拥有很多类型的结点如text(文本),commnets(注释)类型,在下面的例子中,我们 只关注< name key=‘value’ >形式的结点。
golang.org/x/net/html
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
package html
type Node struct {
Type NodeType
Data string
Attr []Attribute
FirstChild, NextSibling *Node
}
type NodeType int32
const (
ErrorNode NodeType = iota
TextNode
DocumentNode
ElementNode
CommentNode
DoctypeNode
)
type Attribute struct {
Key, Val string
}
func Parse(r io.Reader) (*Node, error)
|
main函数解析HTML标准输入,通过递归函数visit获得links(链接),并打印出这些links:
findlinks
// findlinks1.go
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
// Findlinks1 prints the links in an HTML document read from standard input.
package main
import (
"fmt"
"os"
"golang.org/x/net/html"
)
func main() {
doc, err := html.Parse(os.Stdin)
if err != nil {
fmt.Fprintf(os.Stderr, "findlinks1: %v\n", err)
os.Exit(1)
}
for _, link := range visit(nil, doc) {
fmt.Println(link)
}
}
|
visit函数遍历HTML的节点树,从每一个anchor元素的href属性获得link,将这些links存入字符串数组中,并返回这个字符串数组。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
// visit appends to links each link found in n and returns the result.
func visit(links []string, n *html.Node) []string {
if n.Type == html.ElementNode && n.Data == "a" {
for _, a := range n.Attr {
if a.Key == "href" {
links = append(links, a.Val)
}
}
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
links = visit(links, c)
}
return links
}
|
为了遍历结点n的所有后代结点,每次遇到n的孩子结点时,visit递归的调用自身。这些孩子结点存放在FirstChild链表中。
让我们以搜狗的主页(www.sougou.com)作为目标,运行findlinks。我们以fetch(1.5章)的输出作为findlinks的输入。下面的输出做了简化处理。
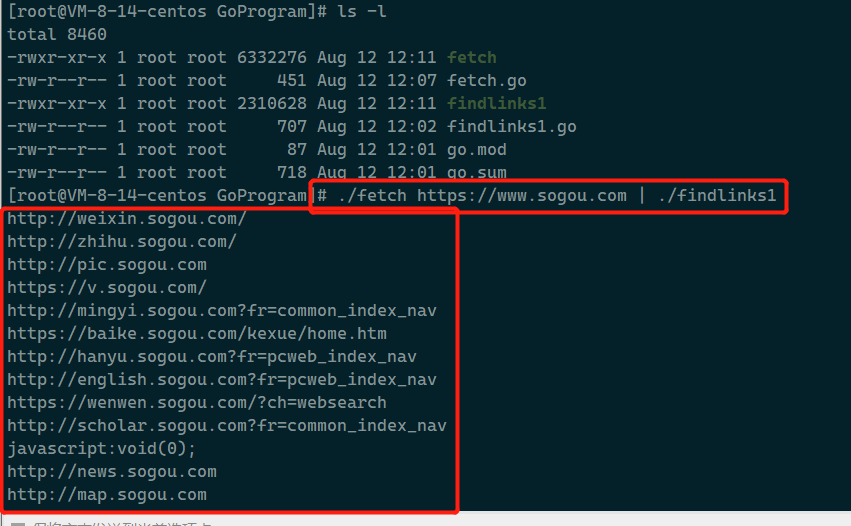
注意在页面中出现的链接格式,在之后我们会介绍如何将这些链接,根据根路径生成可以直接访问的url。
outline
在函数outline中,我们通过递归的方式遍历整个HTML结点树,并输出树的结构。在outline内部,每遇到一个HTML元素标签,就将其入栈,并输出。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
func main() {
doc, err := html.Parse(os.Stdin)
if err != nil {
fmt.Fprintf(os.Stderr, "outline: %v\n", err)
os.Exit(1)
}
outline(nil, doc)
}
func outline(stack []string, n *html.Node) {
if n.Type == html.ElementNode {
stack = append(stack, n.Data) // push tag
fmt.Println(stack)
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
outline(stack, c)
}
}
|
有一点值得注意:outline有入栈操作,但没有相对应的出栈操作。当outline调用自身时,被调用者接收的是stack的拷贝。被调用者的入栈操作,修改的是stack的拷贝,而不是调用者的stack,因对当函数返回时,调用者的stack并未被修改。
下面是https://www.sougou.com的简要结构:、
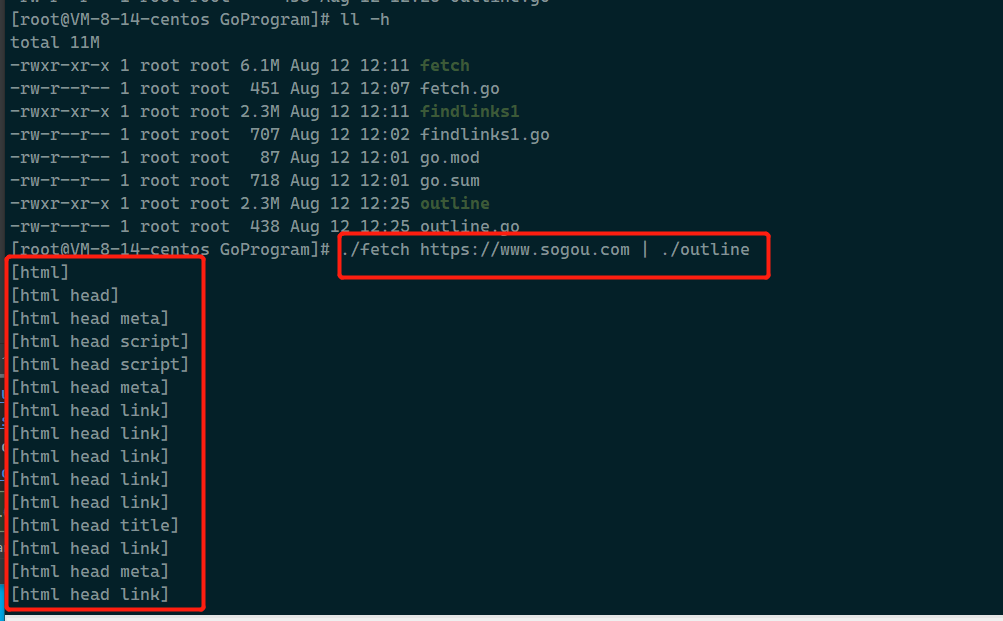
大部分HTML页面只需几层递归就能被处理,但仍然有些页面需要深层次的递归。
大部分编程语言使用固定大小的函数调用栈,常见的大小从64KB到2MB不等。固定大小栈会限制递归的深度,当你用递归处理大量数据时,需要避免栈溢出;除此之外,还会导致安全性问题。与相反,Go语言使用可变栈,栈的大小按需增加(初始时很小)。这使得我们使用递归时不必考虑溢出和安全问题。