RabbitMQ官网的消息模型的第二种-Work Queue(工作队列);
第二种模型(Work Queue)
介绍
Work queues, 也被称为(Task queues), 任务模型;当消息处理比较耗时的时候,可能生产消息的速度会远远大于消费消息的速度。长此以往,消息就会堆积的越来越多,无法及时处理;此时就可以使用work模型, **让多个消费者绑定到同一个队列,共同消费队列中的消息;**队列中的消息一旦消费,就会消失,因此任务是不会被重复执行的;
工作队列/任务队列
(Use Go RabbitMQ Client)
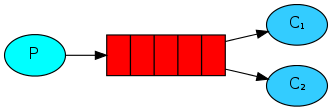
角色:
- P: 生产者: 任务的发布者;
- C1: 消费者-1, 领取任务并且完成任务, 假设完成任务速度较慢;
- C2:消费者-2, 领取任务并且完成任务, 假设完成任务速度较快;
在第一个教程中,我们编写程序从命名的队列发送和接收消息。在这一节中,我们将创建一个工作队列,该队列将用于在多个worker之间分配耗时的任务。
工作队列(又称任务队列)的主要思想是**避免立即执行某些资源密集型任务并且不得不等待这些任务完成。相反,我们安排任务异步地同时或在当前任务之后完成。**我们将任务封装为消息并将其发送到队列,在后台运行的工作进程将取出消息并最终执行任务。当你运行多个工作进程时,任务将在他们之间共享。
这个概念在Web应用中特别有用,因为在Web应用中不可能在较短的HTTP请求窗口内处理复杂的任务,(译注:例如注册时发送邮件或短信验证码等场景)。
准备工作
上一个hello world版本里面, 我们发送了一条包含“ Hello World!”的消息。现在,我们将发送代表复杂任务的字符串。我们没有实际的任务,例如调整图像大小或渲染pdf文件,所以我们通过借助time.Sleep函数模拟一些比较耗时的任务。我们会将一些包含.的字符串封装为消息发送到队列中,其中每有一个.就表示需要耗费1秒钟的工作,例如,hello...表示一个将花费三秒钟的假任务。
依旧是对send.go进行改造,以允许从命令行发送任意消息。该程序会将任务安排到我们的工作队列中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
// 从命令行参数中获取要发送的消息正文
body := bodyFrom(os.Args)
err = ch.Publish(
"", //exchange
q.Name, // routing key
false, //mandatory
false, //immediate
amqp.Publishing{
DeliveryMode:amqp.Persistent,
ContentType: "text/plain",
Body: []byte(body),
},
)
failOnError(err, "Failed to publish a message")
log.Printf(" [x] Sent %s", body)
|
其中, bodyFrom的实现如下:
1
2
3
4
5
6
7
8
9
|
func bodyFrom(args []string) string {
var s string
if (len(args) < 2) || os.Args[1] == ""{
s = "hello, go rabbit 2nd workqueue test"
} else {
s = strings.Join(args[1:], " ")
}
return s
}
|
改造一下之前的receive.go, 它需要为消息正文中出现的每个.伪造一秒钟的工作。它将从队列中弹出消息并执行任务,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
msgs, err := ch.Consume(
q.Name, // queue
"", // consumer
true, // auto-ack
false, // exclusive
false, // no-local
false, // no-wait
nil, // arguments
)
failOnError(err, "Failed to register a consumer")
forever := make(chan bool)
go func() {
for d := range msgs {
log.Printf("Received a message : %s", d.Body)
dot_count := bytes.Count(d.Body, []byte(".")) // 数一下有几个.
t := time.Duration(dot_count)
time.Sleep(t * time.Second) // 模拟耗时的任务
log.Printf("Done")
}
}()
log.Printf(" [*] Waiting for messages, To exit press CTRL+C")
<-forever
|
注意到这里是用假任务模拟耗时任务的执行时间,
我们可以打开两个终端, 测试一下看看效果:
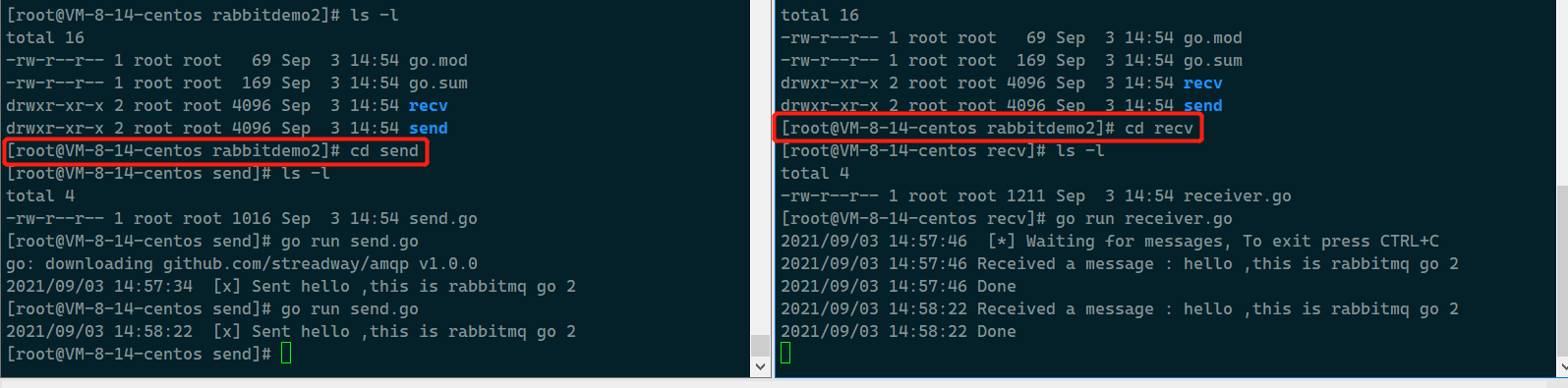
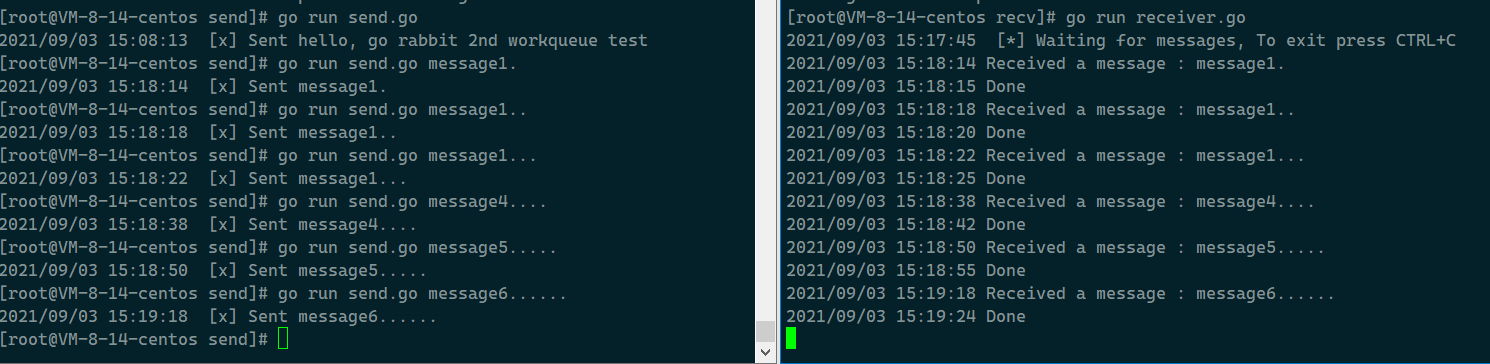
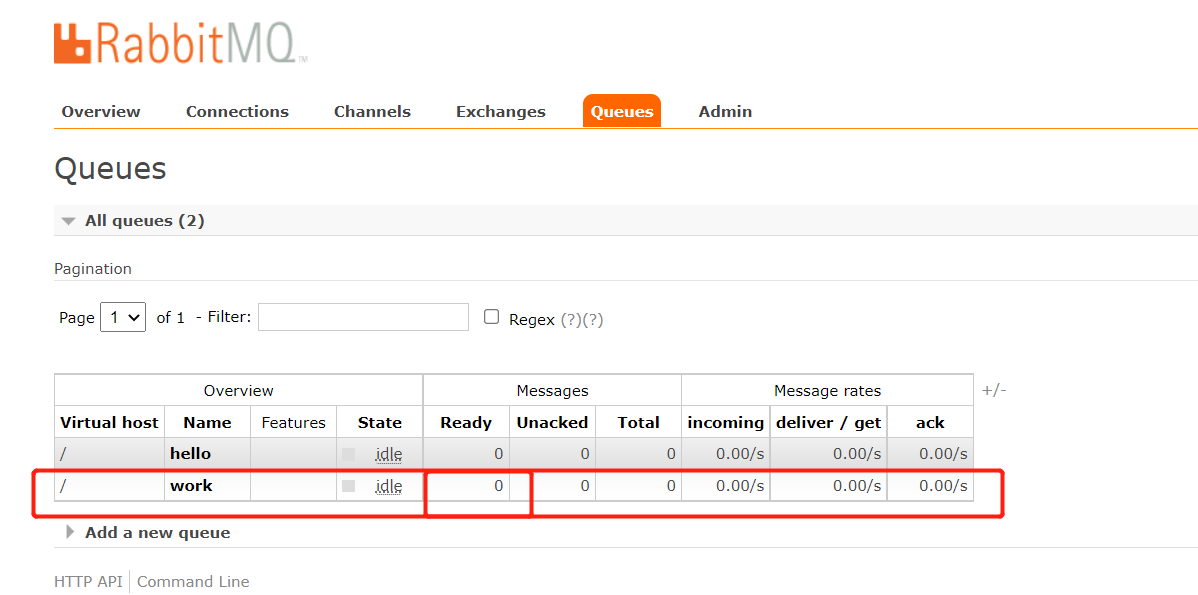
这里创建一个name为"work"的队列, 并发送10条消息,
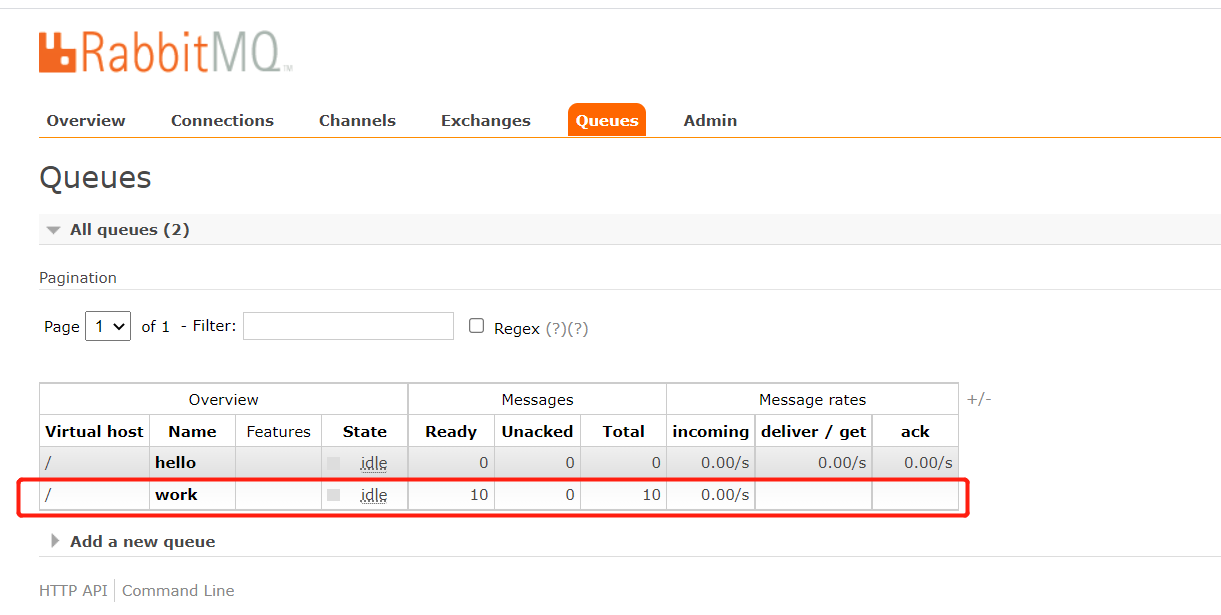
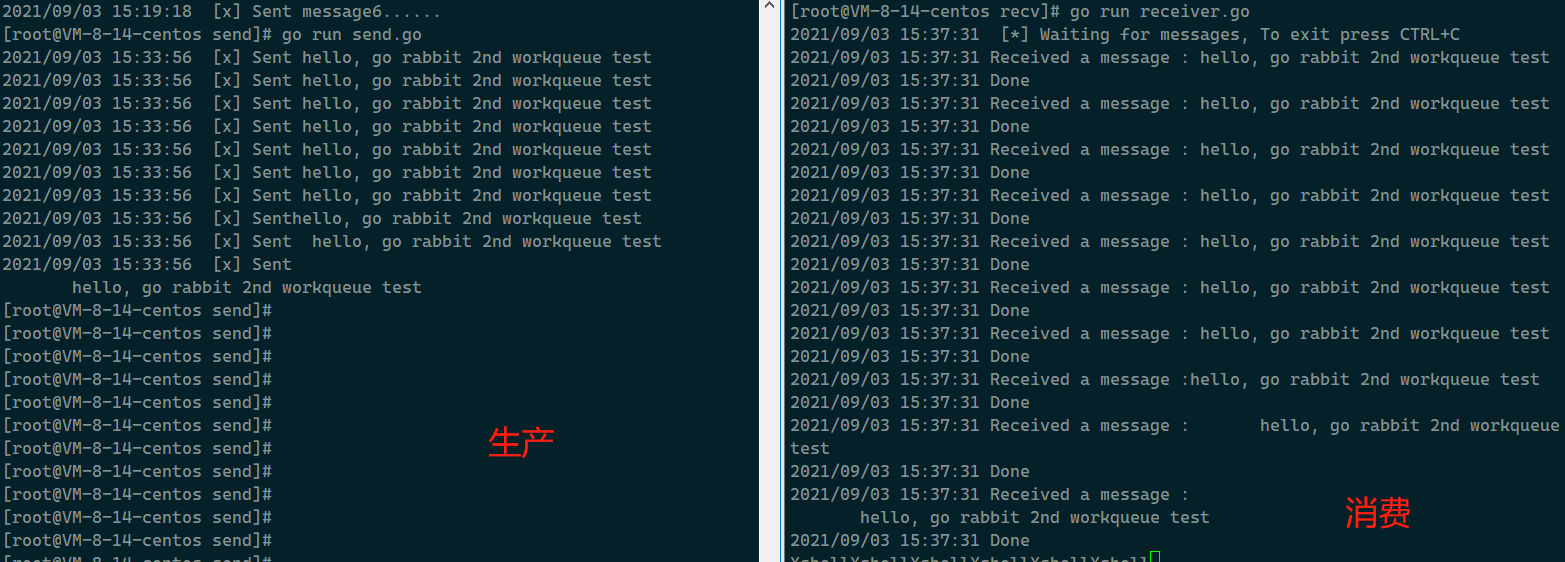
消费过后, message也就变成0条了,
循环调度
使用任务队列的优点之一是能够轻松并行化工作。如果我们的工作正在积压,我们可以增加更多的工人,这样就可以轻松扩展。
换一个case, 创建两个消费者一个生产者, 生产者生产30条消息,两个消费者消费,结果近乎发现是两个消费者是平均消费消息的:
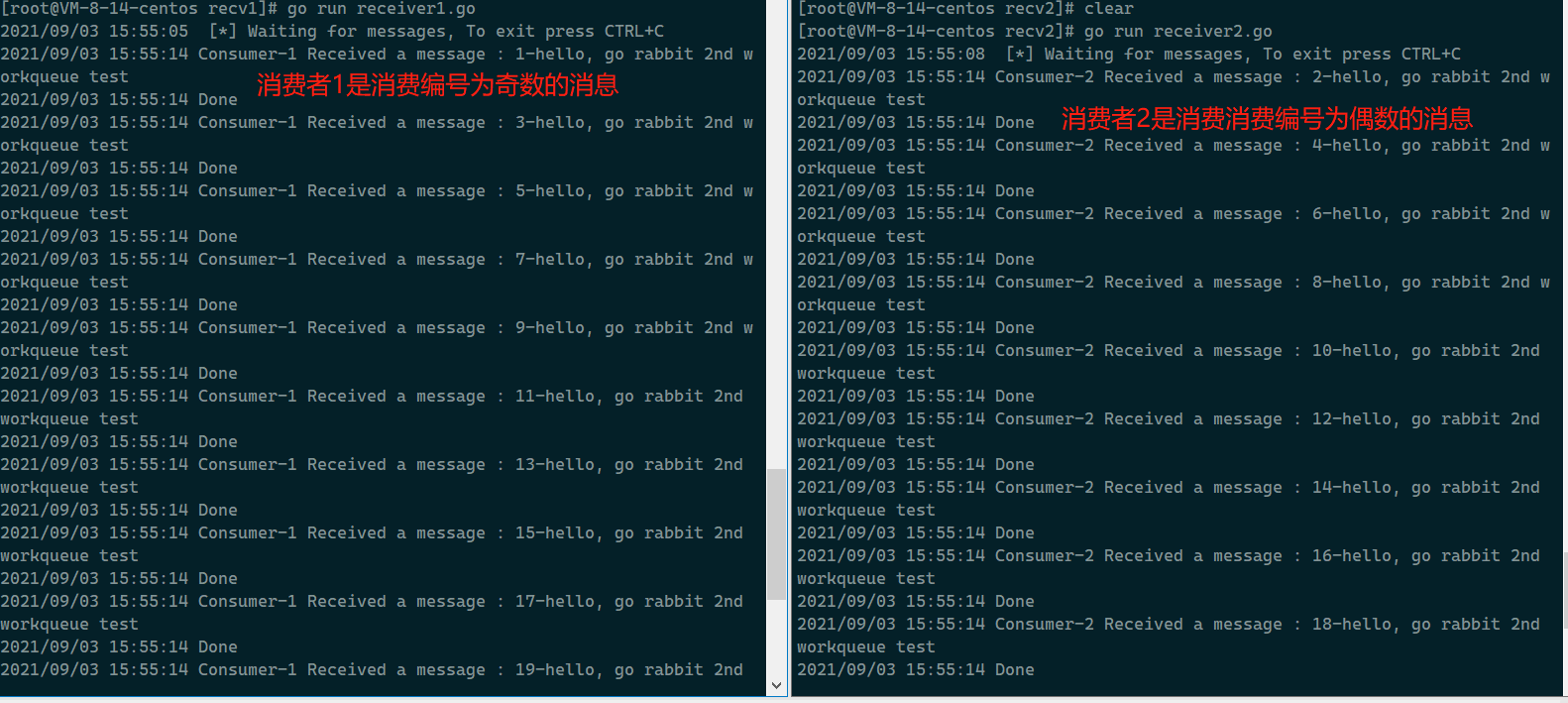
By default, RabbitMQ will send each message to the next consumer, in sequence. On average every consumer will get the same number of messages. This way of distributing messages is called round-robin. Try this out with three or more workers.
官网上也说了,默认情况下,RabbitMQ 将按顺序将每条消息发送给下一个消费者。平均而言,每个消费者将获得相同数量的消息。这种分发消息的方式称为轮询。可以尝试用三个或者更多的worker试验一下;
消费确认
work 完成任务可能需要耗费几秒钟,如果一个worker在任务执行过程中宕机了该怎么办呢?我们当前的代码中,RabbitMQ一旦向消费者传递了一条消息,便立即将其标记为删除。在这种情况下,如果你终止一个worker那么你就可能会丢失这个任务,我们还将丢失所有已经交付给这个worker的尚未处理的消息。
我们不想丢失任何任务,如果一个worker意外宕机了,那么我们希望将任务交付给其他worker来处理。
为了确保消息永不丢失,RabbitMQ支持 消息确认。消费者发送回一个确认(acknowledgement),以告知RabbitMQ已经接收,处理了特定的消息,并且RabbitMQ可以自由删除它。
如果使用者在不发送确认的情况下死亡(其通道已关闭,连接已关闭或TCP连接丢失),RabbitMQ将了解消息未完全处理,并将对其重新排队。如果同时有其他消费者在线,它将很快将其重新分发给另一个消费者。这样,您可以确保即使工人偶尔死亡也不会丢失任何消息。
没有任何消息超时;RabbitMQ将在消费者死亡时重新传递消息。即使处理一条消息需要很长时间也没关系。
在本教程中,我们将使用手动消息确认,方法是为“auto-ack”参数传递一个false,然后在完成任务后,使用d.Ack(false)从worker发送一个正确的确认(这将确认一次传递)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
msgs, err := ch.Consume(
q.Name, // queue
"", // consumer
true, // auto-ack, 这个参数设置为false, 即是关闭消息的自动确认
false, // exclusive
false, // no-local
false, // no-wait
nil, // arguments
)
failOnError(err, "Failed to register a consumer")
forever := make(chan bool)
go func() {
for d := range msgs {
log.Printf("Consumer-1 Received a message : %s", d.Body)
dot_count := bytes.Count(d.Body, []byte(".")) // 数一下有几个.
t := time.Duration(dot_count)
time.Sleep(t * time.Second) // 模拟耗时的任务
log.Printf("Done")
d.Ack(false) // 手动传递消息确认
}
}()
log.Printf(" [*] Waiting for messages, To exit press CTRL+C")
<-forever
|
使用这段代码,我们可以确保即使你在处理消息时使用CTRL+C杀死一个worker,也不会丢失任何内容。在worker死后不久,所有未确认的消息都将被重新发送。
消息确认必须在接收消息的同一通道(Channel)上发送。尝试使用不同的通道(Channel)进行消息确认将导致通道级协议异常。有关更多信息,请参阅确认的文档指南。
忘记确认
忘记确认是一个常见的错误。这是一个简单的错误,但后果是严重的。当你的客户机退出时,消息将被重新传递(这看起来像随机重新传递),但是RabbitMQ将消耗越来越多的内存,因为它无法释放任何未确认的消息。
为了调试这种错误,可以使用rabbitmqctl打印messages_unacknowledged字段:
1
2
3
4
5
6
7
8
9
|
> sudo rabbitmqctl list_queues name messages_ready messages_unacknowledged
### 消息持久化
我们已经学会了如何确保即使消费者死亡,任务也不会丢失。但是如果RabbitMQ服务器停止运行,我们的任务仍然会丢失。
当RabbitMQ退出或崩溃时,它将忘记队列和消息,除非您告诉它不要这样做。要确保消息不会丢失,需要做两件事:我们需要将队列和消息都标记为持久的。
首先,我们需要确保队列能够在RabbitMQ节点重新启动后继续运行。为此,我们需要声明它是持久的:
|
1
2
3
4
5
6
7
8
|
q, err := ch.QueueDeclare(
"hello", // name
true, // 声明为持久队列
false, // delete when unused
false, // exclusive
false, // no-wait
nil, // arguments
)
|
虽然这个命令本身是正确的,但它在我们当前的设置中不起作用。这是因为我们已经定义了一个名为hello的队列,它不是持久的。RabbitMQ不允许你使用不同的参数重新定义现有队列,并将向任何尝试重新定义的程序返回错误。但是有一个快速的解决方法——让我们声明一个具有不同名称的队列,例如work:
1
2
3
4
5
6
7
8
|
q, err := ch.QueueDeclare(
"work", //name
false, //durable
false, //delete when unused
false, //exclusive
false, //no wait
nil, //arguments
)
|
1
2
3
4
5
6
7
8
9
10
11
|
err = ch.Publish(
"", //exchange
q.Name, // routing key
false, //mandatory (强制)
false, //immediate (立即)
amqp.Publishing{
DeliveryMode: amqp.Persistent, // 持久(交付模式: 瞬态/持久)
ContentType: "text/plain",
Body: []byte(body),
},
)
|
有关消息持久性的说明
将消息标记为持久性并不能完全保证消息不会丢失。尽管它告诉RabbitMQ将消息保存到磁盘上,但是RabbitMQ接受了一条消息并且还没有保存它时,仍然有一个很短的时间窗口。而且,RabbitMQ并不是对每个消息都执行fsync(2)——它可能只是保存到缓存中,而不是真正写入磁盘。持久性保证不是很强,但是对于我们的简单任务队列来说已经足够了。如果您需要更强有力的担保,那么您可以使用publisher confirms。
公平分发
我们可能已经注意到调度仍然不能完全按照我们的要求工作。例如,在一个有两个worker的情况下,当所有的奇数消息都是重消息而偶数消息都是轻消息时,一个worker将持续忙碌,而另一个worker几乎不做任何工作。嗯,RabbitMQ对此一无所知,仍然会均匀地发送消息。
这是因为RabbitMQ只是在消息进入队列时发送消息。它不考虑消费者未确认消息的数量。只是盲目地向消费者发送信息。
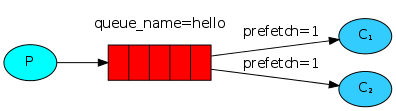
如何达到能者多劳?, 也就是让处理能力快的worker多处理一些,处理慢的worker少做一些;
为了解决这个问题,我们可以将prefetch(预取计数)设置为1。这告诉 RabbitMQ 一次不要给一个worker多个消息。换句话说,在处理并确认前一条消息之前,不要向worker发送新消息。相反,它会将它分派给下一个不忙的worker。
1
2
3
4
5
|
err = ch.Qos(
1, // prefetch count, 预取计数
0, // prefetch size
false, // global
)
|
关于队列大小的说明
如果所有的worker都很忙,你的queue随时可能会满。你会想继续关注这一点,也许需要增加更多的worker,或者有一些其他的策略。
完整的代码Demo
producer.go
1
2
3
4
5
6
7
|
// 为了避免到处都是if err != nil的判断, 对错误处理进行了封装
func failOnError(err error, msg string) {
if err != nil {
log.Fatalf("%s:%s", msg, err)
// panic(fmt.Sprintf("%s:%s", msg, err))
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
package main
import (
"github.com/streadway/amqp"
"log"
"os"
"strconv"
"strings"
)
func failOnError(err error, msg string) {
if err != nil {
log.Fatalf("%s:%s", msg, err)
// panic(fmt.Sprintf("%s:%s", msg, err))
}
}
func bodyFrom(args []string) string {
var s string
if (len(args) < 2) || os.Args[1] == "" {
s = "hello, go rabbit 2nd workqueue test"
} else {
s = strings.Join(args[1:], " ")
}
return s
}
func main() {
conn, err := amqp.Dial("amqp://admin:admin@localhost:5672")
failOnError(err, "Failed to connect to RabbitMQ")
defer conn.Close()
ch, err := conn.Channel()
failOnError(err, "Failed to open a channel")
defer ch.Close()
q, err := ch.QueueDeclare(
"work", //name
false, //durable
false, //delete when unused
false, //exclusive
false, //no wait
nil, //arguments
)
failOnError(err, "Failed to declare a queue")
// 从命令行参数中获取要发送的消息正文, 这里我造30条消息,看下消费者是如何调度处理消息的
for i := 1; i < 31; i++ {
body := bodyFrom(os.Args)
body = strconv.Itoa(i) + "-" + body
err = ch.Publish(
"", //exchange
q.Name, // routing key
false, //mandatory
false, //immediate
amqp.Publishing{
DeliveryMode: amqp.Persistent, // 持久化
ContentType: "text/plain",
Body: []byte(body),
},
)
failOnError(err, "Failed to publish a message")
log.Printf(" [x] Sent %s", body)
}
}
|
consumer.go
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
|
package main
import (
"bytes"
"github.com/streadway/amqp"
"log"
"time"
)
func failOnError(err error, msg string) {
if err != nil {
log.Fatalf("%s:%s", msg, err)
// panic(fmt.Sprintf("%s:%s", msg, err))
}
}
func main() {
conn, err := amqp.Dial("amqp://admin:admin@localhost:5672")
failOnError(err, "Failed to connect to RabbitMQ")
defer conn.Close()
ch, err := conn.Channel()
failOnError(err, "Failed to open a channel")
defer ch.Close()
// declare a queue
q, err := ch.QueueDeclare(
"work",
true, // 声明为持久队列
false,
false,
false,
nil,
)
err = ch.Qos(
1,
0,
false)
failOnError(err, "ch.Qos() failed")
// 立即返回一个Delivery的通道
msgs, err := ch.Consume(
q.Name, // queue
"", // consumer
false, // auto-ack, 注意到这里需要传false, 代表关闭自动消息确认
false, // exclusive
false, // no-local
false, // no-wait
nil, // arguments
)
failOnError(err, "Failed to register a consumer")
forever := make(chan bool)
go func() {
for d := range msgs {
log.Printf("Consumer-2 Received a message : %s", d.Body)
dot_count := bytes.Count(d.Body, []byte(".")) // 数一下有几个.
t := time.Duration(dot_count)
time.Sleep(t * time.Second) // 模拟耗时的任务
log.Printf("Done")
d.Ack(false) // 手动传递消息确认
}
}()
log.Printf(" [*] Waiting for messages, To exit press CTRL+C")
<-forever
}
|
参考资料
- 李文周老师 Go语言客户端教程2
- RabbitMQ官网 WorkQueue-Go客户端
- MQ消息中间件之RabbitMQ