CPU上下文切换(下)
CPU上下文切换是保证Linux系统正常工作的一个核心功能,按照不同场景,可以分为进程上下文切换、线程上下文切换和中断上下文切换。那么,实际上我们要如何分析CPU上下文切换的问题?
查看系统的上下文切换情况
从上篇的学习我们知道,过多的上下文切换,会把CPU时间消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上,缩短进程真正运行的时间,成了系统性能大幅下降的一个元凶;
我们可以使用vmstat这个工具,来查询系统的上下文切换的情况。
vmstat是一个常用的系统性能分析工具,主要用来分析系统的内存使用情况,也常用来分析CPU上下文切换和中断的次数;
下图是一个vmstat使用的示例:
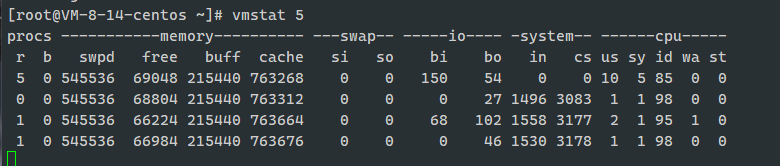
上图中是每隔5s输出一组数据。我们来终端关注其中这4列的内容:
- cs (context switch) 是每秒上下文切换的次数;
- in (interrupt) 则是每秒中断的次数;
- r (Running or Runnable)是就绪队列的长度,也就是正在运行和等待CPU的进程数;
- b (Blocked) 则是处于不可中断睡眠状态的进程数;
如上图中输出的第二条数据,例子的上下文切换次数cs是3083, 而系统中断次数是1496, 而就绪队列长度r和不可中断状态进程数b都是0;
vmstat只给出了系统总体的上下文切换情况,要想查看每个进程的详情情况,需要使用pidstat命令了, 使用"- w"选项,就可以看到每个进程上下文切换的情况了;
比如:
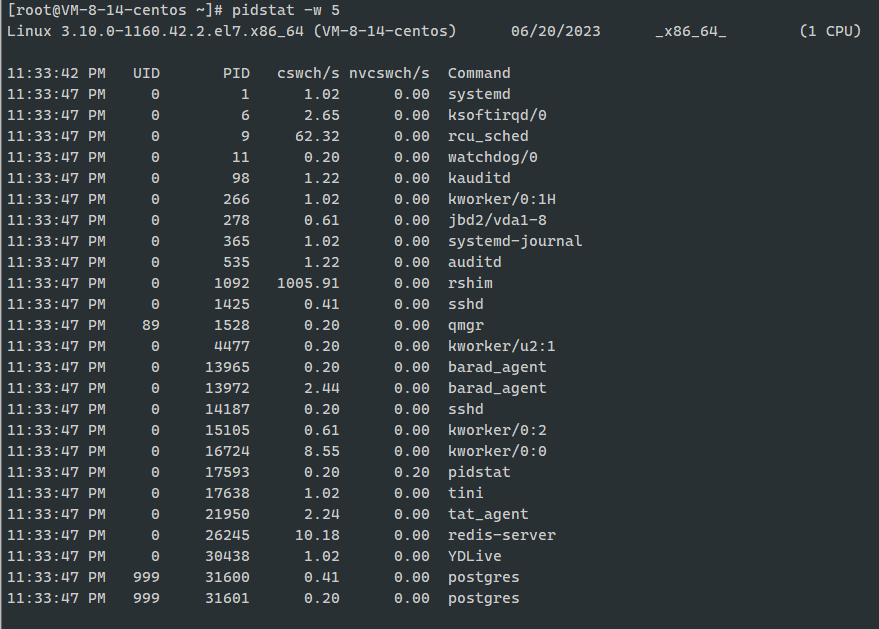
这个结果中有两列内容是我们重点关注对象;一个是cswch, 表示每秒自愿上下文切换(voluntary context switches)的次数,另一个则是nvcswch, 表示每秒非自愿上下文切换(non voluntary context switches)的次数;
这两个概念一定要牢牢记住, 因为它们意味着不同的性能问题:
- 所谓自愿上下文切换,是指进程无法获取所需资源,导致的上下文切换。比如说,I/O、内存等系统资源不足时,就会发生资源上下文切换;
- 而非自愿上下文切换,则是指进程由于时间片到等原因,被系统强制调度,进而发生的上下文切换;比如说,大量进程都在争抢CPU时,就容易发生非自愿上下文切换;
案例分析
知道了如何查看这些指标,那么上下文切换频率时多少次才算正常了?我们先来看一个上下文切换的案例,通过案例实战演练,我们就可以自己分析找出这个标准了;
准备
本案例,我们将使用sysbench来模拟系统多线程调度切换的情况;
sysbench是一个多线程的基准测试工具,一般用来不同系统参数下的数据库负载情况。当然,在这次案例中,我们只需把它当作一个异常进程来看,作用是模拟上下文切换的问题;
下面案例基于Ubuntu 18.04,
- 机器配置: 4 CPU, 8GB内存
- 预先安装
sysbench和sysstat包
先用vmstat看一下空闲系统的上下文切换次数:

可以看到,现在的上下文切换次数cs是283, 而中断次数in是181, r是1,b是0。
这会儿并没有运行其他任务,所以它们就是空闲系统的上下文切换次数;
操作和分析
首先,在终端一运行sysbench, 模拟系统多线程调度的瓶颈;
|
|
接着,在终端二运行vmstat, 观察上下文切换情况:
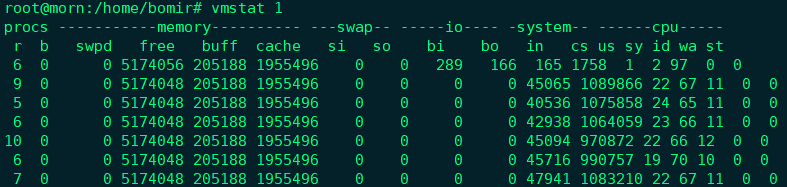
我们应该可以发现,cs列的上下文切换次数从之前的283骤然上升到107万。同时,要注意观察其他几个指标:
- r列:就绪队列的长度已经到了9,远远超过系统CPU的个数4,所以肯定有大量的CPU竞争;
- us (user)和sy (system)列: 这两列的CPU使用率加起来上升到了89%, 其中系统CPU使用率, 也就是sy列高达70%, 说明CPU主要是被内核占用了;
- in列:中断次数也上升到了4.5万左右,说明中断处理也是个潜在的问题;
综合这几个指标,我们可以知道,系统的就绪队列过长,也就是正在运行和等待CPU的进程数过多,导致了大量的上下文切换,而上下文切换又导致了系统的CPU的占用率升高;
那么到底是什么进程导致了这些问题呢?
继续分析,终端三再用pistat来看一下,CPU和进程上下文切换的情况:
|
|
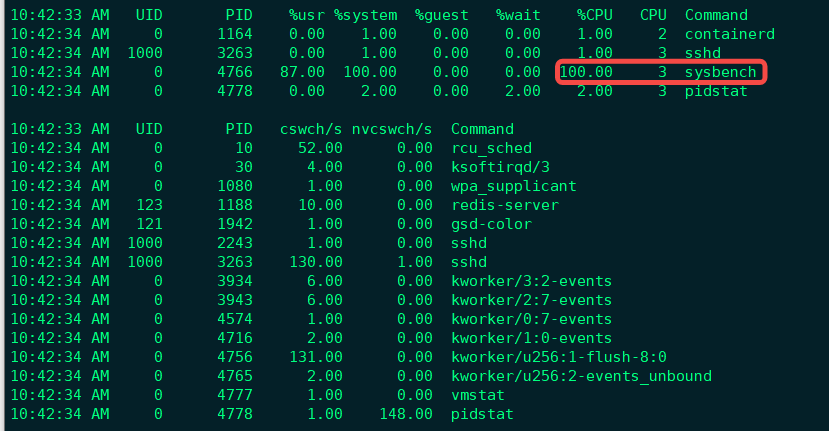
从pidstat的输出可以发现,CPU使用率的升高果然是sysbench导致的,它的CPU使用率已经达到了100%。但上下文切换则是来自其他进程,包括非自愿上下文切换频率最高的pidstat, 以及自愿上下文切换频率最高的内核线程kworker和sshd。
不过有一点比较奇怪:pidstat输出的上下文切换次数,加起来也就几百,比vmstat的一百多万明显小了太多;这个是什么回事呢?工具本身有问题吗?
先别着急下结论,我们来回顾下前面讲的几种上下文切换场景。其中有一点提到,Linux调度的基本单位实际上是线程,而我们的场景sysbench模拟的也是线程的调度问题,有没可能是pidstat忽略了线程的数据呢?
|
|
也就是说, pidstat默认显示进程的指标数据,加上-t参数后,才会输出线程的指标;
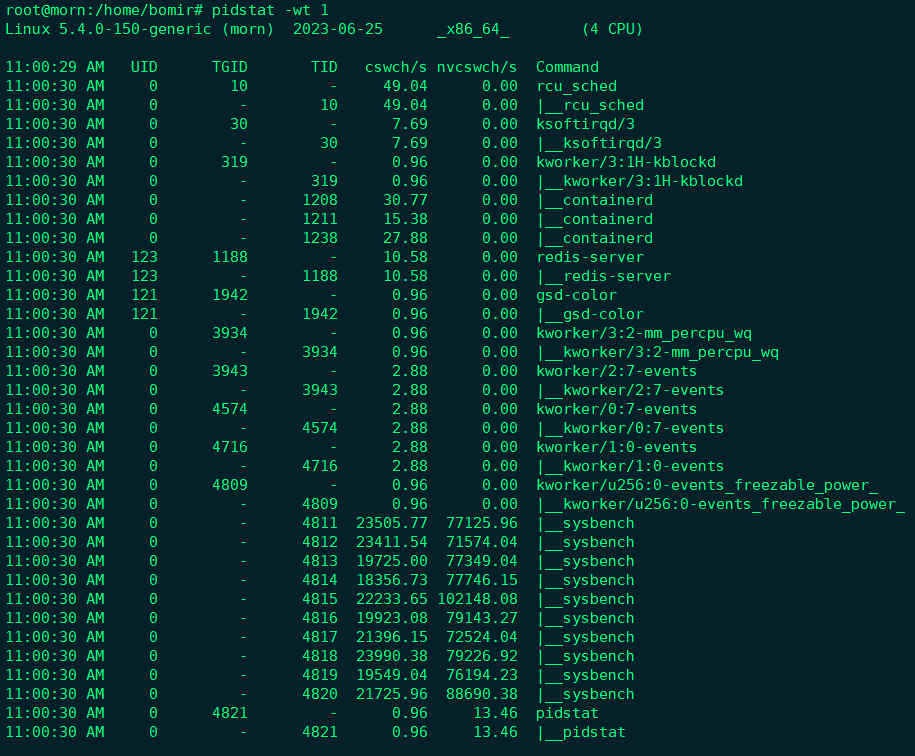
现在我们能看到了,虽然sysbench进程(也就是主线程)的上下文切换次数看起来并不多,但它的子线程的上下文切换次数却有很多;
现在基本可以判定,上下文切换过多的主要原因,就是过多的sysbench线程;
我们已经找到了上下文切换次数增多的根源,那么到这儿是不是就已经结束了呢?
当然不是,前面观察系统指标时,除了上下文切换频率骤然升高,还有一个中断次数指标也有很大的变化;中断次数到了4万多,但到底是什么类型的中断次数,现在还不清楚,需要往下细细排查;
既然是中断,我们都知道,它只发生在内核态;而pidstat只是一个进程的性能分析工具,并不能提供任何关于中断的详细信息,怎样才能知道发生的类型呢?
没错,那就是从/proc/interrupts这个只读文件中读取;/proc实际上是Linux的一个虚拟文件系统,用于内核空间和用户空间之间的通信。/proc/interrupts就是这种通信机制的一部分,提供了一个只读的中断使用情况;
我们来运行下面的命令,观察中断的变化情况:
|
|
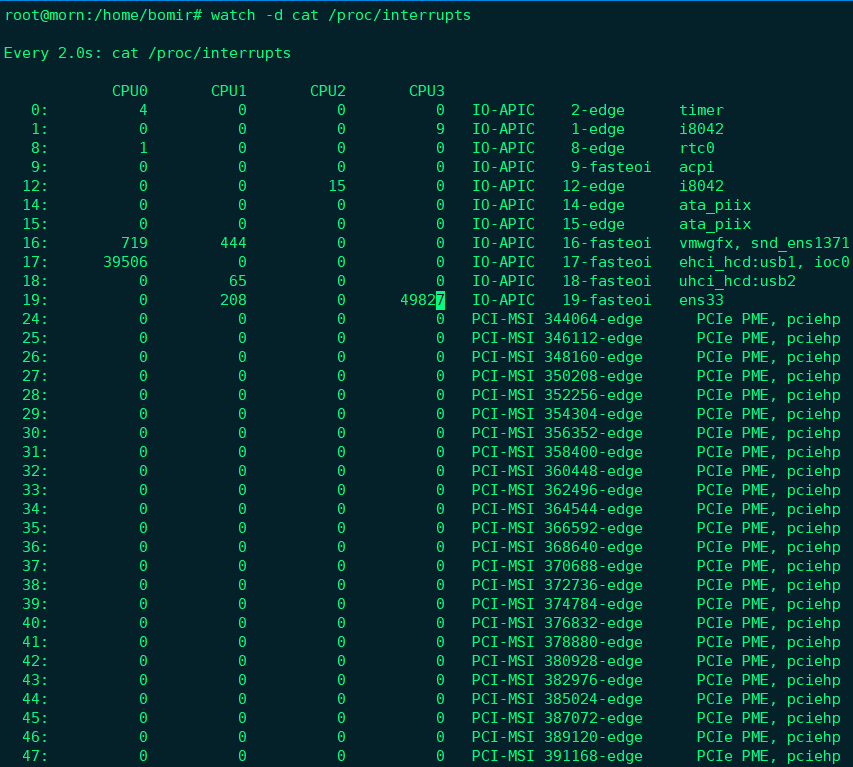

观察一段时间,可以发现,变化速度最快的是重调度中断(RES), 这个中断类型表示,唤醒空闲状态的CPU来调度新的任务运行;
这是多处理器(SMP)中,调度器用来分散任务到不同CPU的机制,通常也被称为处理器中断(Inter-Processor Interrupts, IPI),
所以,这里的中断升高还是因为过多任务的调度问题,跟前面上下文切换次数的分析结果是一致的;
通过这个案例,也可以看到多工具、多方面指标对比观测的好处。如果最开始,我们只用了pidstat观测,这些很严重的上下文切换线程,就不会被发现了;
那么,回到最初的问题,每秒上下文切换次数为多少才算是正常呢?
这个数值其实取决于系统本身的CPU性能;一般来说,如果系统上下文切换次数比较稳定,那么从数百到一万之间,都应该算是正常;但是当上下文切换次数超过一万次,或者切换次数出现数量级的增长时,就很可能已经出现了性能问题;
这时候,应该根据具体的上下文切换类型,再做分析;例如,
- 自愿上下文切换变多了,说明进程都在等待资源,有可能发生了IO等其他问题。
- 非自愿上下文切换变多了,说明进程都在被强制调度,也就是都在争抢CPU。说明CPU的确成了瓶颈。
- 中断次数变多了,说明CPU被中断处理程序占用,还需要通过查看/proc/interrupts文件来分析具体的中断类型。