运行应用
这一节从本章开始,我们将通过实践深入学习Kubernetes的各种特性。作为容器编排引擎,最重要也是最基本的功能当然是运行容器化应用。
Kubernetes通过各种Controller来管理Pod的生命周期。为了满足不同业务场景,Kubernetes开发了Deployment、ReplicaSet、DaemonSet、StatefuleSet、Job等多种Controller。我们首先学习最常用的Deployment。
Deployment
运行Deployment
上一个示例中已经通过Deployment部署了nginx-app,

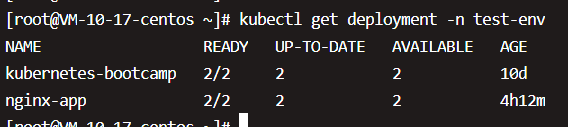
通过kubectl get deployment命令查看nginx-app的状态,输出显示两个副本正常运行。
接下来我们用kubectl describe deployment了解更详细的信息:
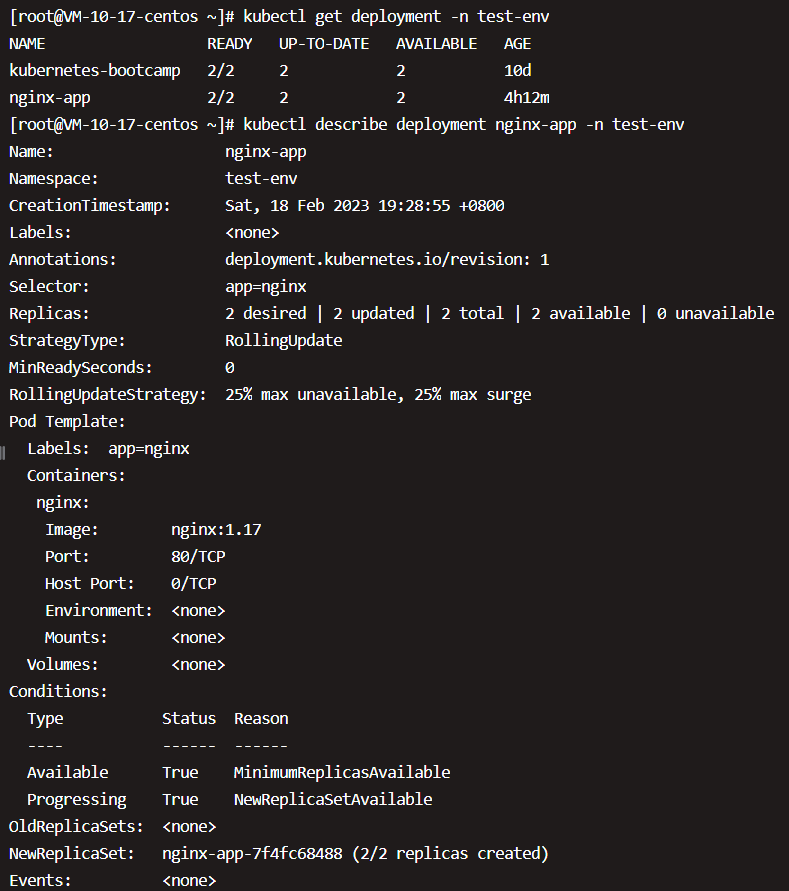
大部分内容都是自解释的,我们重点看上图Type部分。这里告诉我们创建了一个ReplicaSet nginx-app-7f4fc68488,Events是Deployment的日志,记录了ReplicaSet的启动过程。通过上面的分析,也验证了Deployment通过ReplicaSet来管理Pod的事实。接着我们将注意力切换到nginx-app-7f4fc68488,执行kubectl describe replicaset,
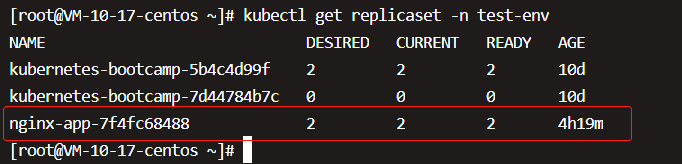
两个副本已经就绪,用kubectl describe replicaset查看详细信息,
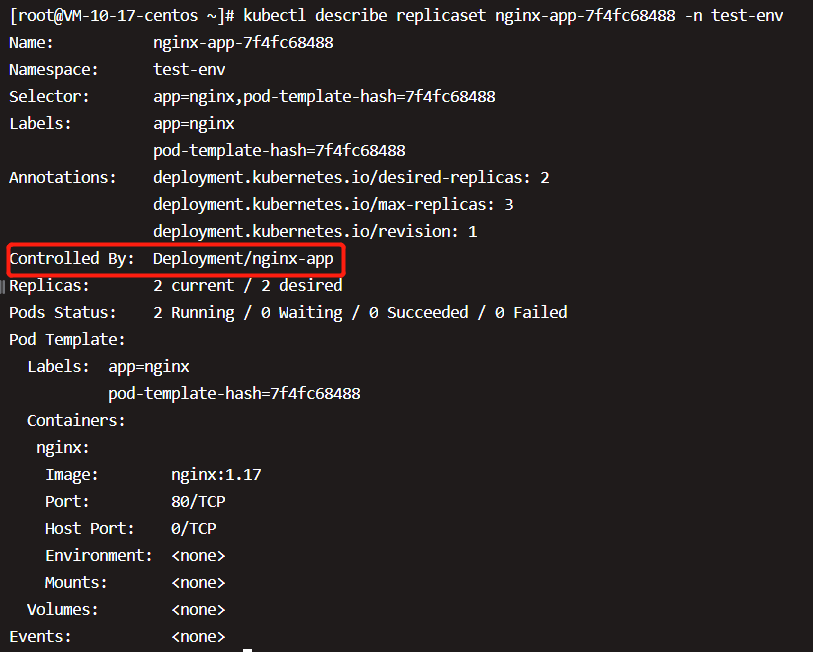
Controlled By指明此ReplicaSet是由Deployment nginx-app创建的。
接着我们来看下两个副本Pod创建的日志,接着我们来看Pod,执行kubectl get pod

两个副本Pod都处于Running状态,然后用kubectl describe pod查看更详细的信息,
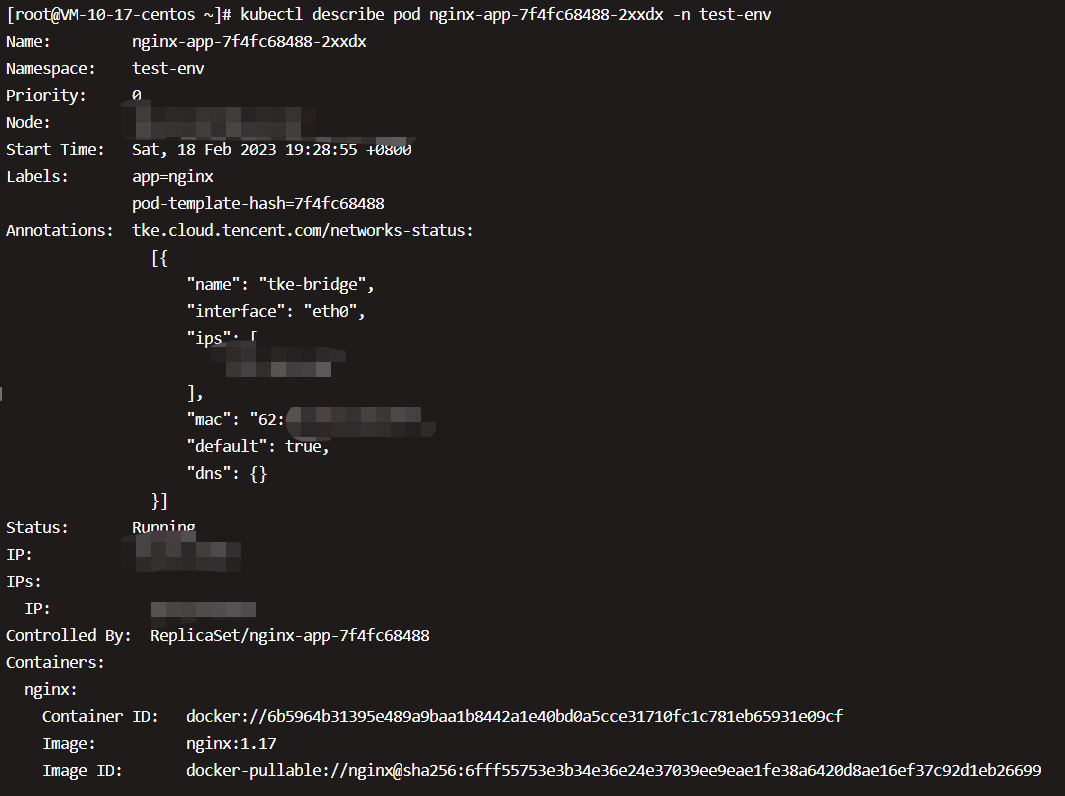
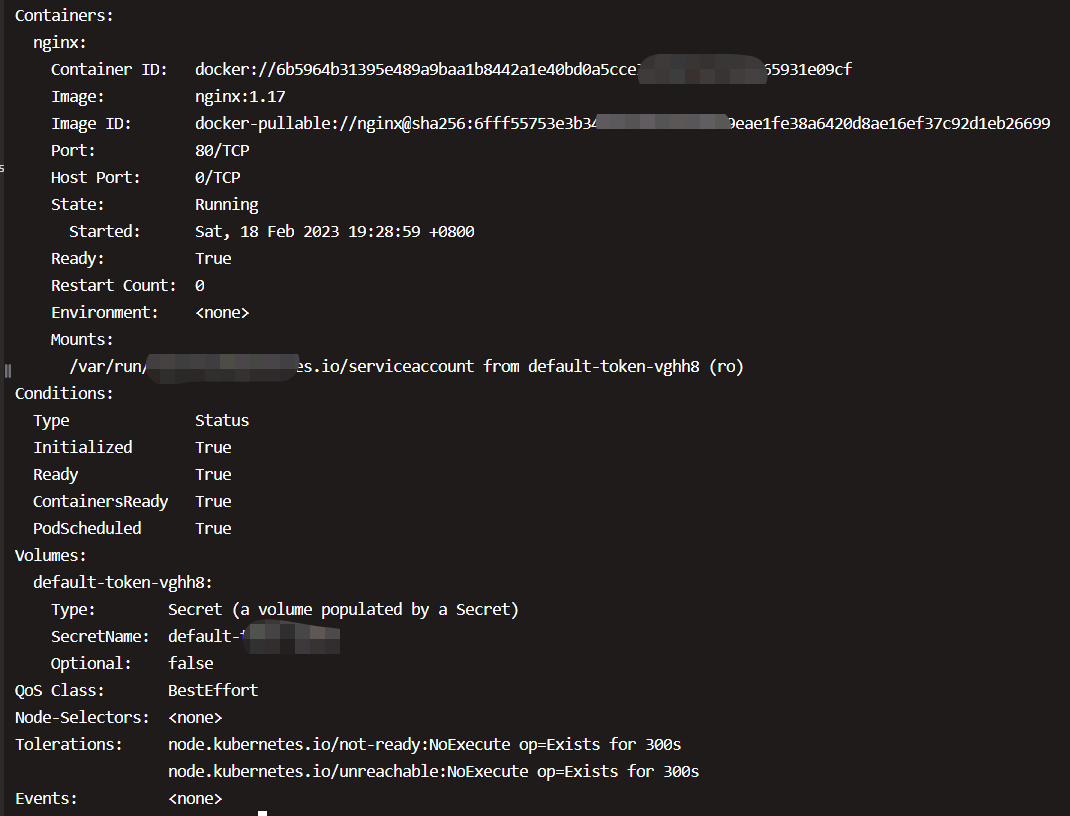
Controlled By指明此Pod是由ReplicaSet nginx-app-7f4fc68488创建的。Events记录了Pod的启动过程。如果操作失败(比如image不存在),也能在这里查到原因。
总结一下这个过程中,如下图所示:
- 用户通过kubectl创建Deployment。
- Deployment创建ReplicaSet。
- ReplicaSet创建Pod。
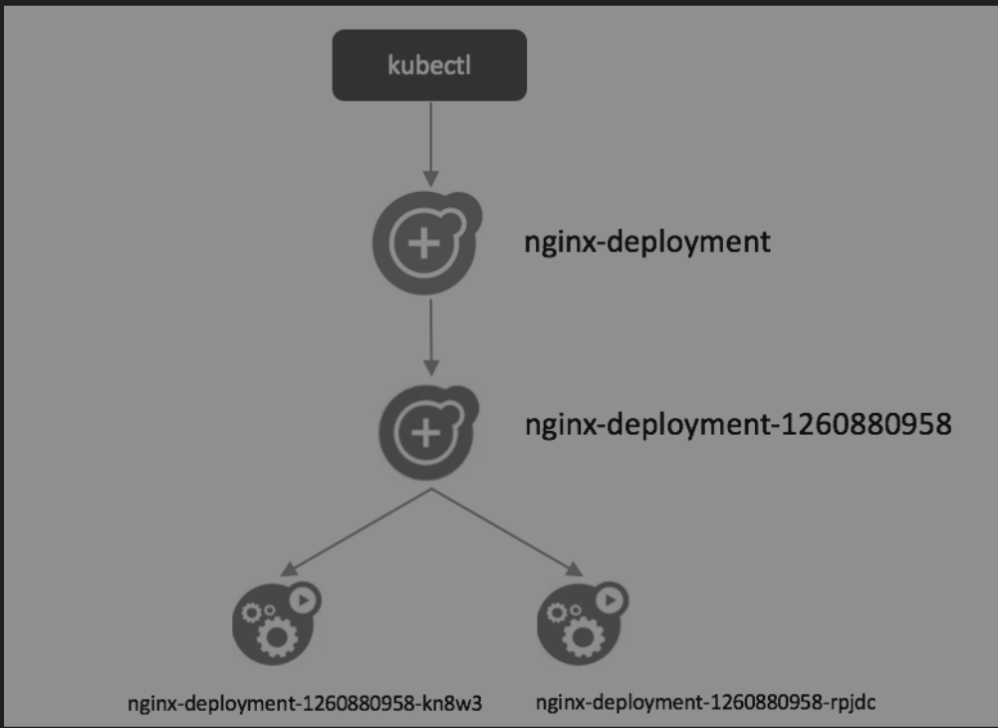
从图中也可以看出,对象的命名方式是**“子对象的名字=父对象名字+随机字符串或数字”。**
命令VS配置文件
Kubernetes支持两种创建资源的方式:
-
用kubectl命令直接创建,比如“kubectl run nginx-deployment –image=nginx:1.7.9–replicas=2”,在命令行中通过参数指定资源的属性。
-
通过配置文件和kubectl apply创建。要完成前面同样的工作,可执行命令“kubectl apply -f nginx.yml”,nginx.yml的内容如下所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30# API 版本号 apiVersion: apps/v1 # 类型,如:Pod/ReplicationController/Deployment/Service/Ingress kind: Deployment metadata: # Kind 的名称 name: nginx-app spec: selector: matchLabels: # 容器标签的名字,发布 Service 时,selector 需要和这里对应 app: nginx # 部署的实例数量 replicas: 2 template: metadata: labels: app: nginx spec: # 配置容器,数组类型,说明可以配置多个容器 containers: # 容器名称 - name: nginx # 容器镜像 image: nginx:1.17 # 只有镜像不存在时,才会进行镜像拉取 imagePullPolicy: IfNotPresent ports: # Pod 端口 - containerPort: 80资源的属性写在配置文件中,文件格式为YAML。
下面对这两种方式进行比较。
(1)基于命令的方式:简单、直观、快捷,上手快。适合临时测试或实验。
(2)基于配置文件的方式:配置文件描述了What,即应用最终要达到的状态。
配置文件提供了创建资源的模板,能够重复部署。可以像管理代码一样管理部署。适合正式的、跨环境的、规模化部署。这种方式要求熟悉配置文件的语法,有一定难度。
kubectl apply不但能够创建Kubernetes资源,也能对资源进行更新,非常方便。不过Kubernets还提供了几个类似的命令,例如kubectl create、kubectl replace、kubectl edit和kubectl patch。
为避免造成不必要的困扰,我们会尽量只使用kubectl apply,此命令已经能够应对百分之九十多的场景,事半功倍。
Deployment配置文件
既然要用YAML配置文件部署应用,现在就很有必要了解一下Deployment的配置格式了,其他Controller(比如DaemonSet)非常类似。
以nginx-deployment为例,配置文件如下图所示。
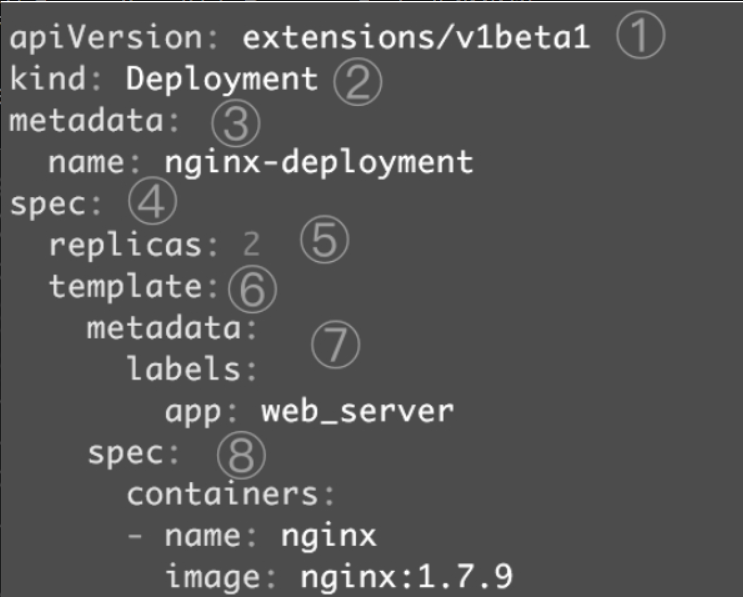
①apiVersion是当前配置格式的版本。
②kind是要创建的资源类型,这里是Deployment。
③metadata是该资源的元数据,name是必需的元数据项。
④spec部分是该Deployment的规格说明。
⑤replicas指明副本数量,默认为1。
⑥template定义Pod的模板,这是配置文件的重要部分。
⑦metadata定义Pod的元数据,至少要定义一个label。label的key和value可以任意指定。
⑧spec描述Pod的规格,此部分定义Pod中每一个容器的属性,name和image是必需的。
这个nginx.yml是一个最简单的Deployment配置文件,后面我们学习Kubernetes各项功能时会逐步丰富这个文件。
伸缩
伸缩是指在线增加或减少Pod的副本数。
Deployment nginx-app初始是两个副本,而且是k8s-node1和k8s-node2上各跑了一个副本。

现在修改yaml文件,将副本数改成5个,
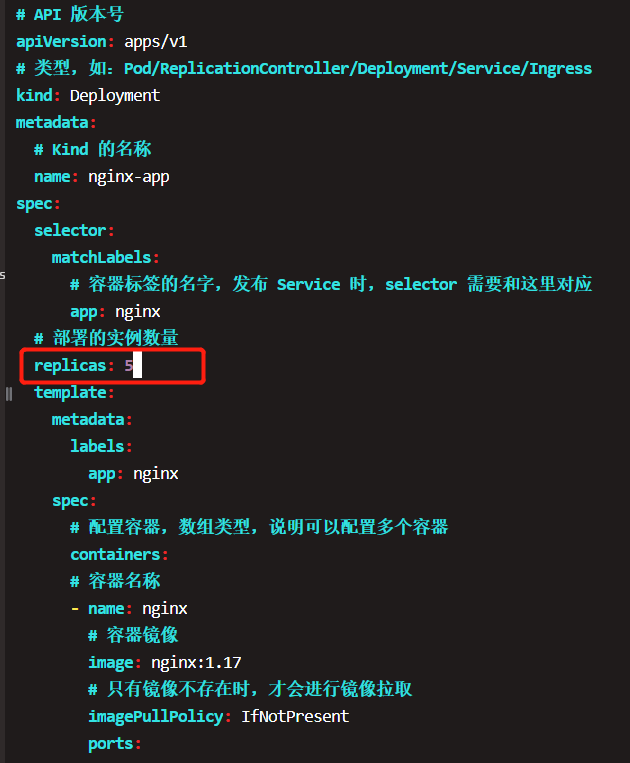

三个新副本被创建并调度到k8s-node3和k8s-node4上。
出于安全考虑,默认配置下Kubernetes不会将Pod调度到Master节点。如果希望将k8s-master也当作Node使用,可以执行如下命令:
|
|
如果要恢复Master Only的状态,执行如下命令:
|
|
接下来修改配置文件,将副本数减少为2个, 重新恢复为原来的样子,重新执行kubectl apply,

可以看到3个副本被删除,最终保留了2个副本。
FailOver
为了演示这个问题, 重新构建了一主两从的节点, 来演示停机的问题;

用户之前的yaml来生成3个副本,

模拟k8s-node2故障,关闭该节点,
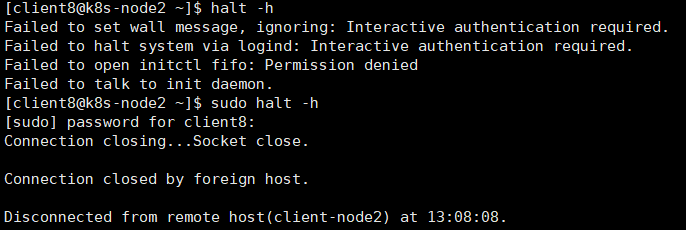
等待一段时间,Kubernetes会检查到k8s-node2不可用,将k8s-node2上的Pod标记为Unknown状态,并在k8s-node1上新创建两个Pod,维持总副本数为3,

当k8s-node2恢复后,Unknown的Pod会被删除,不过已经运行的Pod不会重新调度回k8s-node2,

删除nginx-app控制器,如下图所示:
用label控制Pod的位置
默认配置下,Scheduler会将Pod调度到所有可用的Node。不过有些情况我们希望将Pod部署到指定的Node,比如将有大量磁盘I/O的Pod部署到配置了SSD的Node;或者Pod需要GPU,需要运行在配置了GPU的节点上。
Kubernetes是通过label来实现这个功能的。label是key-value对,各种资源都可以设置label,灵活添加各种自定义属性。
比如执行如下命令标注k8s-node1是配置了SSD的节点。
|
|

disktype=ssd已经成功添加到k8s-node1,除了disktype,Node还有几个Kubernetes自己维护的label。有了disktype这个自定义label,接下来就可以指定将Pod部署到k8s-node1。
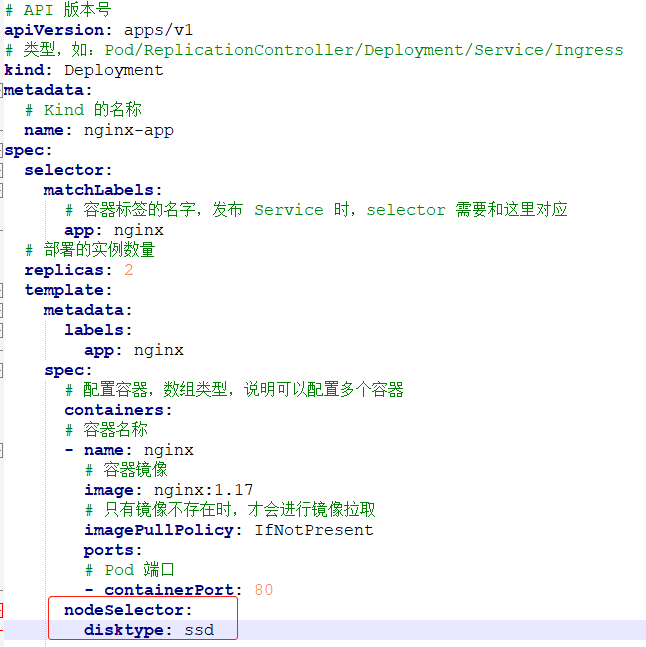
在Pod模板的spec里通过nodeSelector指定将此Pod部署到具有label disktype=ssd的Node上。部署Deployment并查看Pod的运行节点。全部2个pod副本都运行在k8s-node1上,符合我们的预期。
要删除label disktype,执行如下命令:
kubectl label node k8s-node1 disktype-
不过此时Pod并不会重新部署,依然在k8s-node1上运行,除非在nginx.yml中删除nodeSelector设置,然后通过kubectl apply重新部署。Kubernetes会删除之前的Pod并调度和运行新的Pod。
DaemonSet
Deployment部署的副本Pod会分布在各个Node上,每个Node都可能运行好几个副本。DaemonSet的不同之处在于:每个Node上最多只能运行一个副本。
DaemonSet的典型应用场景有:
- 在集群的每个节点上运行存储Daemon,比如glusterd或ceph。
- 在每个节点上运行日志收集Daemon,比如flunentd或logstash。
- 在每个节点上运行监控Daemon,比如Prometheus Node Exporter或collectd。
实际上,Kubernetes自己就是在用DaemonSet运行系统组件。
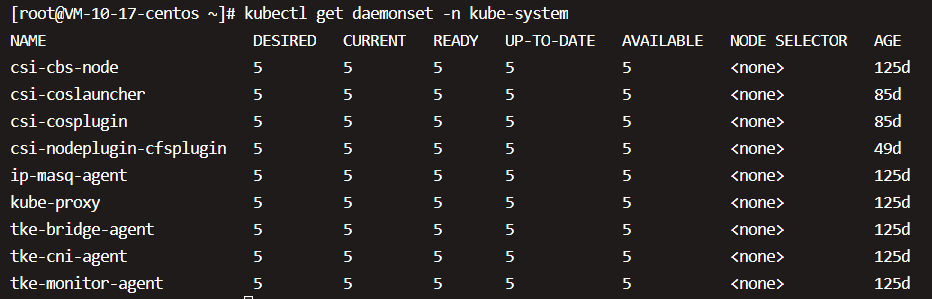
DaemonSet tke-cni-agent和kube-proxy分别负责在每个节点上运行tke-cni-agent和kube-proxy组件。
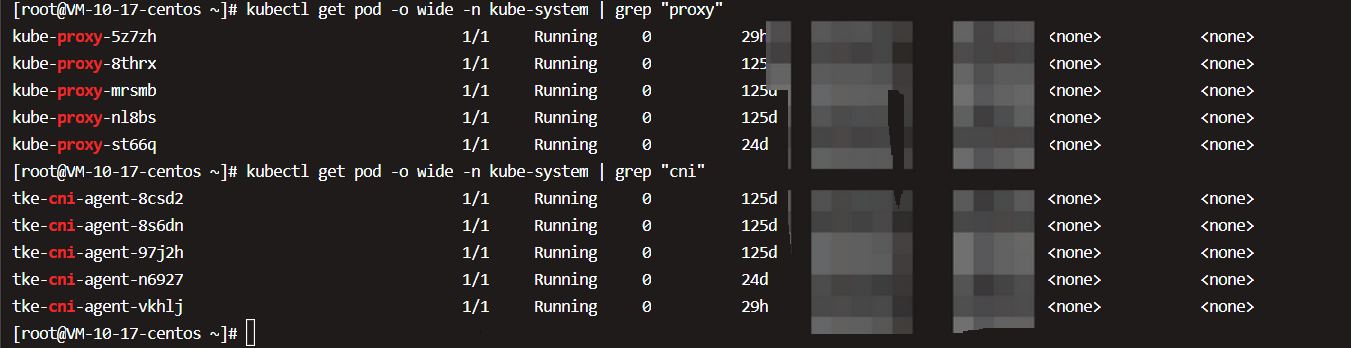
因为tke-cni-agent和kube-proxy属于系统组件,,需要在命令行中通过–namespace=kube-system指定namespace kube-system。若不指定,则只返回默认namespace default中的资源。
tke-cni-agent
|
|
注意:配置文件的完整内容要更复杂一些,为了更好地学习DaemonSet,这里只保留了最重要的内容。
- DaemonSet配置文件的语法和结构与Deployment几乎完全一样,只是将kind设为DaemonSet。
- hostName指定Pod直接使用的是Node网络,相当于docker run –network=host。考虑到cni需要为集群提供网络连接,这个要求是合理的。
- containers定义了运行cni服务的容器。
kube-proxy
由于无法拿到kube-proxy的YAML文件,只能运行如下命令查看配置:
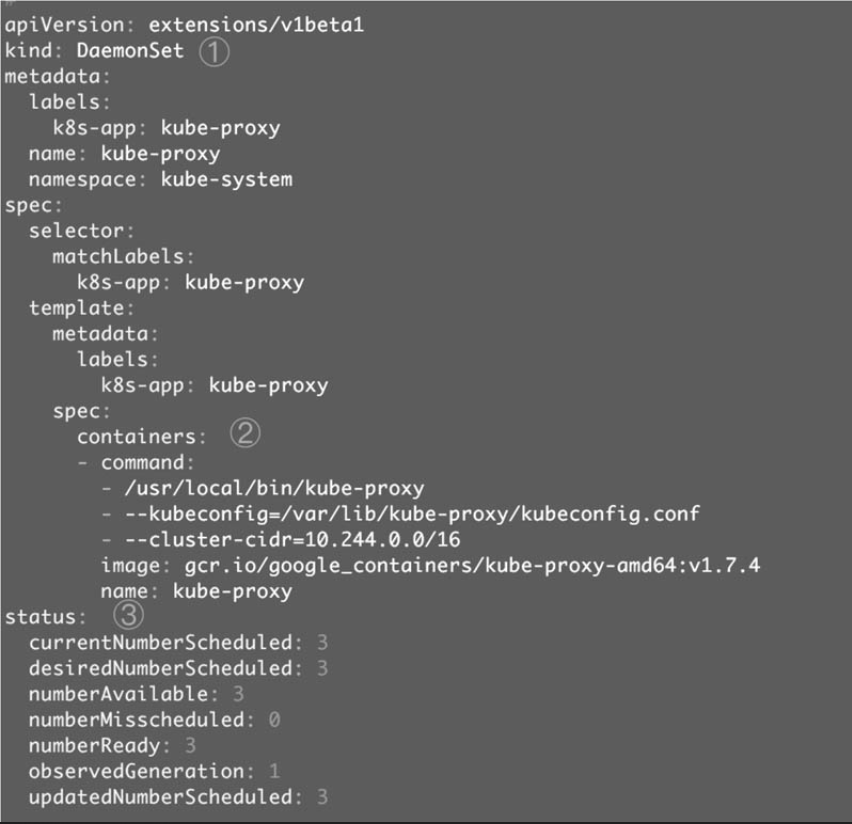
同样这里为了方便理解, 也是只是摘取最重要的部分信息。
①kind: DaemonSet指定这是一个DaemonSet类型的资源。
②containers定义了kube-proxy的容器。
③status是当前DaemonSet的运行时状态,这个部分是kubectl edit特有的。
其实Kubernetes集群中每个当前运行的资源都可以通过kubectl edit查看其配置和运行状态,比如kubectl edit deployment nginx-deployment。
运行自己的DaemonSet
这里以Prometheus Node Exporter为例演示用户如何运行自己的DaemonSet。
Prometheus是流行的系统监控方案,Node Exporter是Prometheus的agent,以Daemon的形式运行在每个被监控节点上。
|
|
将其转换为DaemonSet的YAML配置文件node_exporter.yml,
|
|
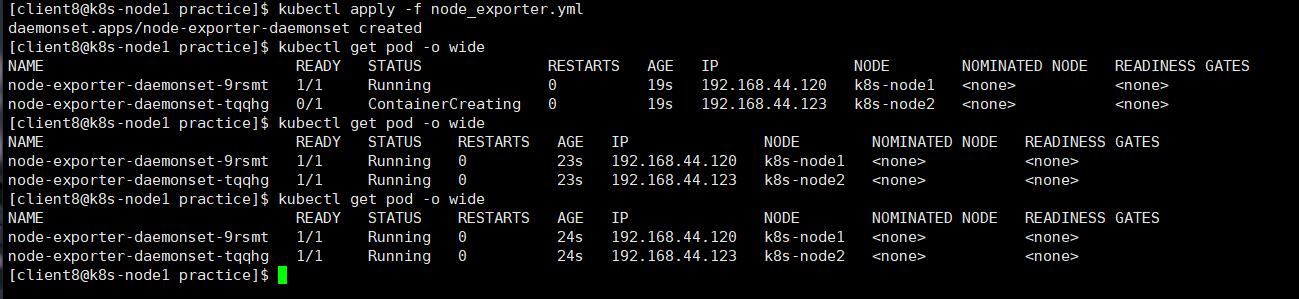
①直接使用Host的网络。
②设置容器启动命令。
③通过Volume将Host路径/proc、/sys和/映射到容器中。
从上图可知, DaemonSet node-exporter-daemonset部署成功,k8s-node1和k8s-node2上分别运行了一个node exporter Pod。
Job
容器按照持续运行的实践可分为两类容器:服务类容器和工作类容器。
服务类容器通常持续提供服务,需要一直运行,比如HTTP Server、Daemon等。
工作类容器则是一次性任务,比如批处理程序,完成后容器就退出。
Kubernetes的Deployment、ReplicaSet和DaemonSet都用于管理服务类容器;对于工作类容器,我们使用Job。
先来做一个简单的Job配置文件myjob.yml,
|
|
①batch/v1是当前Job的apiVersion。
②指明当前资源的类型为Job。
③restartPolicy指定什么情况下需要重启容器。对于Job,只能设置为Never或者OnFailure。对于其他controller(比如Deployment),可以设置为Always。

通过kubectl get job查看Job的状态,
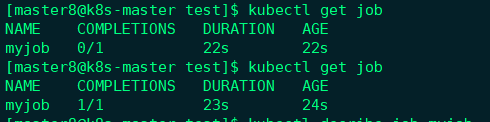
COMPLETIONS为1/1表示按照预期启动了一个Pod,并且已经成功执行。通过kubectl get pod查看Pod的状态

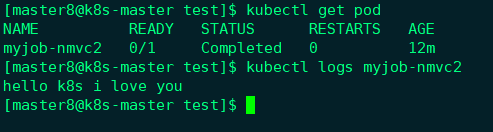
可以看到Pod执行完毕后容器已经退出。
通过kubectl logs可以查看Pod的标准输出。
Pod失败的情况
上述都是pod成功执行的情况,但如果Pod失败了是什么样子呢?
我们实验一下,修改myjob.yml,故意引入一个错误:
|
|
先删除之前的job,

运行新的Job并查看状态:
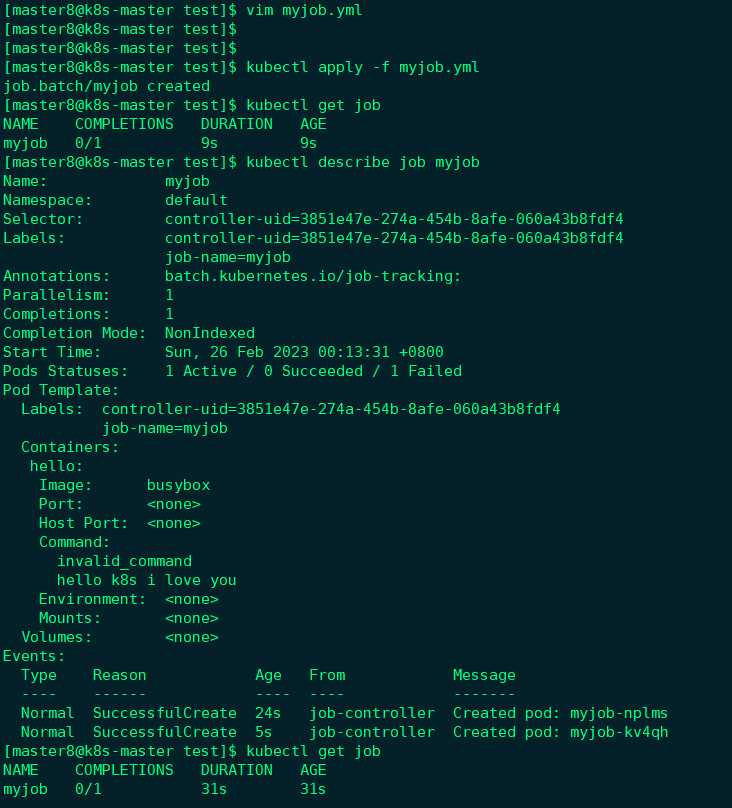
可以看到有多个Pod, 状态都不正常;
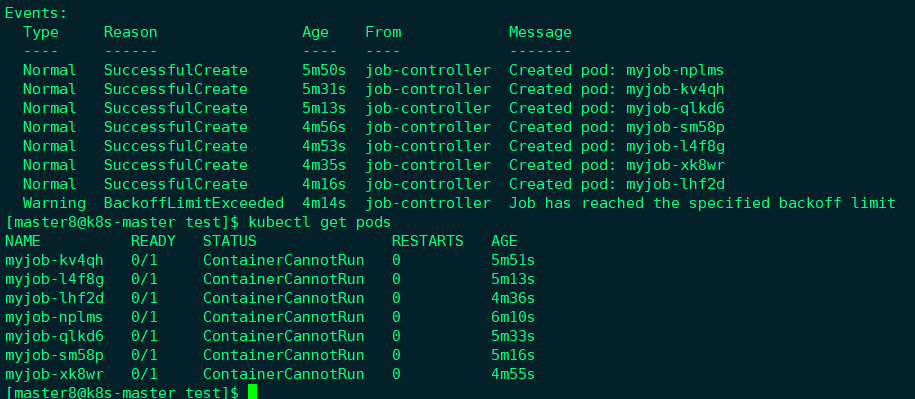
可以通过kubectl describe pod查看某个Pod的启动日志,

日志显示没有可执行程序,这符合我们的预期;
下面解释一个现象:为什么kubectl get pod会看到这么多个失败的Pod?
**原因是:**当第一个Pod启动时,容器失败退出,根据restartPolicy: Never,此失败容器不会被重启,但Job DESIRED的Pod是1,目前SUCCESSFUL为0,不满足,所以Job controller会启动新的Pod,直到SUCCESSFUL为1。对于我们这个例子,SUCCESSFUL永远也到不了1,所以Job controller会一直创建新的Pod(新的k8s看起来会设置一个limit, 重试过多会达到Job has reached the specified backoff limit)。为了终止这个行为,只能删除Job,

如果将restartPolicy设置为OnFailure会怎么样?下面我们实践一下,修改myjob.yml后重新启动:
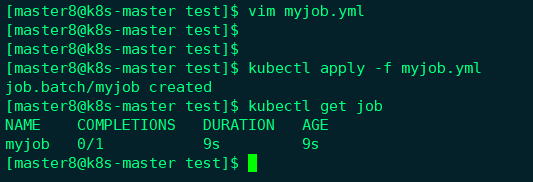
Job的SUCCESSFUL Pod数量还是0,再看看Pod的情况,

这里只有一个Pod,不过RESTARTS为3,而且不断增加,说明OnFailure生效,容器失败后会自动重启。
Job的并行性
有时我们希望能同时运行多个Pod,提高Job的执行效率。这个可以通过parallelism设置,
|
|
这里我们将并行的Pod数量设置为2,实践一下:
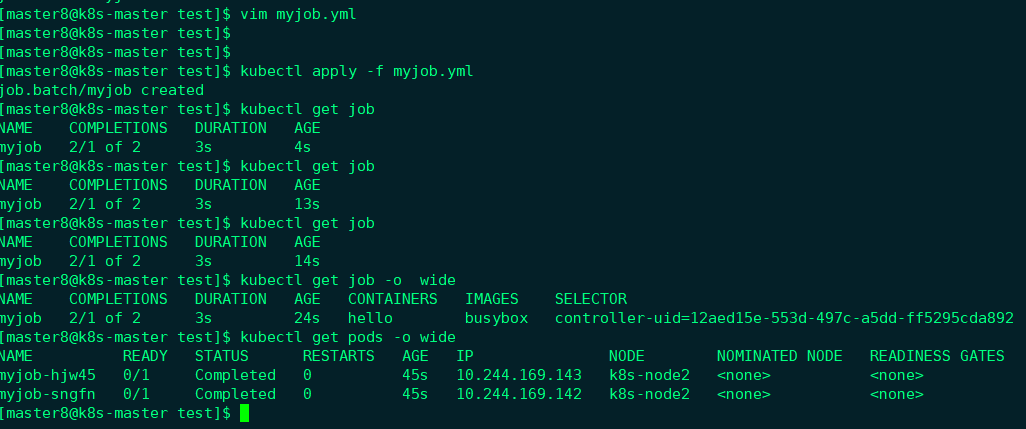
Job一共启动了两个Pod,而且AGE相同,可见是并行运行的。
我们还可以通过completions设置Job成功完成Pod的总数,
|
|
上面配置的含义是:每次运行两个Pod,直到总共有6个Pod成功完成。实践一下,
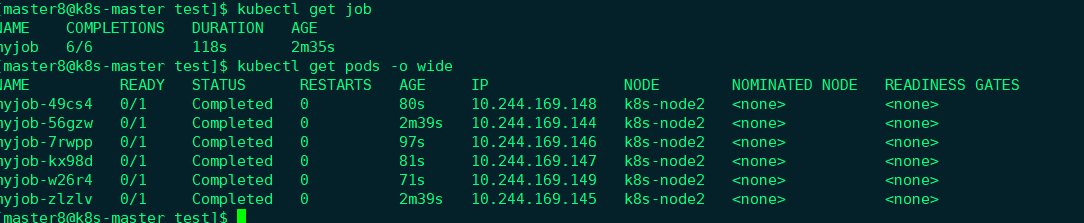
DESIRED和SUCCESSFUL均为6,符合预期。如果不指定completions和parallelism,默认值均为1。
上面的例子只是为了演示Job的并行特性,实际用途不大。不过现实中确实存在很多需要并行处理的场景。比如批处理程序,每个副本(Pod)都会从任务池中读取任务并执行,副本越多,执行时间就越短,效率就越高。这种类似的场景都可以用Job来实现。
定时Job
Linux中有cron程序定时执行任务,Kubernetes的CronJob提供了类似的功能,可以定时执行Job。
|
|
CronJob配置文件如下所示:
|
|
①batch/v2alpha1是当前CronJob的apiVersion。
②指明当前资源的类型为CronJob。
③schedule指定什么时候运行Job,其格式与Linux cron一致。这里*/1 * * * *的含义是每一分钟启动一次。
④jobTemplate定义Job的模板,格式与前面的Job一致。
接下来,通过kubectl apply创建CronJob:
通过kubectl get cronjob查看CronJob的状态,

等待几分钟,然后通过kubectl get jobs查看Job的执行情况,
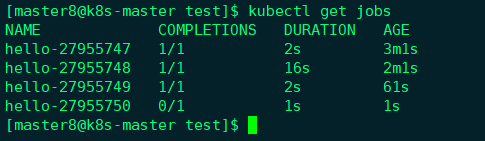
可以看到每隔一分钟就会启动一个Job。执行kubectl logs可查看某个Job的运行日志,

cronjob可以自动清理任务,默认保留3次成功的任务,我们可以通过添加.spec.successfulJobsHistoryLimit改变保留的历史任务信息即Pod。
Job期限与清理
除了Job执行结束与重启失败认定的Job 终止外还可以通过配置活跃期限(activeDeadlineSeconds)来自动停止Job任务。
我们可以为 Job 的 .spec.activeDeadlineSeconds 设置一个秒数值。 该值适用于 Job 的整个生命期,无论 Job 创建了多少个 Pod。 一旦 Job 运行时间达到 activeDeadlineSeconds 秒,其所有运行中的 Pod 都会被终止,并且 Job 的状态更新为 type: Failed 及 reason: DeadlineExceeded。
注意 Job 的 .spec.activeDeadlineSeconds 优先级高于其 .spec.backoffLimit 设置。 因此,如果一个 Job 正在重试一个或多个失效的 Pod,该 Job 一旦到达 activeDeadlineSeconds 所设的时限即不再部署额外的 Pod,即使其重试次数还未 达到 backoffLimit 所设的限制。
清理job和终止相似,我们可以通过添加spec.ttlSecondsAfterFinished使Job在任务完成后一段时间内被清理。