k8s重要概念
在做实践之前,必须要学习Kubernetes的几个重要概念,它们是组成Kubernetes集群的基石。
Cluster
Cluster是计算、存储和网络资源的集合,Kubernetes利用这些资源运行各种基于容器的应用。
Master
Master是Cluster的大脑,它的主要职责是调度,即决定将应用放在哪里运行。Master运行Linux操作系统,可以是物理机或者虚拟机。为了实现高可用,可以运行多个Master。
Node
Node的职责是运行容器应用。Node由Master管理,Node负责监控并汇报容器的状态,同时根据Master的要求管理容器的生命周期。Node运行在Linux操作系统上,可以是物理机或者是虚拟机。
Pod
Pod是Kubernetes的最小工作单元。每个Pod包含一个或多个容器。Pod中的容器会作为一个整体被Master调度到一个Node上运行。
K8s引入Pod有两个重要的目的:
a) 可管理性
有些容器天生就是需要紧密联系,一起工作。Pod提供了比容器更高层次的抽象,将它们封装到一个部署单元中。Kubernetes以Pod为最小单位进行调度、扩展、共享资源、管理生命周期。
b) 通信和资源共享
Pod中的所有容器使用同一个网络namespace,即相同的IP地址和Port空间。它们可以直接用localhost通信。同样的,这些容器可以共享存储,当Kubernetes挂载volume到Pod,本质上是将volume挂载到Pod中的每一个容器。
Pod有两种使用方式:
- 运行单一容器
one-container-per-Pod是Kubernetes最常见的模型,这种情况下,只是将单个容器简单封装成Pod。即便是只有一个容器,Kubernetes管理的也是Pod而不是直接管理容器。
- 运行多个容器
试想一下:哪样的容器会放在同一个Pod里面?
答案是:这些容器联系必须非常紧密,而且需要直接共享资源。
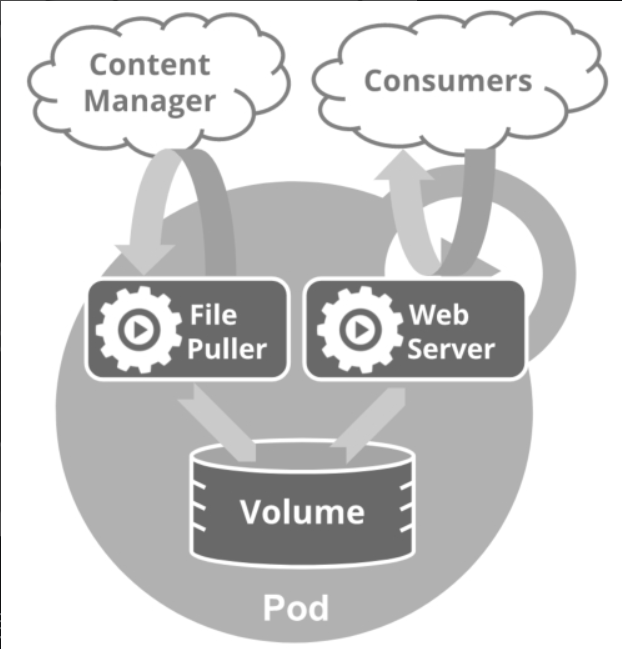
如上图所示,File Puller会定期从外部的Content Manager中拉取最新的文件,将其存放在共享的volume中。Web Server从volume读取文件,响应Consumer的请求。
这两个容器是紧密协作的,它们一起为Consumer提供最新的数据;同时它们也通过volume共享数据,所以放到一个Pod是合适的。
再比如是否需要把Tomcat和MySQL放到一个Pod中?
答案是没必要,虽然Tomcat是从MySQL读取数据,它们之间需要协作,但还不至于需要放到一个Pod中一起部署、一起启动、一起停止。同时它们之间是通过JDBC交换数据,并不是直接共享存储,所以放到各自的Pod中更合适。
Controller
Kubernetes通常不会直接创建Pod,而是通过Controller来管理Pod的。Controller中定义了Pod的部署特性,比如有几个副本、在什么样的Node上运行等。为了满足不同的业务场景,Kubernetes提供了多种Controller,包括Deployment、ReplicaSet、DaemonSet、StatefuleSet、Job等,
- Deployment是最常用的Controller,比如之前教程中就是通过创建Deployment来部署应用的。Deployment可以管理Pod的多个副本,并确保Pod按照期望的状态运行。
- ReplicaSet实现了Pod的多副本管理。使用Deployment时会自动创建ReplicaSet,也就是说Deployment是通过ReplicaSet来管理Pod的多个副本的,我们通常不需要直接使用ReplicaSet。
- DaemonSet用于每个Node最多只运行一个Pod副本的场景。正如其名称所揭示的,DaemonSet通常用于运行daemon。
- StatefuleSet能够保证Pod的每个副本在整个生命周期中名称是不变的,而其他Controller不提供这个功能。当某个Pod发生故障需要删除并重新启动时,Pod的名称会发生变化,同时StatefuleSet会保证副本按照固定的顺序启动、更新或者删除。
- Job用于运行结束就删除的应用,而其他Controller中的Pod通常是长期持续运行。
Service
Deployment可以部署多个副本,每个Pod都有自己的IP,外界如何访问这些副本呢?
是通过Pod的ip吗?我们知道Pod很可能会被频繁地销毁和重启,它们的IP会发生变化,用IP来访问不太现实。这就要用到Service了;
Kubernetes Service定义了外界访问一组特定Pod的方式。Service有自己的IP和端口,Service为Pod提供了负载均衡。
Kubernetes运行容器(Pod)与访问容器(Pod)这两项任务分别由Controller和Service执行。
NameSpace
如果有多个用户或项目组使用同一个Kubernetes Cluster,如何将他们创建的Controller、Pod等资源分开呢?答案就是Namespace。Namespace可以将一个物理的Cluster逻辑上划分成多个虚拟Cluster,每个Cluster就是一个Namespace。不同Namespace里的资源是完全隔离的。
Kubernetes默认创建了两个Namespace,
default:创建资源时如果不指定,将被放到这个Namespace中。
kube-system:Kubernetes自己创建的系统资源将放到这个Namespace中。
这里的实验环境是腾讯云的k8s集群, 云平台的托管集群就是master节点我们不管了, 云平台会负责好, 需要的机器和配置都给他们搞;
我们把自己的已经买过的机器或者新买的机器加入到集群里面, 自己使用即可;
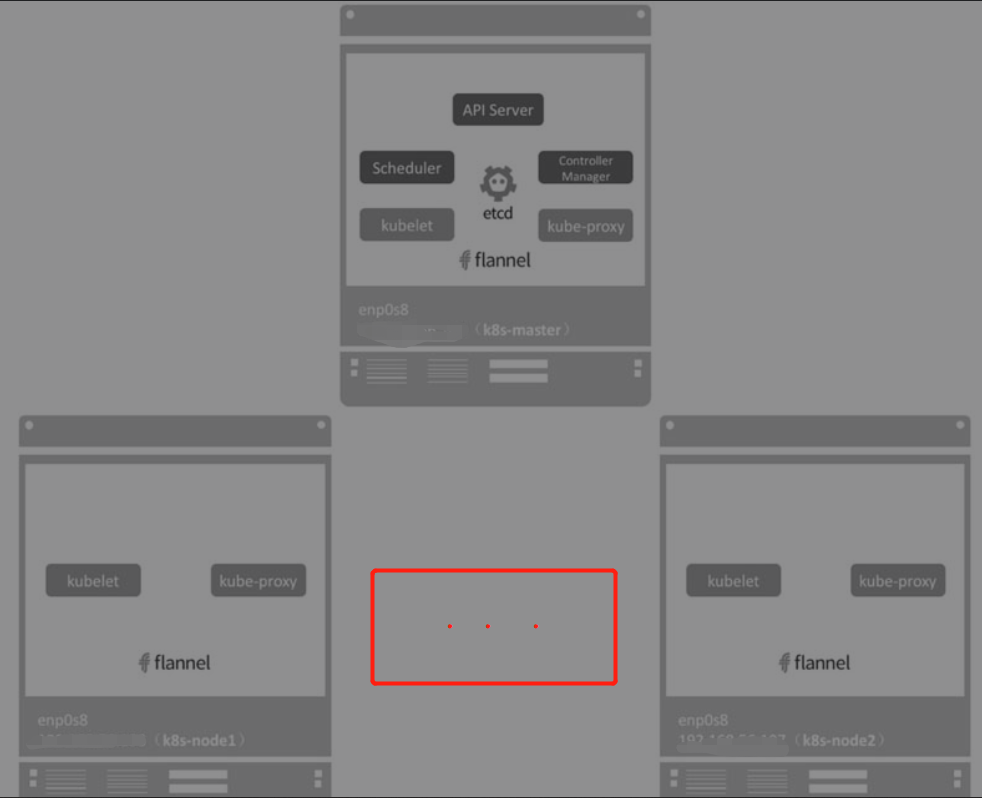
Kubernetes架构
Kubernetes Cluster由Master和Node组成,节点上运行着若干Kubernetes服务。
Master节点
Master是Kubernetes Cluster的大脑,运行着的Daemon服务包括kube-apiserver、kube-scheduler、kube-controller-manager、etcd和Pod网络(例如flannel, calico等)
API Server(kube-apiserver)
API Server提供HTTP/HTTPS RESTful API,即Kubernetes API。API Server是Kubernetes Cluster的前端接口,各种客户端工具(CLI或UI)以及Kubernetes其他组件可以通过它管理Cluster的各种资源。
Scheduler(kube-scheduler)
Scheduler负责决定将Pod放在哪个Node上运行。Scheduler在调度时会充分考虑Cluster的拓扑结构,当前各个节点的负载,以及应用对高可用、性能、数据亲和性的需求。
Controller Manager(kube-controller-manager)
Controller Manager负责管理Cluster各种资源,保证资源处于预期的状态。Controller Manager由多种controller组成,包括replication controller、endpoints controller、namespace controller、serviceaccounts controller等。不同的controller管理不同的资源。例如,replication controller管理Deployment、StatefulSet、DaemonSet的生命周期,namespace controller管理Namespace资源。
etcd
etcd负责保存Kubernetes Cluster的配置信息和各种资源的状态信息。当数据发生变化时,etcd会快速地通知Kubernetes相关组件。
Pod网络
Pod要能够相互通信,Kubernetes Cluster必须部署Pod网络,flannel就是其中一个可选方案。
上面大致就是Master上运行的组件,下面来讨论一下Node节点;
Node节点
Node是Pod运行的地方,Kubernetes支持Docker、rkt等容器Runtime。Node上运行的Kubernetes组件有kubelet、kube-proxy和Pod网络(例如flannel)。
kubelet
kubelet是Node的agent,当Scheduler确定在某个Node上运行Pod后,会将Pod的具体配置信息(image、volume等)发送给该节点的kubelet,kubelet根据这些信息创建和运行容器,并向Master报告运行状态。
kube-proxy
service在逻辑上代表了后端的多个Pod,外界通过service访问Pod。service接收到的请求是如何转发到Pod的呢?这就是kube-proxy要完成的工作。
每个Node都会运行kube-proxy服务,它负责将访问service的TCP/UPD数据流转发到后端的容器。如果有多个副本,kube-proxy会实现负载均衡。
Pod网络
Pod要能够相互通信,Kubernetes Cluster必须部署Pod网络,flannel是其中一个可选方案。
我们注意到k8s-master上也有kubelet和kube-proxy, 这是因为Master上也可以运行应用,即Master同时也是一个Node。
几乎所有的Kubernetes组件本身也运行在Pod里,执行如下命令,结果如图所示。
实验环境架构
kubernetes实验集群:
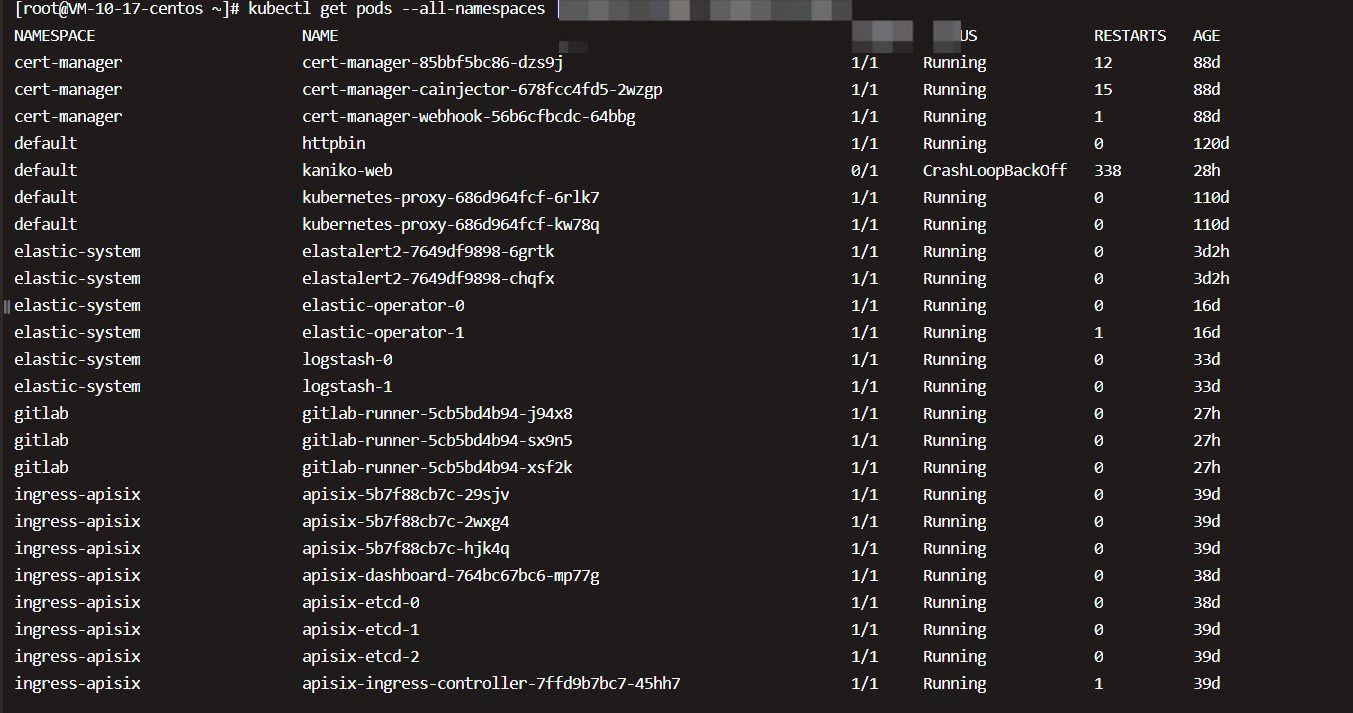
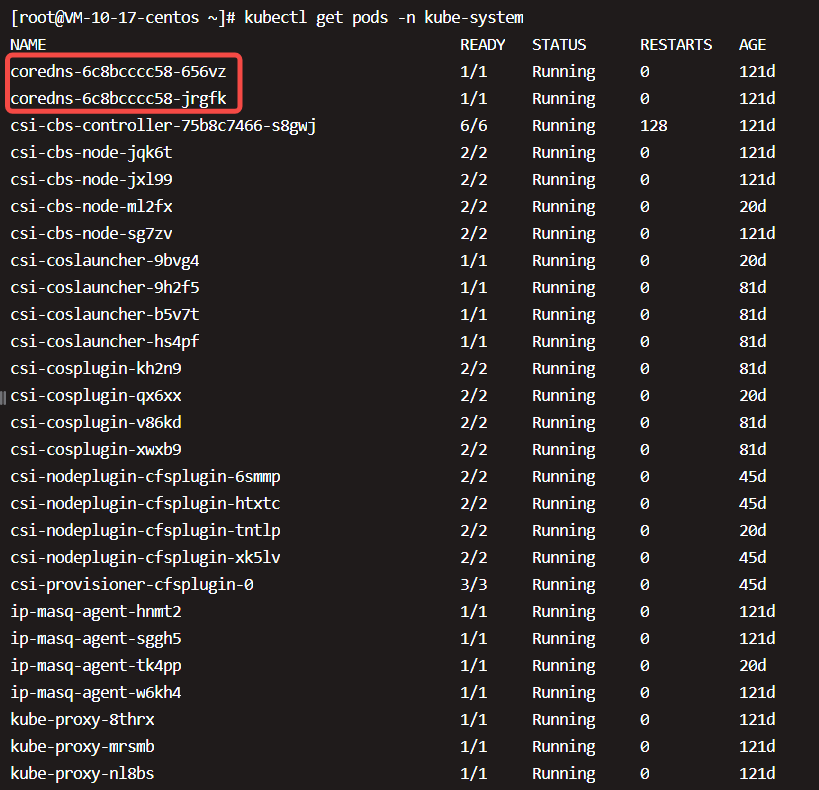
Kubernetes的系统组件都被放到kube-system namespace中。这里有一个core-dns组件 (不再是kube-dns, 在Kubernetes 1.11中,CoreDNS已达到基于DNS的服务发现的通用可用性(GA),可以替代kube-dns插件。这意味着CoreDNS将作为各种安装工具的即将发布版本中的一个选项提供。实际上,kubeadm团队选择将其设为从Kubernetes 1.11开始的默认选项),它为Cluster提供DNS服务;
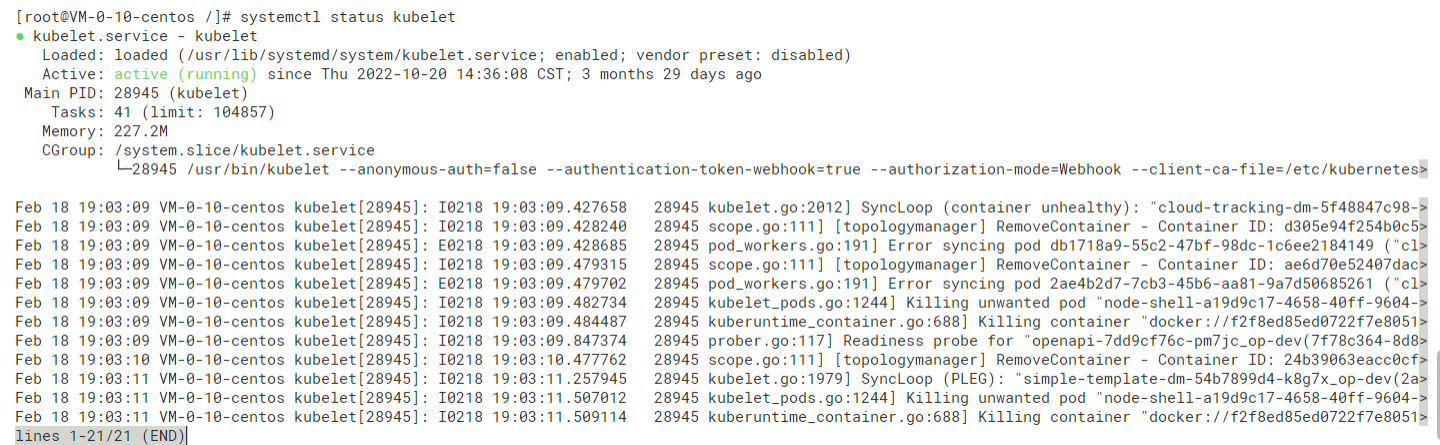
kubelet是唯一没有以容器形式运行的Kubernetes组件,它在Ubuntu中通过Systemd服务运行;
示例演示
为了学习更好的理解Kubernetes架构,我们部署一个应用来演示各个组件之间是如何协作的。
|
|
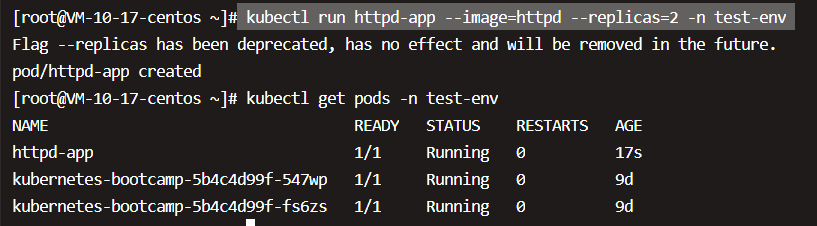
note: 在K8S v1.18.0以后,–replicas已弃用 ,推荐用 deployment 创建 pods;
删掉, 用yaml的文件的方式创建服务;

下面的nginx.yaml的内容如下:
|
|
创建pod:

查看pod:
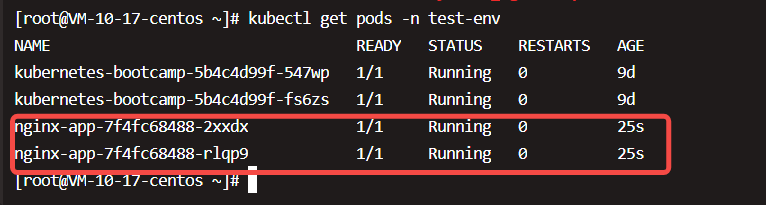

暴露服务:
kubectl expose deployment nginx-app --port=80 --type=LoadBalancer

查看服务状态(查看对外的端口)

在对应节点上,curl命令可以访问验证:
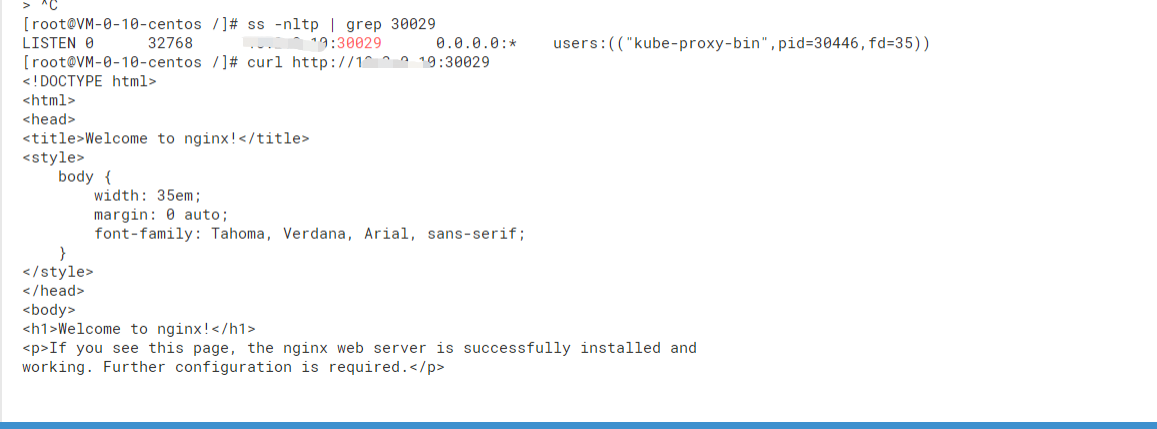
此时, Kubernetes部署了deployment nginx-app,有两个副本Pod,分别运行在k8s-node1和k8s-node2。
总结一下过程:
- kubectl发送部署请求到API Server。
- API Server通知Controller Manager创建一个deployment资源。
- Scheduler执行调度任务,将两个副本Pod分发到k8s-node1和k8s-node2。
- k8s-node1和k8s-node2上的kubectl在各自的节点上创建并运行Pod。
补充两点:
(1)应用的配置和当前状态信息保存在etcd中,执行kubectl get pod时API Server会从etcd中读取这些数据。
(2)flannel会为每个Pod都分配IP。