数据管理
这一节会讨论Kubernetes如何管理存储资源。
首先来学习Volume,以及Kubernetes如何通过Volume为集群中的容器提供存储;然后我们会实践几种常用的Volume类型并理解它们各自的应用场景;
最后,我们会讨论Kubernetes如何通过Persistent Volume和Persistent Volume Claim分离集群管理员与集群用户的职责,并实践Volume的静态供给和动态供给。
Volume
这节会看下Kubernetes的存储模型Volume,学习如何将各种持久化存储映射到容器。
我们经常会说:容器和Pod是短暂的。其含义是它们的生命周期可能很短,会被频繁地销毁和创建。容器销毁时,保存在容器内部文件系统中的数据都会被清除。
为了持久化保存容器的数据,可以使用Kubernetes Volume。Volume的生命周期独立于容器,Pod中的容器可能被销毁和重建,但Volume会被保留。
本质上,Kubernetes Volume是一个目录,这一点与Docker Volume类似。当Volume被mount到Pod,Pod中的所有容器都可以访问这个Volume。Kubernetes Volume也支持多种backend类型,包括emptyDir、hostPath、GCE Persistent Disk、AWS Elastic Block Store、NFS、Ceph等,完整列表可参考https://kubernetes.io/docs/concepts/storage/volumes/#types-of-volumes。
Volume提供了对各种backend的抽象,容器在使用Volume读写数据的时候不需要关心数据到底是存放在本地节点的文件系统中还是云硬盘上。对它来说,所有类型的Volume都只是一个目录。
我们将从最简单的emptyDir开始学习Kubernetes Volume。
emptyDir
emptyDir是最基础的Volume类型。正如其名字所示,一个emptyDir Volume是Host上的一个空目录。
emptyDir Volume对于容器来说是持久的,对于Pod则不是。当Pod从节点删除时,Volume的内容也会被删除。但如果只是容器被销毁而Pod还在,则Volume不受影响。
也就是说:emptyDir Volume的生命周期与Pod一致。Pod中的所有容器都可以共享Volume,它们可以指定各自的mount路径。
下面通过例子来实践emptyDir,
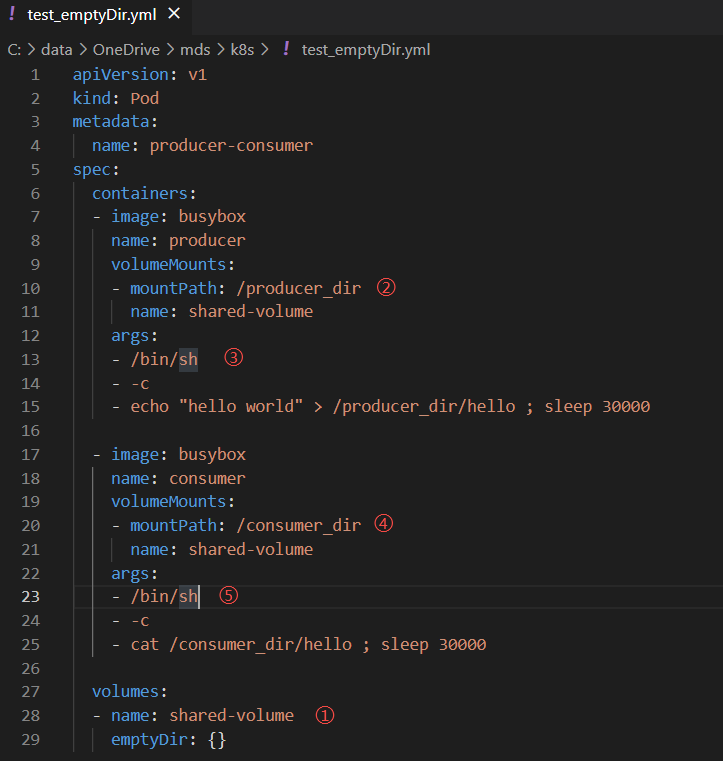
这里我们模拟了一个producer-consumer场景。Pod有两个容器producer和consumer,它们共享一个Volume。producer负责往Volume中写数据,consumer则是从Volume读取数据。
①文件最底部volumes定义了一个emptyDir类型的Volume shared-volume。
②producer容器将shared-volume mount到/producer_dir目录。
③producer通过echo将数据写到文件hello里。
④consumer容器将shared-volume mount到/consumer_dir目录。
⑤consumer通过cat从文件hello读数据。
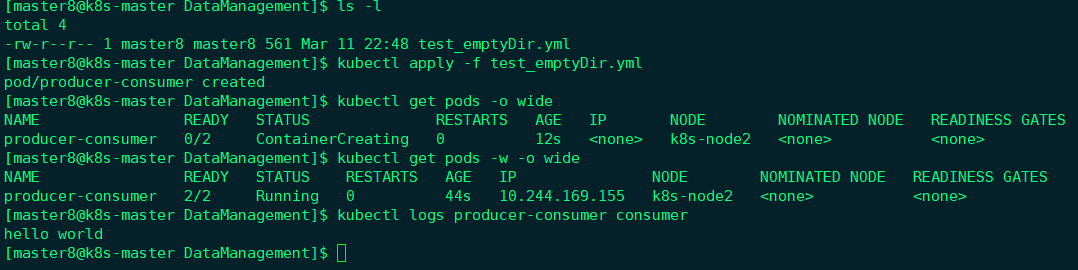
kubectl logs显示容器consumer成功读到了producer写入的数据,验证了两个容器共享emptyDir Volume。
因为emptyDir是Docker Host文件系统里的目录,其效果相当于执行了docker run -v /producer_dir和docker run -v /consumer_dir。通过docker inspect查看容器的详细配置信息,我们发现两个容器都mount了同一个目录,

从查看pod信息这里知道pod被调度到k8s-node2, 登录到这个工作节点





这里的"/var/lib/kubelet/pods/ea341a1f-1eb5-4fcc-9885-33e4bad19ca6/volumes/kubernetes.io~empty-dir/shared-volume"就是emptyDir在Host上的真正路径;
emptyDir是Host上创建的临时目录,其优点是能够方便地为Pod中的容器提供共享存储,不需要额外的配置。它不具备持久性,如果Pod不存在了,emptyDir也就没有了。根据这个特性,emptyDir特别适合Pod中的容器需要临时共享存储空间的场景,比如前面的生产者消费者用例。
hostPath
hostPath Volume的作用是将Docker Host文件系统中已经存在的目录mount给Pod的容器。大部分应用都不会使用hostPath Volume,因为这实际上增加了Pod与节点的耦合,限制了Pod的使用。不过那些需要访问Kubernetes或Docker内部数据(配置文件和二进制库)的应用则需要使用hostPath。
比如kube-apiserver和kube-controller-manager就是这样的应用,通过kubectl edit --namespace=kube-system pod kube-apiserver-k8s-master查看kube-apiserver Pod的配置,
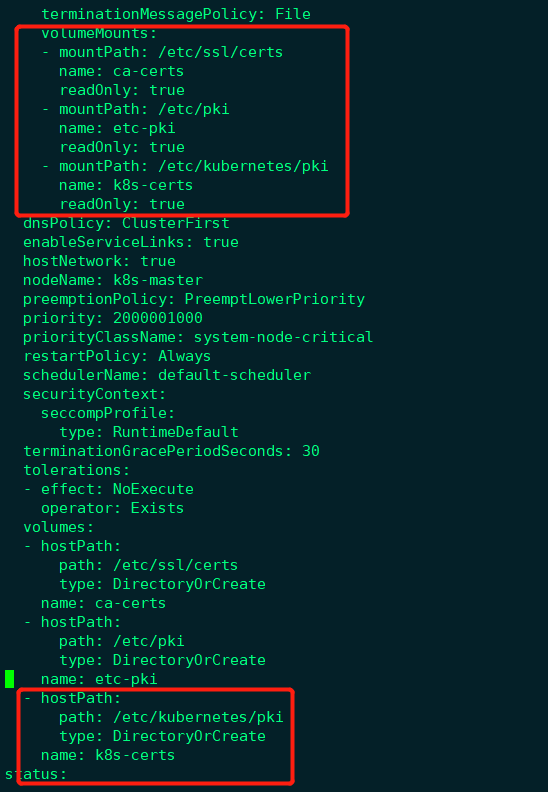
这里定义了三个hostPath:volume k8s、certs和pki,分别对应Host目录/etc/kubernetes、/etc/ssl/certs和/etc/pki。
如果Pod被销毁了,hostPath对应的目录还是会被保留,从这一点来看,hostPath的持久性比emptyDir强。不过一旦Host崩溃,hostPath也就无法访问了。
外部Storage Provider
如果Kubernetes部署在诸如AWS、ALI, GCE、Azure等公有云上,可以直接使用云硬盘作为Volume。
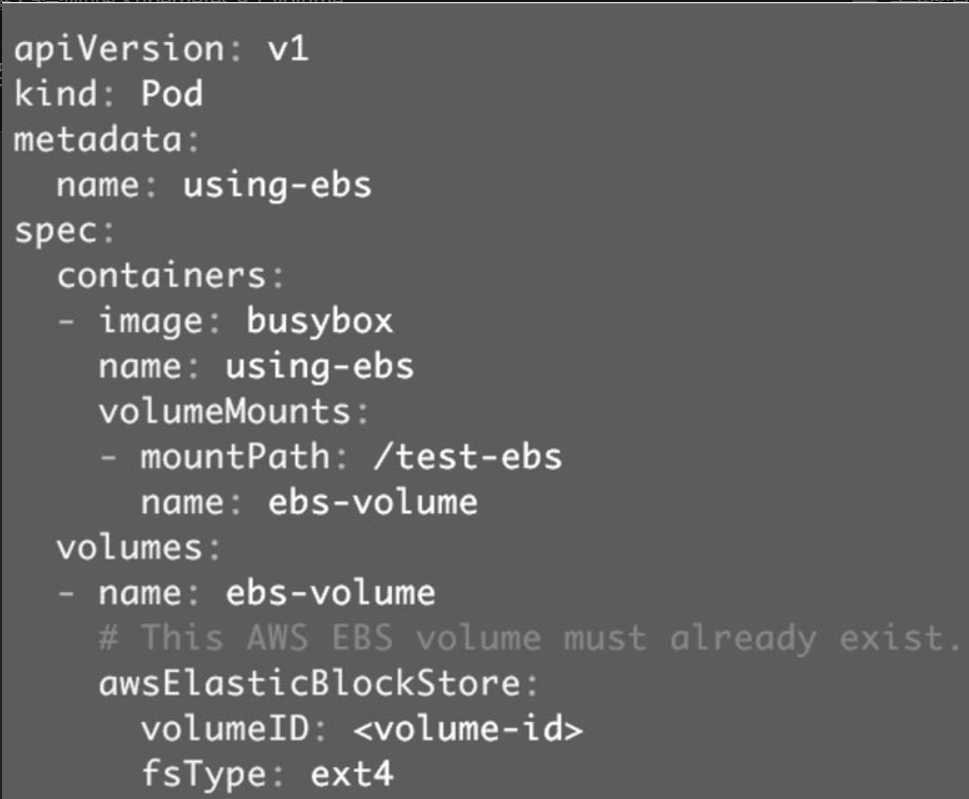
要在Pod中使用ESB volume,必须先在AWS中创建,然后通过volume-id引用。
其他云硬盘的使用方法可参考各公有云厂商的官方文档。
Kubernetes Volume也可以使用主流的分布式存储,比如Ceph、GlusterFS等。下面给出一个Ceph的例子,
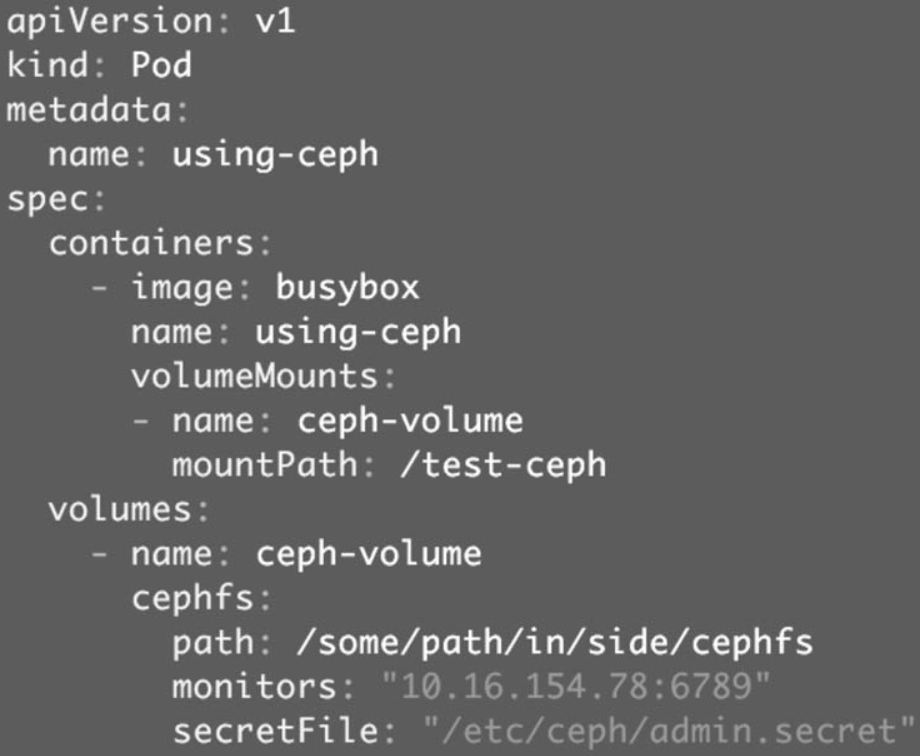
Ceph文件系统的/some/path/in/side/cephfs目录被mount到容器路径/test-ceph。
相对于emptyDir和hostPath,这些Volume类型的最大特点就是不依赖Kubernetes。Volume的底层基础设施由独立的存储系统管理,与Kubernetes集群是分离的。数据被持久化后,即使整个Kubernetes崩溃也不会受损。
当然,运维这样的存储系统通常不是一项简单的工作,特别是对可靠性、可用性和扩展性有较高要求的时候。
PersistentVolume & PersistentVolumeClaim
Volume提供了非常好的数据持久化方案,不过在可管理性上还有不足。
拿前面的AWS EBS例子来说,要使用Volume,Pod必须事先知道如下信息:
(1)当前Volume来自AWS EBS。
(2)EBS Volume已经提前创建,并且知道确切的volume-id。
Pod通常是由应用的开发人员维护,而Volume则通常是由存储系统的管理员维护。开发人员要获得上面的信息,要么询问管理员,要么自己就是管理员。
这样就带来一个管理上的问题:应用开发人员和系统管理员的职责耦合在一起了。如果系统规模较小或者对于开发环境,这样的情况还可以接受,当集群规模变大,特别是对于生成环境,考虑到效率和安全性,这就成了必须要解决的问题。
Kubernetes给出的解决方案是PersistentVolume和PersistentVolumeClaim。
PersistentVolume(PV)是外部存储系统中的一块存储空间,由管理员创建和维护。与Volume一样,PV具有持久性,生命周期独立于Pod。
PersistentVolumeClaim (PVC)是对PV的申请(Claim)。PVC通常由普通用户创建和维护。需要为Pod分配存储资源时,用户可以创建一个PVC,指明存储资源的容量大小和访问模式(比如只读)等信息,Kubernetes会查找并提供满足条件的PV。
有了PersistentVolumeClaim,用户只需要告诉Kubernetes需要什么样的存储资源,而不必关心真正的空间从哪里分配、如何访问等底层细节信息。这些Storage Provider的底层信息交给管理员来处理,只有管理员才应该关心创建PersistentVolume的细节信息。
Kubernetes支持多种类型的PersistentVolume,比如AWS EBS、Ceph、NFS等,完整列表请参考https://kubernetes.io/docs/concepts/storage/persistent-volumes/#types-of-persistent-volumes。
NFS PersistentVolume
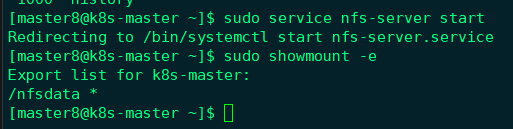
作为准备工作,我们已经在k8s-master节点上搭建了一个NFS服务器,目录为/nfsdata,
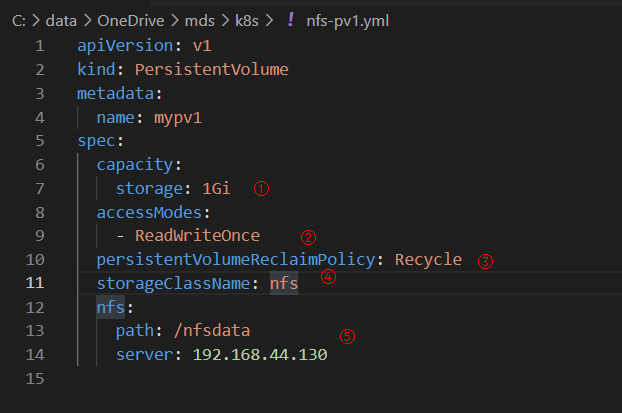
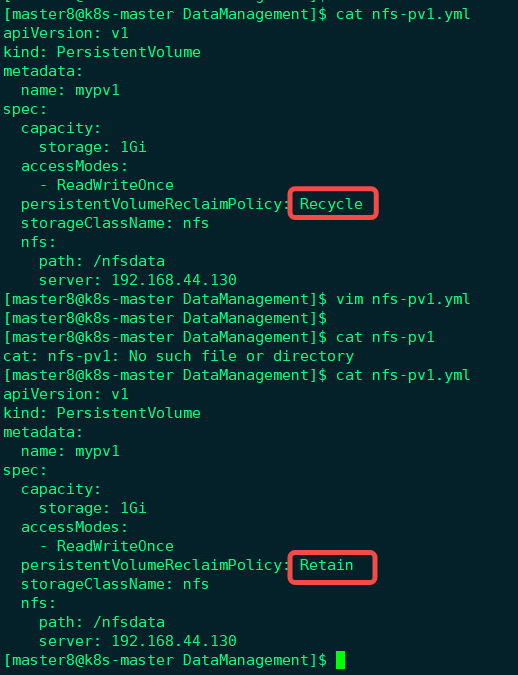
下面创建一个PV mvpv1, 配置文件nfs-pv1.yml如下图所示:
|
|
①capacity指定PV的容量为1GB。
②accessModes指定访问模式为ReadWriteOnce,支持的访问模式有3种:
- ReadWriteOnce表示PV能以read-write模式mount到单个节点,
- ReadOnlyMany表示PV能以read-only模式mount到多个节点,
- ReadWriteMany表示PV能以read-write模式mount到多个节点。
③persistentVolumeReclaimPolicy指定当PV的回收策略为Recycle,支持的策略有3种:
- Retain表示需要管理员手工回收;
- Recycle表示清除PV中的数据,效果相当于执行
rm -rf/thevolume/*; - Delete表示删除Storage Provider上的对应存储资源,例如AWS EBS、GCE PD、Azure Disk、OpenStack Cinder Volume等。
④storageClassName指定PV的class为nfs。相当于为PV设置了一个分类,PVC可以指定class申请相应class的PV。
⑤指定PV在NFS服务器上对应的目录。
创建mypv1,

STATUS为Available,表示mypv1就绪,可以被PVC申请。
接下来创建PVC mypvc1,配置文件nfs-pvc1.yml如下所示:
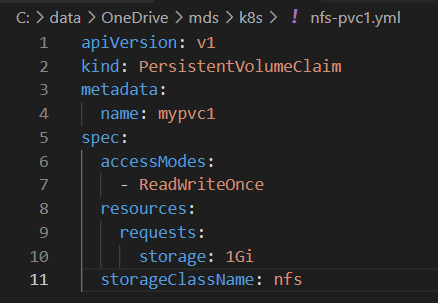
PVC 就很简单了,只需要指定 PV 的容量,访问模式和 class。
执行命令创建mypvc1:
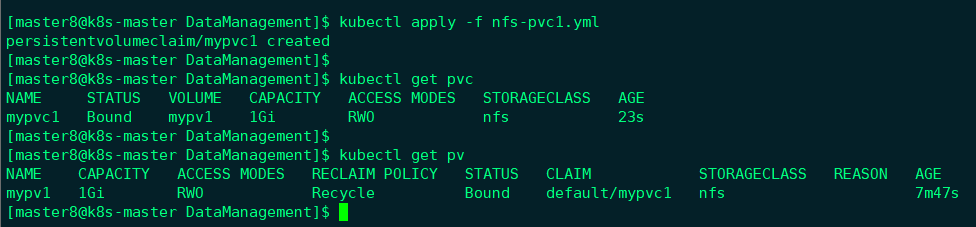
从kubectl get pvc和kubectl get pv的输出可以看到mypvc1已经Bound到mypv1,申请成功。
接下来就可以在Pod中使用存储了,Pod配置文件pod1.yml,
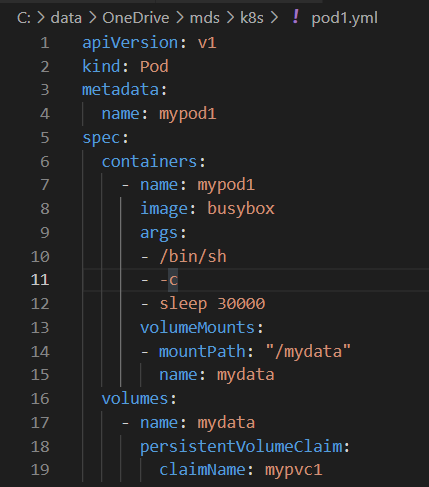
与使用普通Volume的格式类似,在volumes中通过persistentVolumeClaim指定使用mypvc1申请的Volume。
创建mypod1,
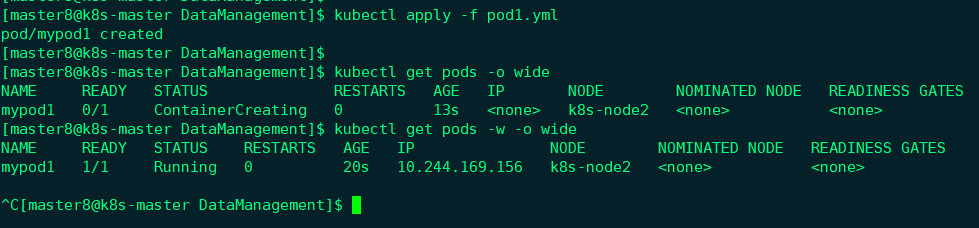
验证PV是否可用:

可见,在Pod中创建的文件/mydata/hello确实已经保存到了NFS服务器目录/nfsdata中。
回收PV
当不需要使用PV时,可用删除PVC回收PV,如图所示。
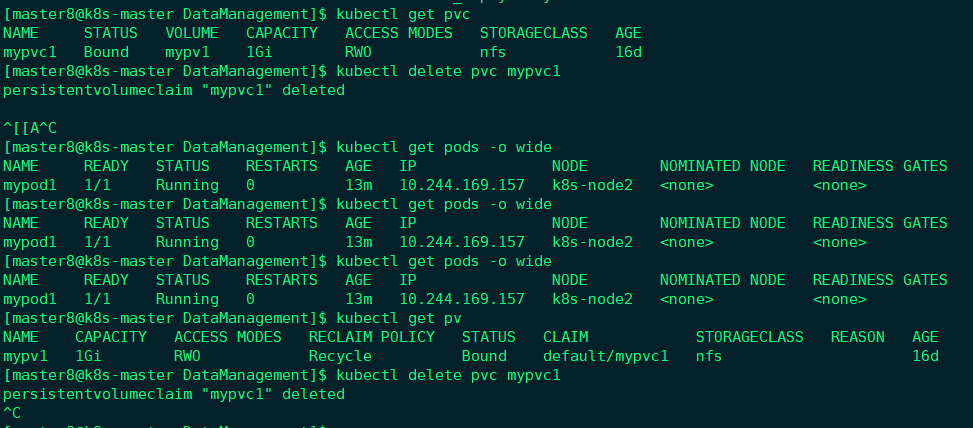
这里,我踩坑了,kubectl delete pvc mypvc1 结果迟迟得不到返回,
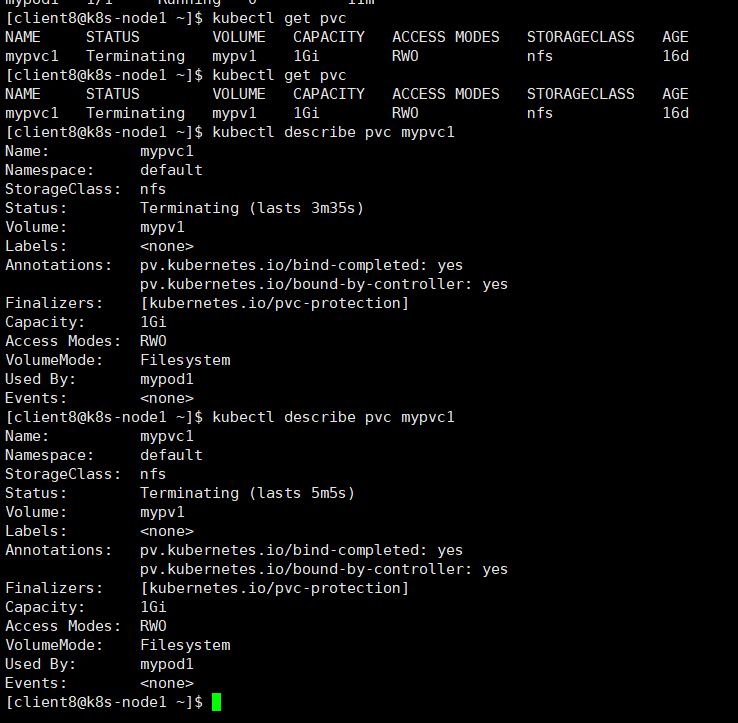
后面只好删除Pod, 后面pvc也自然的删除了, 这里有懂的小伙伴, 也可以告诉我下。

按照书上, 正常逻辑应该是:
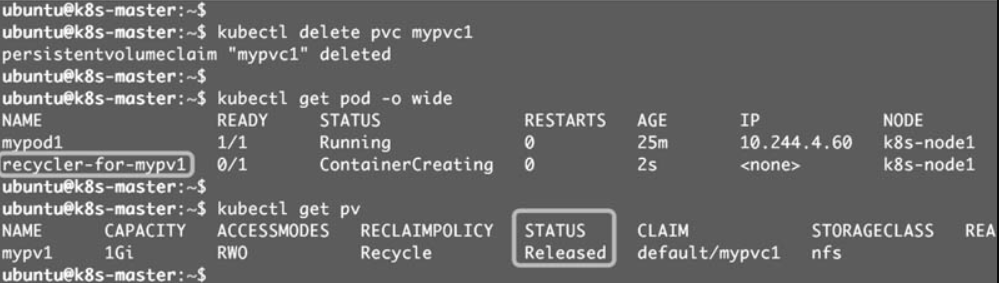
当PVC mypvc1被删除后,会发现Kubernetes启动了一个新Pod recycler-for-mypv1,这个Pod的作用就是清除PV mypv1的数据。
此时mypv1的状态为Released,表示已经解除了与mypvc1的Bound,正在清除数据,不过此时还不可用。
当数据清除完毕,mypv1的状态重新变为Available,此时可以被新的PVC申请,

/nfsdata/pv1中的hello文件已经被删除了。因为PV的回收策略设置为Recycle,所以数据会被清除,但这可能不是我们想要的结果。
如果我们希望保留数据,可以将策略设置为Retain,
通过kubectl apply 更新PV:
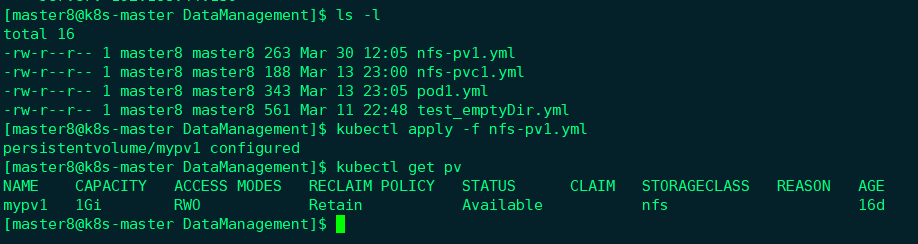
此时我们可以看到回收策略已经变成Retain, 通过下面的步骤来验证其效果:
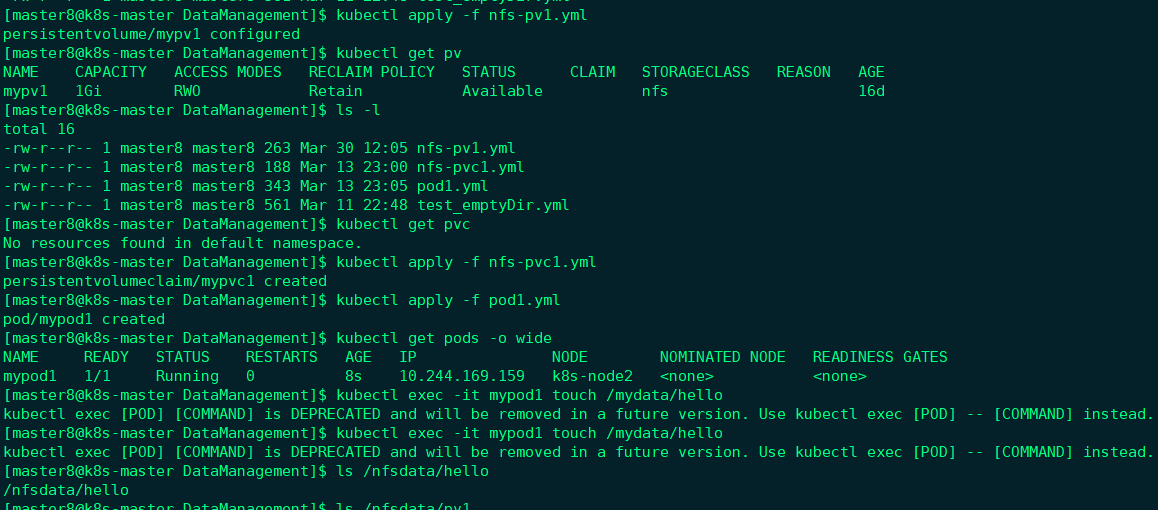
这里也无法模拟进行下去, 删除mypvc1又卡住了;
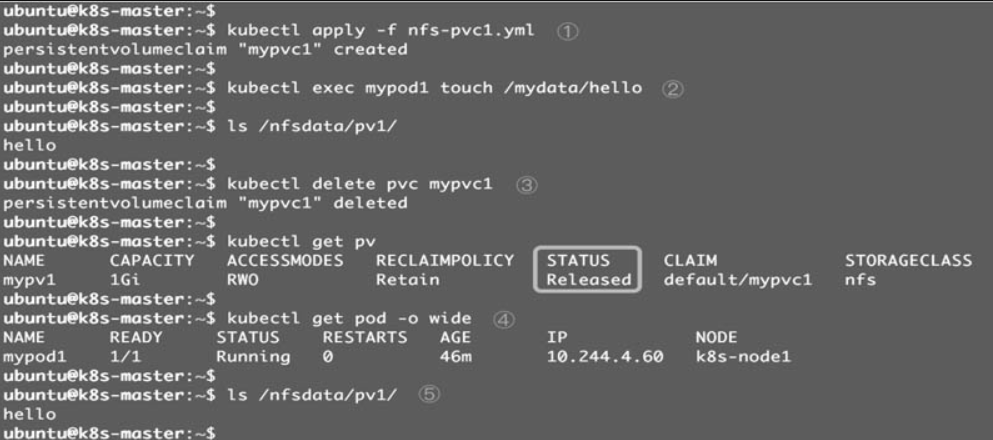
①重新创建mypvc1。
②在mypv1中创建文件hello。
③mypv1状态变为Released。
④Kubernetes并没有启动Pod recycler-for-mypv1。
⑤PV中的数据被完整保留。
虽然mypv1中的数据得到了保留,但其PV状态会一直处于Released,不能被其他PVC申请。为了重新使用存储资源,可以删除并重新创建mypv1。删除操作只是删除了PV对象,存储空间中的数据并不会被删除。新建的mypv1状态为Available,
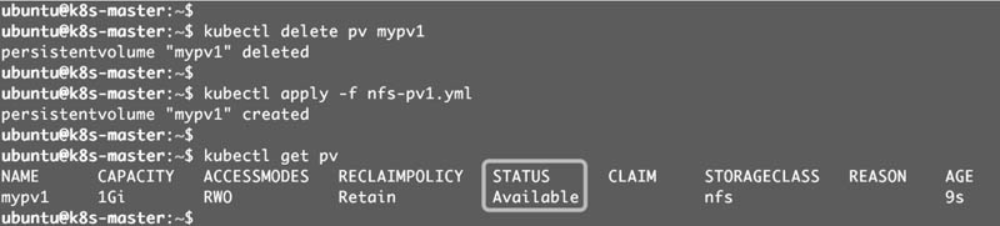
PV还支持Delete的回收策略,会删除PV在Storage Provider上对应的存储空间。NFS的PV不支持Delete,支持Delete的Provider有AWS EBS、GCE PD、Azure Disk、OpenStack Cinder Volume等。
PV动态供给
在前面的例子中,我们提前创建了PV,然后通过PVC申请PV并在Pod中使用,这种方式叫作静态供给(Static Provision)。
与之对应的是动态供给(Dynamical Provision),即如果没有满足PVC条件的PV,会动态创建PV。相比静态供给,动态供给有明显的优势:不需要提前创建PV,减少了管理员的工作量,效率高。动态供给是通过StorageClass实现的,StorageClass定义了如何创建PV,下面给出两个例子。
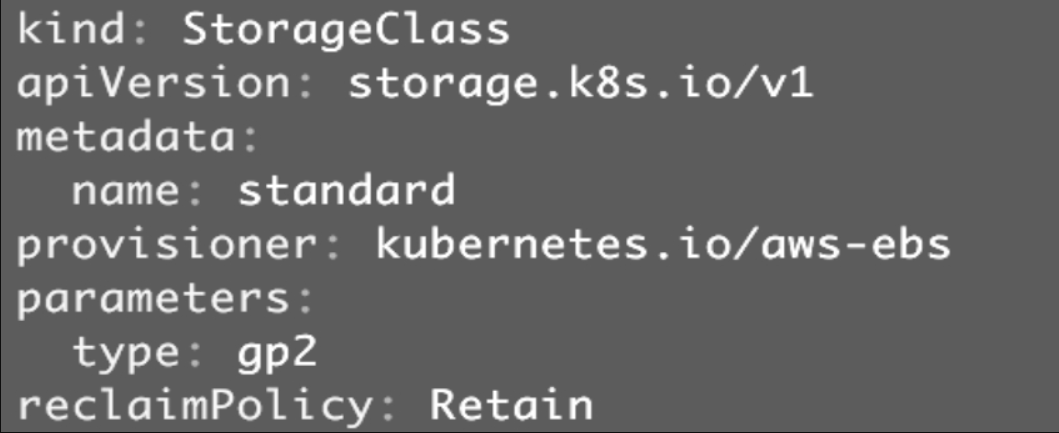
- StorageClass standard
- StorageClass slow
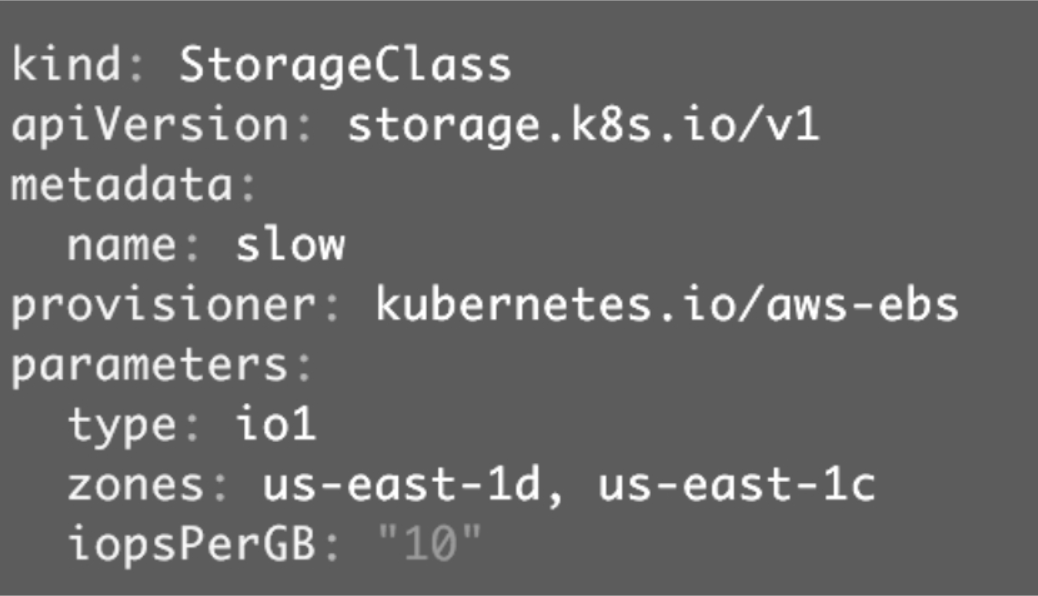
这两个StorageClass都会动态创建AWS EBS,不同点在于standard创建的是gp2类型的EBS,而slow创建的是io1类型的EBS。
不同类型的EBS支持的参数可参考AWS官方文档。
StorageClass支持Delete和Retain两种reclaimPolicy,默认是Delete。
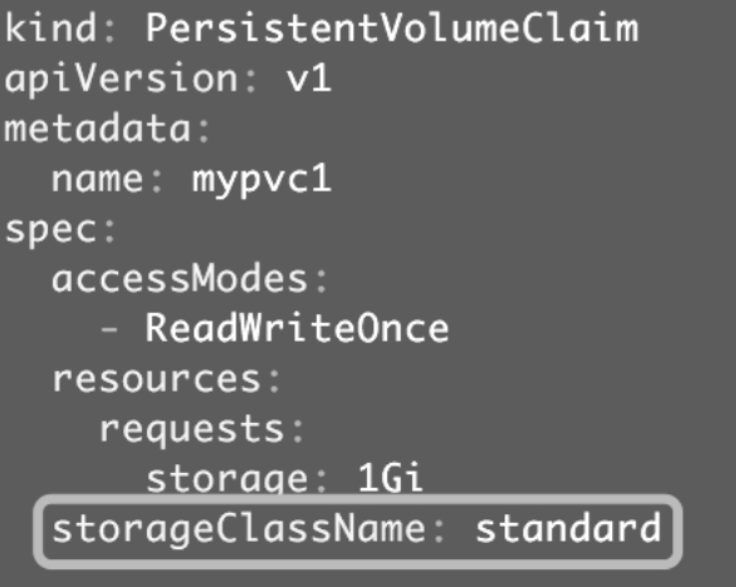
与之前一样,PVC在申请PV时,只需要指定StorageClass、容量以及访问模式即可,如图所示。
除了AWS EBS,Kubernetes还支持其他多种动态供给PV的Provisioner,完整列表请参考K8S Storage Class Provisioner列表。
Secret & Configmap
应用启动过程中可能需要一些敏感信息,比如访问数据库的用户名、密码或者密钥。将这些信息直接保存在容器镜像中显然不妥,Kubernetes提供的解决方案是Secret。
Secret会以密文的方式存储数据,避免了直接在配置文件中保存敏感信息。Secret会以Volume的形式被mount到Pod,容器可通过文件的方式使用Secret中的敏感数据;此外,容器也可以环境变量的方式使用这些数据。
Secret可通过命令行或YAML创建。比如希望Secret中包含如下信息:用户名admin 、密码123456。
创建并查看Secret
有四种方法创建Secret:
- 通过–from-literal:
|
|
每个–from-literal对应一个信息条目。
- 通过–from-file:
|
|
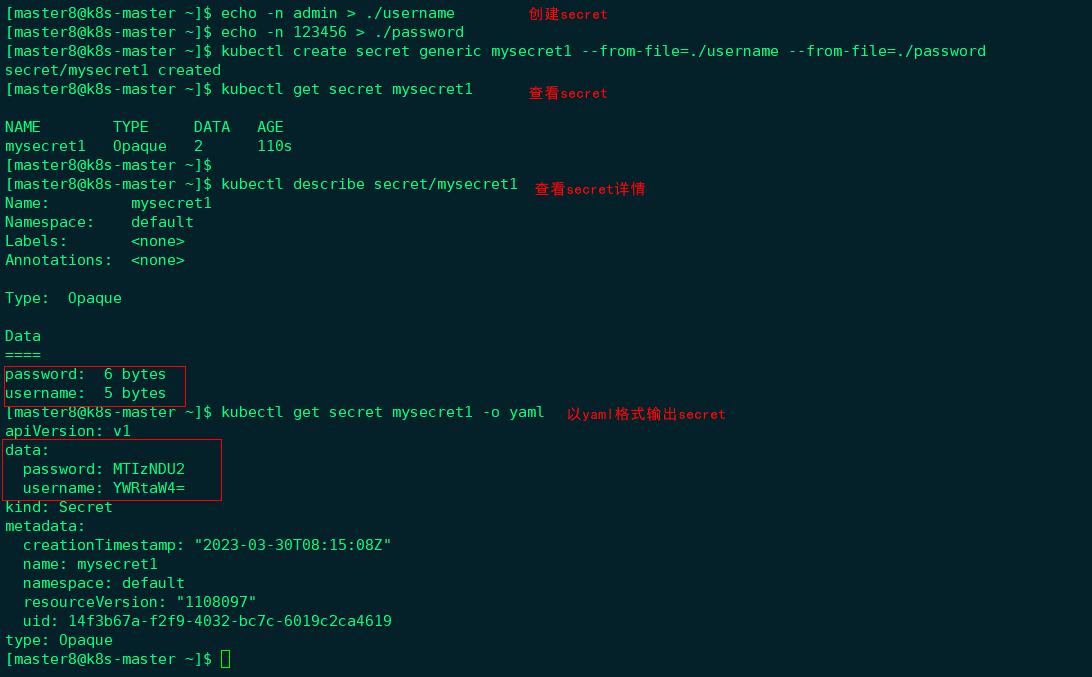
每个文件内容对应一个信息条目。
- 通过–from-env-file:
|
|
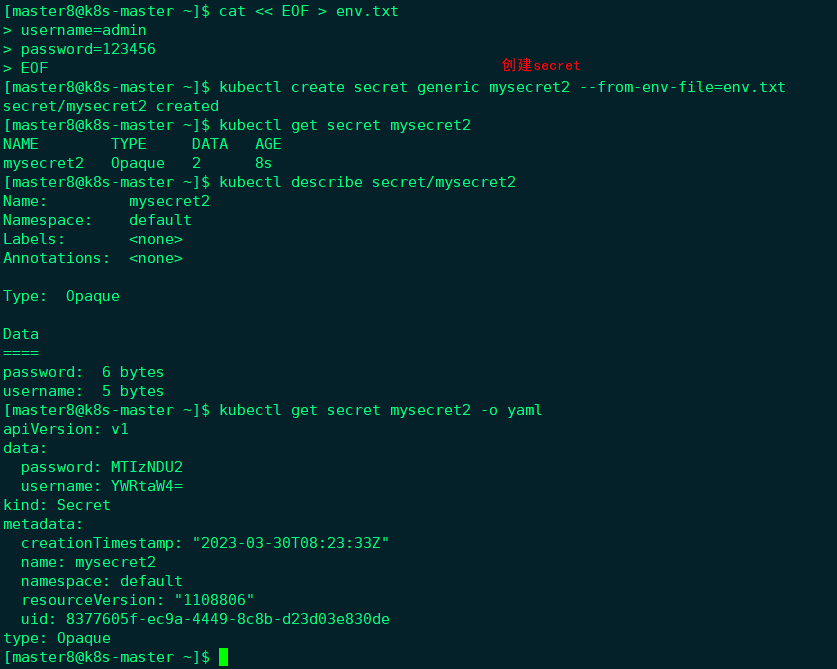
文件env.txt中每行Key=Value对应一个信息条目。
- 通过YAML配置文件:
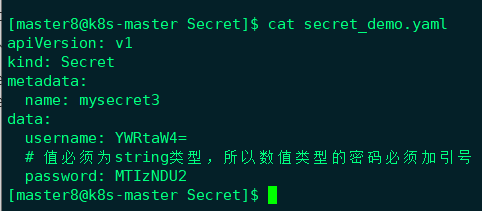
文件中的敏感数据必须是通过base64编码后的结果,
执行kubectl apply来创建Secret:

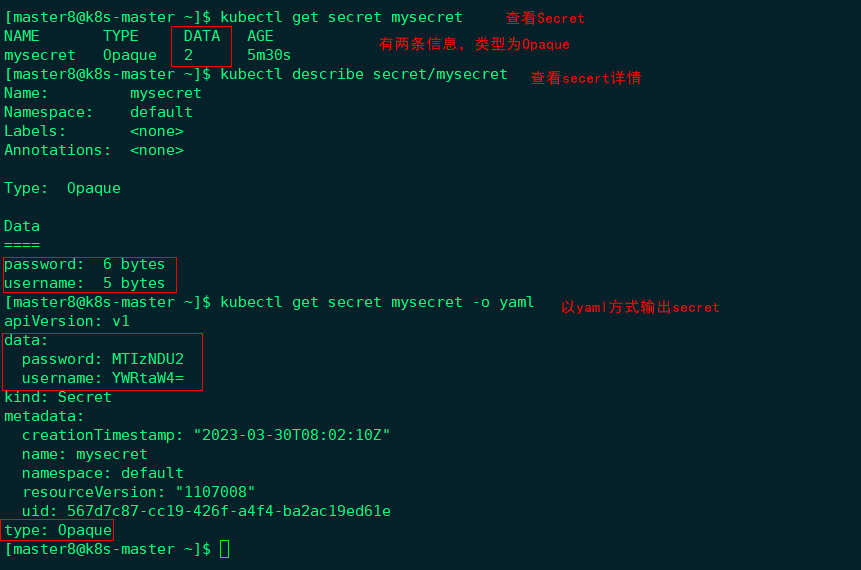
通过kubectl get secret查看存在的secret:
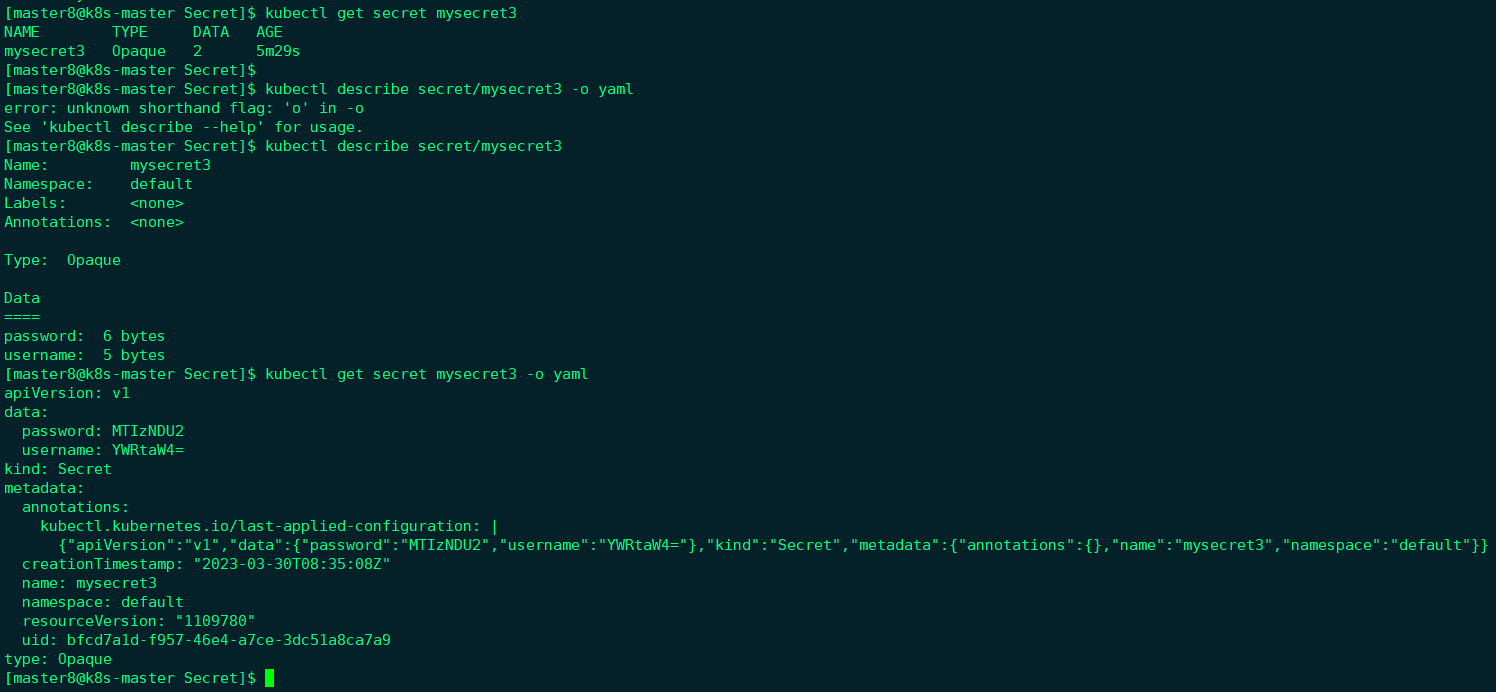
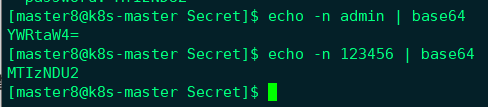
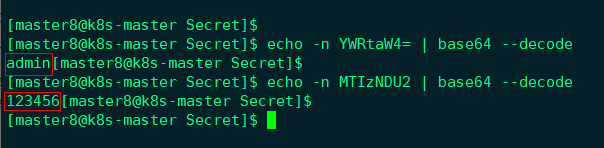
然后通过base64将value反编码,得到如下所示:
Secret Type
创建 Secret 时,你可以使用 Secret 资源的 type 字段, 或者与其等价的 kubectl 命令行参数(如果有的话)为其设置类型。 Secret 的 type 有助于对不同类型机密数据的编程处理。
Kubernetes 提供若干种内置的类型,用于一些常见的使用场景。 针对这些类型,Kubernetes 所执行的合法性检查操作以及对其所实施的限制各不相同。
| 内置类型 | 用法 |
|---|---|
Opaque |
用户定义的任意数据 |
kubernetes.io/service-account-token |
服务账号令牌 |
kubernetes.io/dockercfg |
~/.dockercfg 文件的序列化形式 |
kubernetes.io/dockerconfigjson |
~/.docker/config.json 文件的序列化形式 |
kubernetes.io/basic-auth |
用于基本身份认证的凭据 |
kubernetes.io/ssh-auth |
用于 SSH 身份认证的凭据 |
kubernetes.io/tls |
用于 TLS 客户端或者服务器端的数据 |
bootstrap.kubernetes.io/token |
启动引导令牌数据 |
通过为 Secret 对象的 type 字段设置一个非空的字符串值,你也可以定义并使用自己 Secret 类型。如果 type 值为空字符串,则被视为 Opaque 类型。 Kubernetes 并不对类型的名称作任何限制。不过,如果你要使用内置类型之一, 则你必须满足为该类型所定义的所有要求。
Opaque
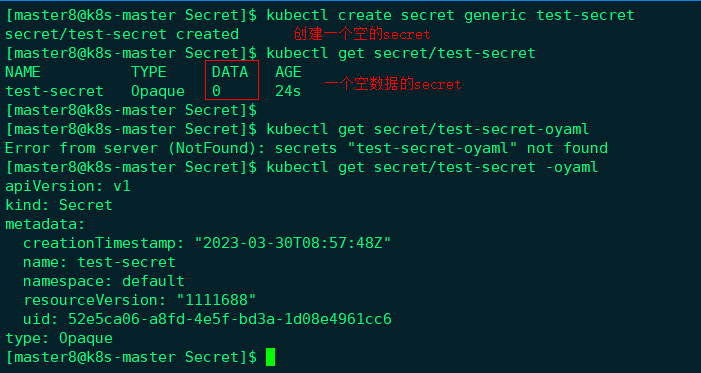
当 Secret 配置文件中未作显式设定时,默认的 Secret 类型是 Opaque。 当你使用 kubectl 来创建一个 Secret 时,你会使用 generic 子命令来标明 要创建的是一个 Opaque 类型 Secret。 例如,下面的命令会创建一个空的 Opaque 类型 Secret 对象:
dockercfg/dockerconfigjson
你可以使用下面两种 type 值之一来创建 Secret,用以存放访问 Docker 仓库 来下载镜像的凭据。
kubernetes.io/dockercfg:旧版的docker login之后会在服务器上生成配置文件~/.dockercfg,用来记录docker仓库的auth信息kubernetes.io/dockerconfigjson:新版的docker login之后会在服务器上生成配置文件~/.docker/config.json,用来记录docker仓库的auth信息
kubernetes.io/dockercfg 是一种保留类型,用来存放 ~/.dockercfg 文件的 序列化形式。该文件是配置 Docker 命令行的一种老旧形式。 使用此 Secret 类型时,你需要确保 Secret 的 data 字段中包含名为 .dockercfg 的主键,其对应键值是用 base64 编码的 ~/.dockercfg 文件的内容。
类型 kubernetes.io/dockerconfigjson 被设计用来保存 JSON 数据的序列化形式, 该 JSON 也遵从 ~/.docker/config.json 文件的格式规则,是 ~/.dockercfg 的新版本格式。 使用此 Secret 类型时,Secret 对象的 data 字段必须包含 .dockerconfigjson 键,其对应键值是用 base64 编码的 ~/.docker/config.json 文件的内容。
下面是一个 kubernetes.io/dockercfg 类型 Secret 的示例:
|
|
|
|
当你使用清单文件来创建这两类 Secret 时,API 服务器会检查 data 字段中是否 存在所期望的主键,并且验证其中所提供的键值是否是合法的 JSON 数据。 不过,API 服务器不会检查 JSON 数据本身是否是一个合法的 Docker 配置文件内容。
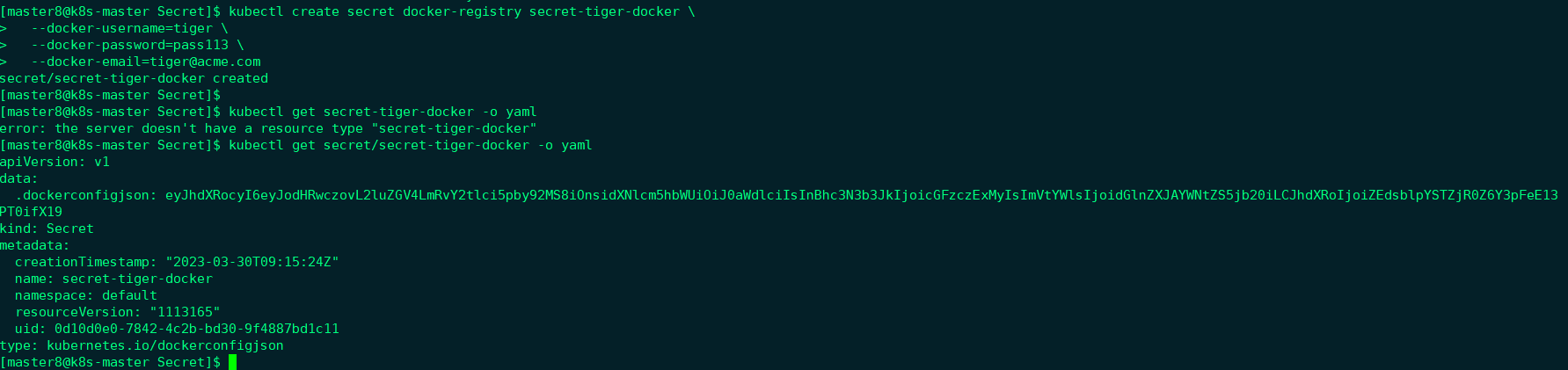
|
|
上面的命令创建一个类型为 kubernetes.io/dockerconfigjson 的 Secret。 如果你对 data 字段中的 .dockerconfigjson 内容进行转储,你会得到下面的 JSON 内容,而这一内容是一个合法的 Docker 配置文件。

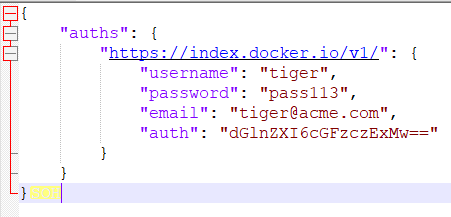
basic-auth
kubernetes.io/basic-auth 类型用来存放用于基本身份认证所需的凭据信息。 使用这种 Secret 类型时,Secret 的 data 字段必须包含以下两个键:
username: 用于身份认证的用户名;password: 用于身份认证的密码或令牌。
以上两个键的键值都是 base64 编码的字符串。 当然你也可以在创建 Secret 时使用 stringData 字段来提供明文形式的内容。 下面的 YAML 是基本身份认证 Secret 的一个示例清单:
|
|
提供基本身份认证类型的 Secret 仅仅是出于用户方便性考虑。 你也可以使用 Opaque 类型来保存用于基本身份认证的凭据。
不过,使用内置的 Secret 类型的有助于对凭据格式进行归一化处理,并且 API 服务器确实会检查 Secret 配置中是否提供了所需要的主键。
ssh-auth
Kubernetes 所提供的内置类型 kubernetes.io/ssh-auth 用来存放 SSH 身份认证中 所需要的凭据。使用这种 Secret 类型时,你就必须在其 data (或 stringData) 字段中提供一个 ssh-privatekey 键值对,作为要使用的 SSH 凭据。
下面的 YAML 是一个 SSH 身份认证 Secret 的配置示例:
|
|
提供 SSH 身份认证类型的 Secret 仅仅是出于用户方便性考虑。 你也可以使用 Opaque 类型来保存用于 SSH 身份认证的凭据。 不过,使用内置的 Secret 类型的有助于对凭据格式进行归一化处理,并且 API 服务器确实会检查 Secret 配置中是否提供了所需要的主键。
注意: SSH 私钥自身无法建立 SSH 客户端与服务器端之间的可信连接。 需要其它方式来建立这种信任关系,以缓解“中间人(Man In The Middle)” 攻击,例如向 ConfigMap 中添加一个 known_hosts 文件。
tls
Kubernetes 提供一种内置的 kubernetes.io/tls Secret 类型,用来存放证书 及其相关密钥(通常用在 TLS 场合)。 此类数据主要提供给 Ingress 资源,用以终结 TLS 链接,不过也可以用于其他 资源或者负载。当使用此类型的 Secret 时,Secret 配置中的 data (或 stringData)字段必须包含 tls.key 和 tls.crt 主键,尽管 API 服务器 实际上并不会对每个键的取值作进一步的合法性检查。
下面的 YAML 包含一个 TLS Secret 的配置示例:
|
|
提供 TLS 类型的 Secret 仅仅是出于用户方便性考虑。 你也可以使用 Opaque 类型来保存用于 TLS 服务器与/或客户端的凭据。 不过,使用内置的 Secret 类型的有助于对凭据格式进行归一化处理,并且 API 服务器确实会检查 Secret 配置中是否提供了所需要的主键。
当使用 kubectl 来创建 TLS Secret 时,你可以像下面的例子一样使用 tls 子命令:
|
|
这里的公钥/私钥对都必须事先已存在。用于 --cert 的公钥证书必须是 .PEM 编码的 (Base64 编码的 DER 格式),且与 --key 所给定的私钥匹配。 私钥必须是通常所说的 PEM 私钥格式,且未加密。对这两个文件而言,PEM 格式数据 的第一行和最后一行(例如,证书所对应的 --------BEGIN CERTIFICATE----- 和 -------END CERTIFICATE----)都不会包含在其中。
在Pod中使用Secret
Pod可以通过Volume或者环境变量的方式使用Secret。
Volume方式
|
|
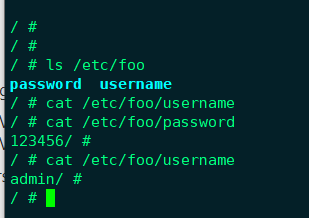
可以看到,Kubernetes会在指定的路径/etc/foo下为每条敏感数据创建一个文件,文件名就是数据条目的Key,这里是/etc/foo/username和/etc/foo/password,Value则以明文存放在文件中。
我们也可以自定义存放数据的文件名,
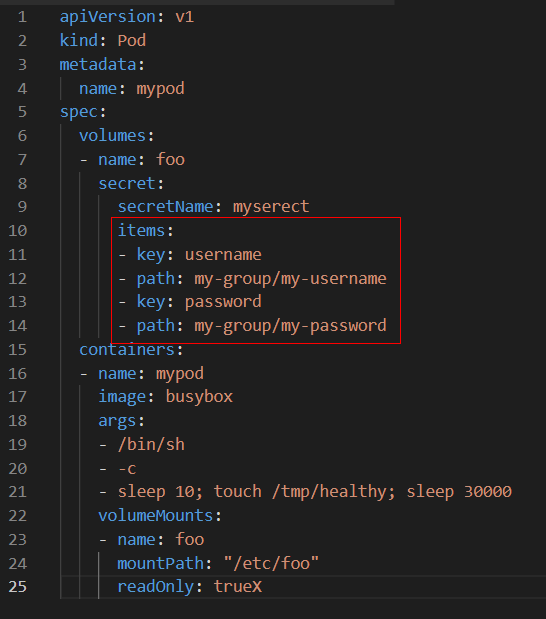
这时数据将分别存放在/etc/foo/my-group/my-username和/etc/foo/my-group/my-password中。
以Volume方式使用的Secret支持动态更新:Secret更新后,容器中的数据也会更新。比如将password更新为abcdef,base64编码为YWJjZGVm,几秒钟后,新的password会同步到容器,。
环境变量方式
通过Volume使用Secret,容器必须从文件读取数据,稍显麻烦,Kubernetes还支持通过环境变量使用Secret。
Pod配置文件示例如下所示:
|
|
创建Pod并读取Secret:
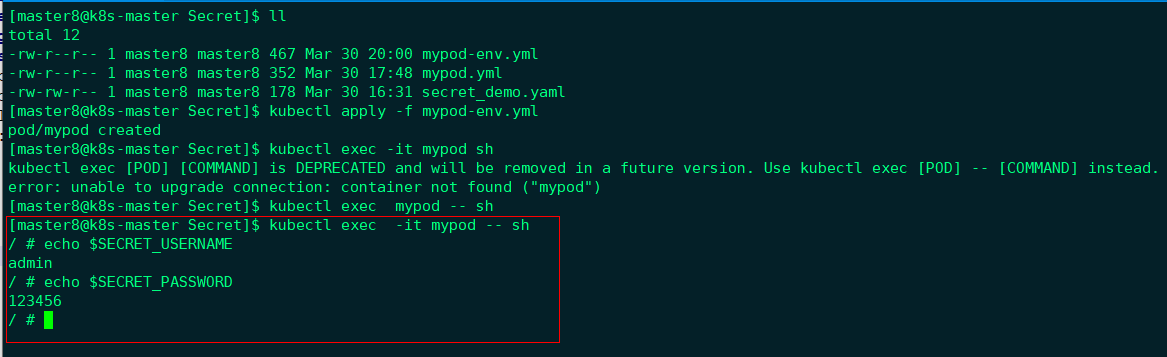
通过环境变量SECRET_USERNAME和SECRET_PASSWORD成功读取到Secret的数据。
需要注意的是,环境变量读取Secret很方便,但无法支撑Secret动态更新。
ConfigMap
Secret可以为Pod提供密码、Token、私钥等敏感数据;
对于一些非敏感数据,比如应用的配置信息,则可以用ConfigMap。ConfigMap的创建和使用方式与Secret非常类似,主要的不同是数据以明文的形式存放。
与Secret一样,ConfigMap也支持四种创建方式:
- 通过–from-literal:
|
|
每个–from-literal对应一个信息条目。
- 通过–from-file:
|
|
每个文件内容对应一个信息条目。
- 通过–from-env-file:
|
|
文件env.txt中每行Key=Value对应一个信息条目。
- 通过YAML配置文件,如图所示。文件中的数据直接以明文输入。
与Secret一样,Pod也可以通过Volume或者环境变量的方式使用Secret。
Volume方式
|
|
|
|
创建configmap并进入pod查看配置:
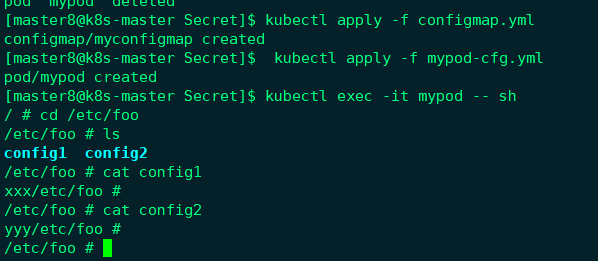
环境变量方式
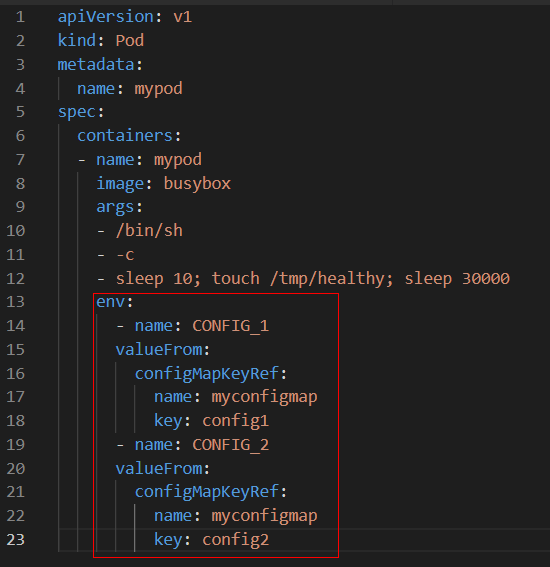
|
|
大多数情况下,配置信息都以文件形式提供,所以在创建ConfigMap时通常采用–from-file或YAML方式,读取ConfigMap时通常采用Volume方式。
来学习一个给Pod传递如何记录日志的配置信息的实践:
|
|
可以采用–from-file形式。将其保存在文件logging.conf中,然后执行命令:
|
|
如果采用YAML配置文件,其内容则如下所示:
|
|
注意,别漏写了Key logging.conf后面的|符号。
创建并查看ConfigMap:
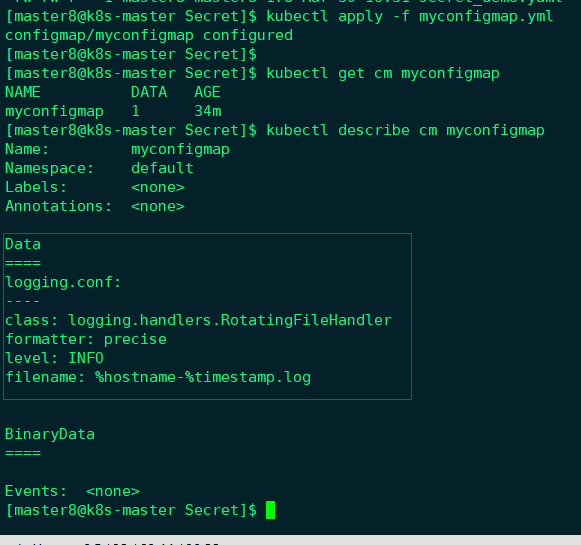
在Pod中使用此ConfigMap, 配置文件如下所示:
|
|
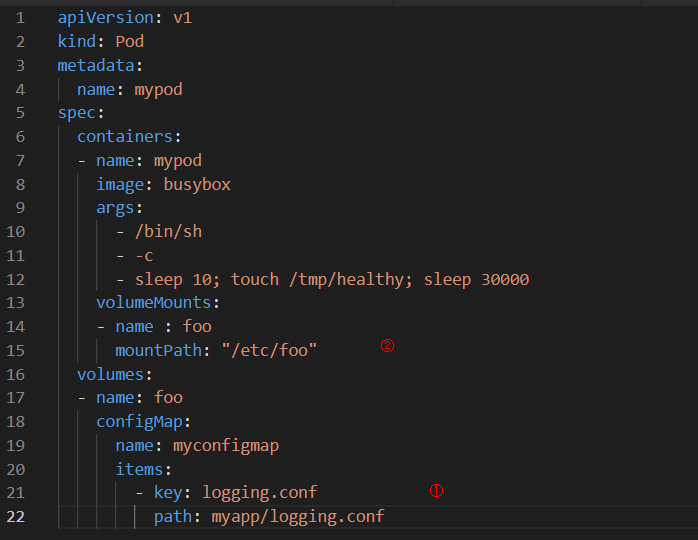
①在volume中指定存放配置信息的文件相对路径为myapp/logging.conf。
②将volume mount到容器的/etc目录。
创建Pod并读取配置信息:
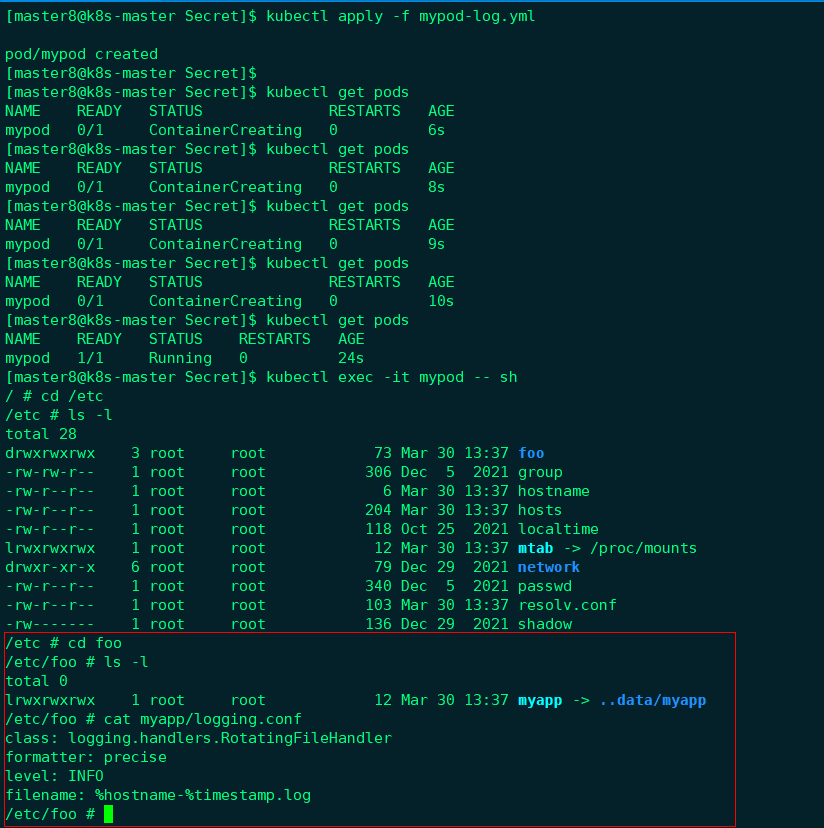
配置信息已经保存到/etc/myapp/logging.conf文件中。与Secret一样,Volume形式的ConfigMap也支持动态更新。
Summary
这一节我们学习了如何向Pod传递配置信息。如果信息需要加密,可使用Secret;如果是一般的配置信息,则可使用ConfigMap。
Secret和ConfigMap支持四种定义方法。
Pod在使用它们时,可以选择Volume方式或环境变量方式,不过只有Volume方式支持动态更新。