我们知道Kubernetes Pod不总是健壮的,而是要假设Pod中的容器很可能因为各种原因发生故障而死掉。Deployment等Controller会通过动态创建和销毁Pod来保证应用整体的健壮性。换句话说,Pod是脆弱的,但应用应该是要健壮的。
每个Pod都有自己的IP地址。当Controller用新Pod替代发生故障的Pod时,新Pod会分配到新的IP地址。这样就产生了一个问题:
如果一组Pod对外提供服务(比如HTTP),它们的IP很有可能发生变化,那么客户端如何找到并访问这个服务呢?
Kubernetes给出的解决方案是Service。
创建Service
Kubernetes Service从逻辑上代表了一组Pod,具体是哪些Pod则是由label来挑选的。Service有自己的IP,而且这个IP是不变的。客户端只需要访问Service的IP,Kubernetes则负责建立和维护Service与Pod的映射关系。无论后端Pod如何变化,对客户端不会有任何影响,因为Service没有变。
|
|

来启动了三个Pod,运行httpd镜像,label是app: httpd,Service将会用这个label来挑选Pod,
Pod分配了各自的IP,这些IP只能被Kubernetes Cluster中的容器和节点访问,
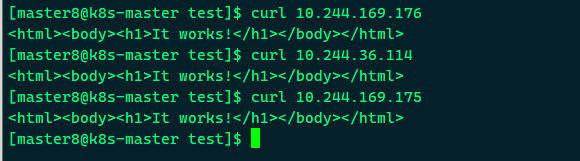
接下来创建Service:
|
|
①v1是Service的apiVersion。
②指明当前资源的类型为Service。
③Service的名字为httpd-svc。
④selector指明挑选那些label为app: httpd的Pod作为Service的后端。
⑤将Service的8080端口映射到Pod的80端口,使用TCP协议。
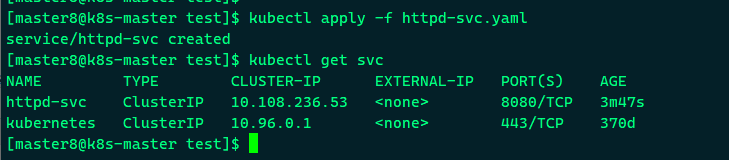
可以看到http-svc分配到一个ClusterIP为10.108.236.53, 可以通过该IP访问后端httpd pod,
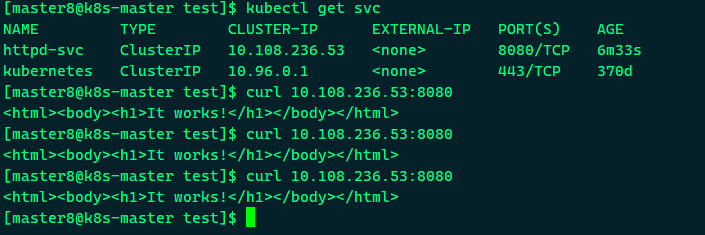
根据前面的端口映射,这里要使用8080端口。另外,除了我们创建的httpd-svc,还有一个Service kubernetes,Cluster内部通过这个Service访问Kubernetes API Server。
通过kubectl describe可以查看httpd-svc与Pod的对应关系,
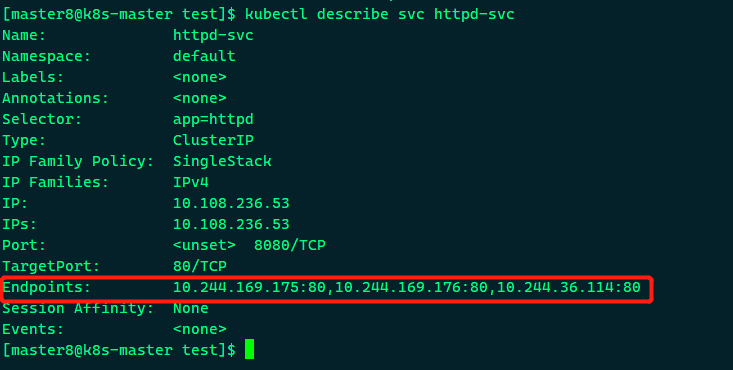
Endpoints罗列了三个Pod的IP和端口。我们知道Pod的IP是在容器中配置的,那么Service的Cluster IP又是配置在哪里的呢?CLUSTER-IP又是如何映射到Pod IP的呢?
其实是iptables.
ClusterIP底层实现
ClusterIP是一个虚拟IP,是由Kubernetes节点上的iptables规则管理的。
可以通过iptables-save命令打印出当前节点的iptables规则,因为输出较多,这里只截取与httpd-svc Cluster IP 10.108.236.53相关的信息,

这两条规则的含义是:
(1)如果Cluster内的Pod(源地址来自10.244.0.0/16)要访问httpd-svc,则允许。
(2)其他源地址访问httpd-svc,跳转到规则KUBE-SVC-IYRDZZKXS5EOQ6Q6。
KUBE-SVC-IYRDZZKXS5EOQ6Q6的规则如下:

(1)1/3的概率跳转到规则KUBE-SEP-N4HQP4BS4JJGDYHG。
(2)1/3的概率(剩下2/3的一半)跳转到规则KUBE-SEP-KS6SRLT6RA7U756F。
(3)1/3的概率跳转到规则KUBE-SEP-TZUHJA6PDPFAF5LY。
上面三个跳转的规则如下:
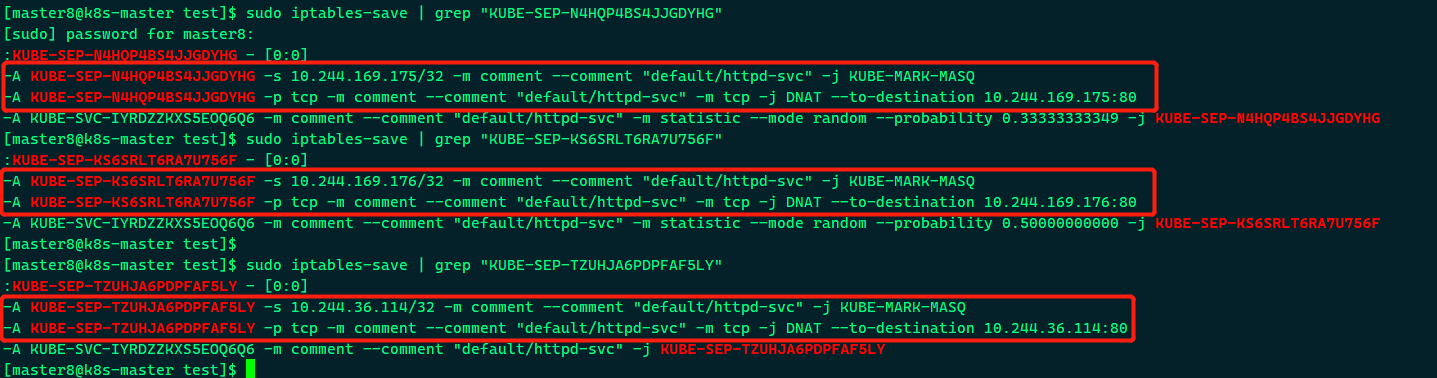
即将请求分别转发到后端的三个Pod。通过上面的分析,我们得到结论:iptables将访问Service的流量转发到后端Pod,而且使用类似轮询的负载均衡策略。
另外补充的一点:Cluster的每一个节点都配置了相同的iptables规则,这样就确保了整个Cluster都能够通过Service的Cluster IP访问Service.
DNS访问Service
在Cluster中,除了可以通过Cluster IP访问Service,Kubernetes还提供了更为方便的DNS访问。
kubeadm部署时会默认安装dns相关组件,
可以把kube-dns认为是一个dns服务器,每当有新的Service被创建,kube-dns会添加该Service的DNS记录。Cluster中的Pod可以通过<SERVICE_NAME>.<NAMESPACE_NAME>访问Service。
比如我们可以用httpd-svc.default访问Service httpd-svc,
以下面的yaml创建一个busybox的pod:
|
|
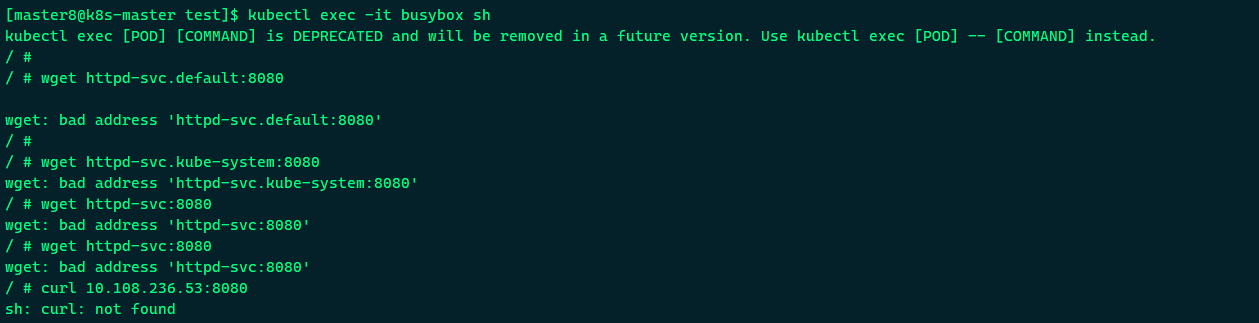
我们希望在一个临时的busybox Pod中验证了DNS的有效性。但是此时不通。
pod不能访问域名问题排查
一时间怀疑了k8s cluster搭建的是否有问题、coredns是不是正常、服务发现等哪里出了纰漏, 冷静分析下可能还是搭建环节少了一些东西, 排查步骤如下:
- 可以确定进入pod, 可以访问IP但不能访问域名
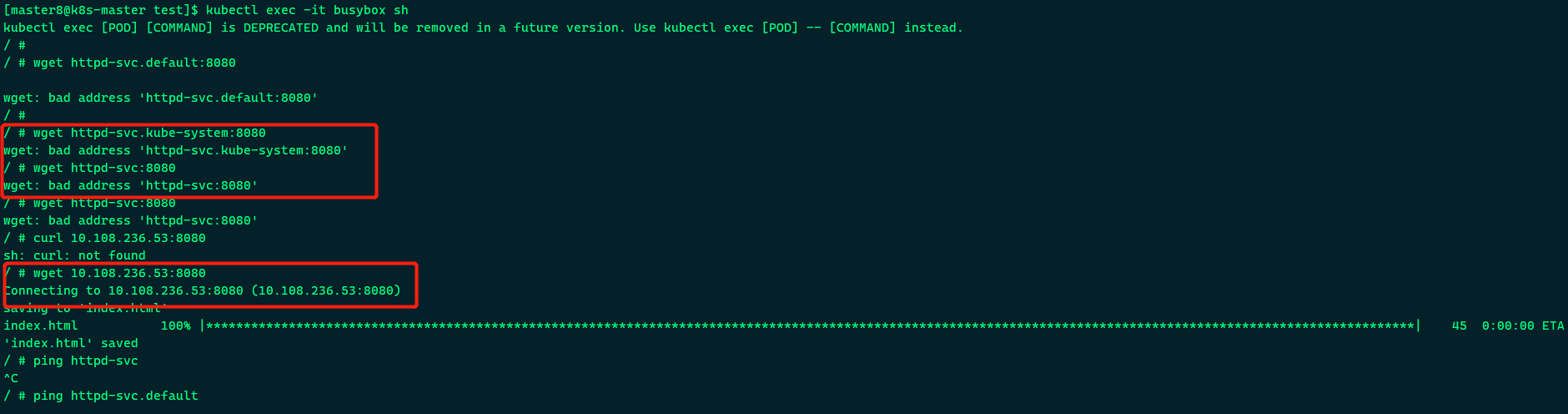
- 进入目标pod容器, 查看/etc/resolv.conf
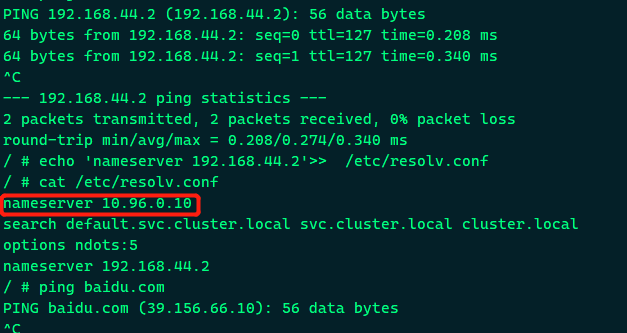
可以看到dns服务器的IP为10.96.0.10, 然后查看k8s的core dns容器的信息

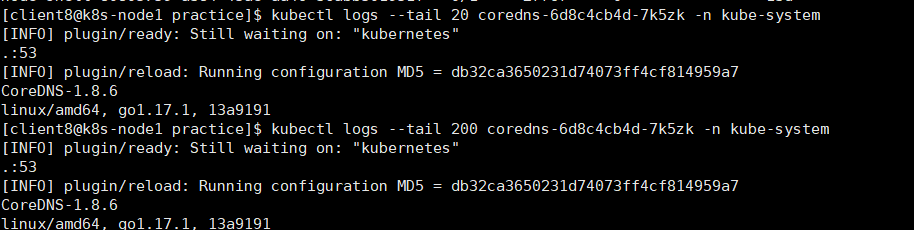
可以看到两个coredns pod位状态是running,日志业务异常情况,应该正常
- 进一步查看dns service的信息

比较奇怪, 这里并没有kube-dns的service, 我们知道kube-dns服务的IP正是10.96.0.10,而且pod是通过kube-dns 服务来解析域名的,现在的问题是POD无法与kube-dns通信呢?还是coredns本身域名解析有问题呢,
先恢复一下kube-dns,
|
|
创建kube-dns service之后,发现pod可以和kube-dns通信, 同时也恢复了pod里面以域名形式访问svc;
仍然来看下kube-dns服务后端是否正确绑定了coredns容器, 查看endpoint来确认:

可以看到kube-dns后端正确的绑定了两个coredns pod的IP。
此时再执行ping也正常。
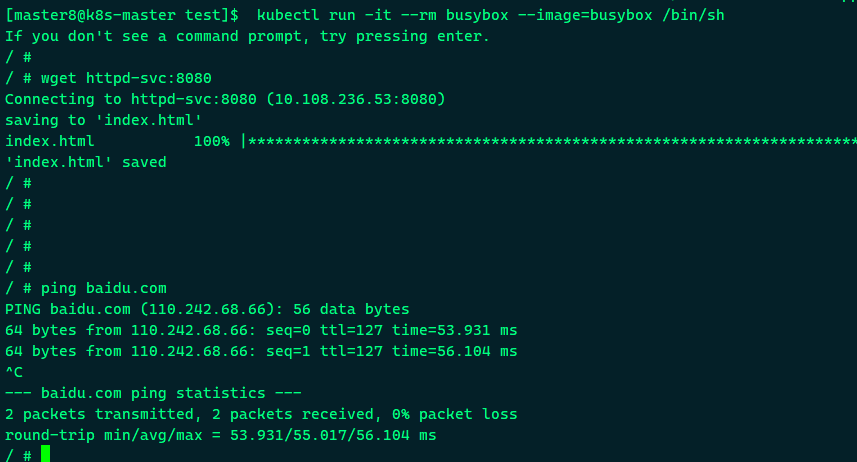
到此, 我们在一个临时的busybox Pod中验证了DNS的有效性。
另外,由于这个Pod与httpd-svc同属于default namespace,因此也可以省略default直接用httpd-svc访问Service;
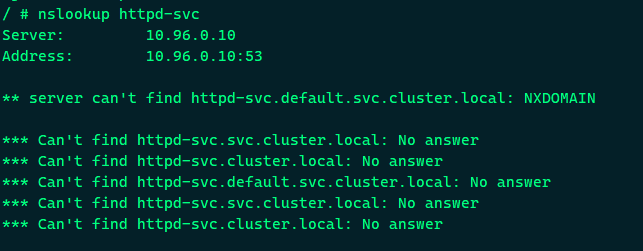
这里应该还是有点问题, 正确应该返回:
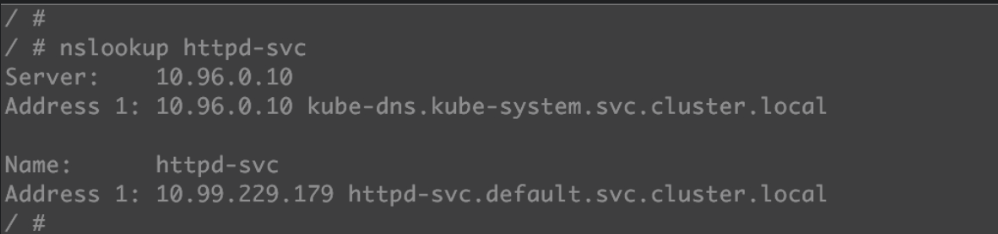
DNS服务器是kube-dns.kube-system.svc.cluster.local,这实际上就是kube-dns组件,它本身是部署在kube-system namespace中的一个Service。
httpd-svc.default.svc.cluster.local是httpd-svc的完整域名。如果要访问其他namespace中的Service,就必须带上namesapce了。kubectl get namespace查看已有的namespace,
我们尝试在kube-public中再部署一个Service httpd2-svc,
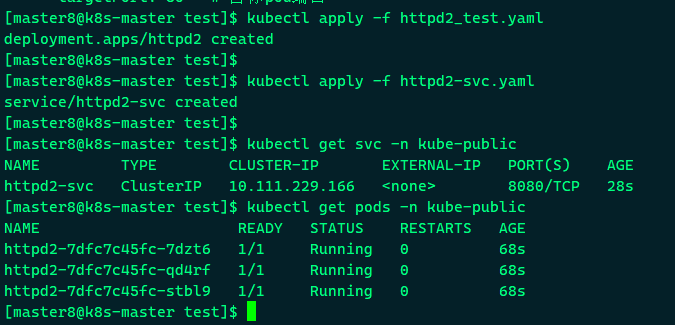
在busybox Pod中访问httpd2-svc, 如下所示:

因为不属于同一个namespace,所以必须使用httpd2-svc.kube-public才能访问到。
外网如何访问Service
除了Cluster内部可以访问Service,很多情况下我们也希望应用的Service能够暴露给Cluster外部。Kubernetes提供了多种类型的Service,默认是ClusterIP。
(1)ClusterIPService通过Cluster内部的IP对外提供服务,只有Cluster内的节点和Pod可访问,这是默认的Service类型,前面实验中的Service都是ClusterIP。
(2)NodePortService通过Cluster节点的静态端口对外提供服务。Cluster外部可以通过:访问Service。
(3)LoadBalancerService利用cloud provider特有的load balancer对外提供服务,cloud provider负责将load balancer的流量导向Service。
目前支持的cloud provider有GCP、AWS、Azure等。
下面我们先来实践NodePort, Service httpd-svc的配置文件修改如下:


Kubernetes依然会为httpd-svc分配一个ClusterIP,不同的是:
(1)EXTERNAL-IP为nodes,表示可通过Cluster每个节点自身的IP访问Service。
(2)PORT(S)为8080:31954。8080是ClusterIP监听的端口,32312则是节点上监听的端口。Kubernetes会从30000~32767中分配一个可用的端口,每个节点都会监听此端口并将请求转发给Service,


通过三个节点IP + 32312端口都能够访问httpd-svc。
接下来我们深入探讨一个问题:Kubernetes是如何将:映射到Pod的呢?
与ClusterIP一样,也是借助了iptables。
与ClusterIP相比,每个节点的iptables中都增加了下面两条规则,
|
|
规则的含义是:访问当前节点31954端口的请求会应用规则KUBE-SVC-IYRDZZKXS5EOQ6Q6,

其作用就是负载均衡到每一个Pod。NodePort默认的是随机选择,不过我们可以用nodePort指定某个特定端口。
|
|
现在配置文件中就有三个Port了:
- nodePort是节点上监听的端口。
- port是ClusterIP上监听的端口。
- targetPort是Pod监听的端口。
最终,Node和ClusterIP在各自端口上接收到的请求都会通过iptables转发到Pod的targetPort。
应用到新的nodePort并验证:
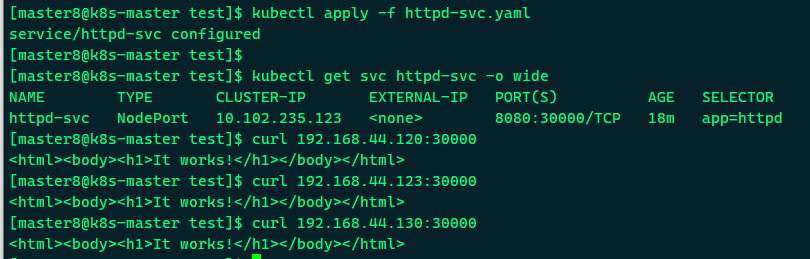
可以看到,nodePort:30000已经生效了;