==1. WEB前端安全那些事儿==
前端攻击都有哪些形式,我该如何防范?
XSS攻击
是什么?
XSS是一种经常出现在web应用中的计算机安全漏洞,它允许恶意web用户将代码植入到提供给其它用户使用的页面中。举个例子,我们有个社交网站,允许大家相互访问空间,网站可能是这样做的:其实在web前端方面,可以简单的理解为一种javascript代码注入。
|
|
运行时,展现形式如图所示:
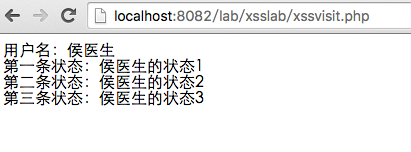
但是,如果你的用户名,起名称的时候,带上script标签呢?我们知道,浏览器遇到html中的script标签的时候,会解析并执行标签中的js脚本代码,那么如果你的用户名称里面含有script标签的话,就可以执行其中的代码了。代码如下,效果如图
|
|
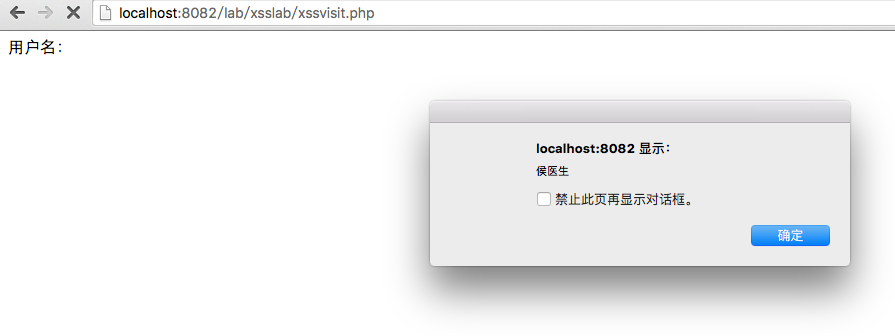
如果你将自己的用户名设定为这种执行脚本的方式,再让别人去访问你的连接的话,就可以达到在他人web环境中,执行自己脚本的效果了。我们还可以使用ajax,将其他用户在当前域名下的cookie获取并发送到自己的服务器上。这样就可以获取他人信息了。比如,刚刚咱们使用的不是alert而是,如下的代码:
|
|
如何防范
目前来讲,最简单的办法防治办法,还是将前端输出数据都进行转义最为稳妥。比如,按照刚刚我们那个例子来说,其本质是,浏览器遇到script标签的话,则会执行其中的脚本。但是如果我们将script标签的进行转义,则浏览器便不会认为其是一个标签,但是显示的时候,还是会按照正常的方式去显示,代码如下,效果如图
|
|

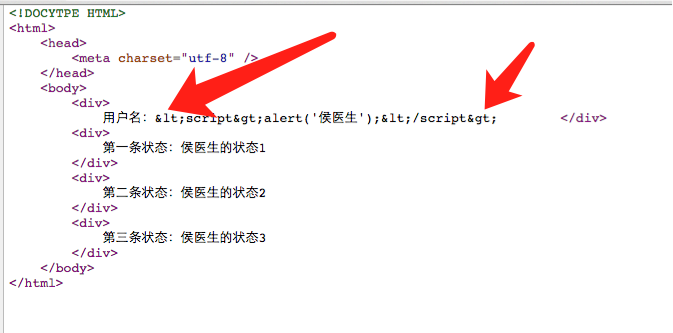
其实,我们再来看看网页源码,如图1.2.2
升级防御
我们将输出的字符串中的\反斜杠进行转义(json转义)。这样,\就不会被当做unicode码的开头来被处理了。代码如下:
|
|
都说了道高一尺魔高一丈了,你以为防得住后端输出,黑客大大们就没办法攻击了吗。我们有的时候,会有一些习惯,拿URL上的get参数去构建网页。好比说,直接拿url上的用户名去展示啦,拿url上的一些回跳地址之类的。但是url上的参数,我们是无法提前对其进行转义的。接下来,来个例子,代码如下:
|
|
上述代码,满足了一个很正常的需求,解开URL中的一个参数,并将其渲染至页面上。但是,这里面存在一个风险,如果黑客在URL的这个参数中,加入js代码,这样便又会被执行。

像这种从url中获取的信息,笔者建议,最好由后端获取,在前端转义后再行输出,代码如下,效果如图
|
|

如果不幸中招了,黑客的js真的在我们的网页上执行了,我们该怎么办。其实,很多时候,我们的敏感信息都是存储在cookie中的(不要把用户机密信息放在网页中),想要阻止黑客通过js访问到cookie中的用户敏感信息。那么请使用cookie的HttpOnly属性,加上了这个属性的cookie字段,js是无法进行读写的。php的设置方法如下:
|
|
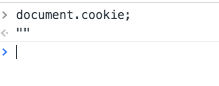
如图,我们的cookie已经种上了,并且有了httpOnly标识

CSRF攻击
CSRF攻击在百度百科中的解释是: CSRF(Cross-site request forgery跨站请求伪造,也被称为“One Click Attack”或者Session Riding,通常缩写为CSRF或者XSRF,是一种对网站的恶意利用。 其实就是网站中的一些提交行为,被黑客利用,你在访问黑客的网站的时候,进行的操作,会被操作到其他网站上(如:你所使用的网络银行的网站)。
如何攻击?
要合理使用post与get
通常我们会为了省事儿,把一些应当提交的数据,做成get请求。殊不知,这不仅仅是违反了http的标准而已,也同样会被黑客所利用。比如,你开发的网站中,有一个购买商品的操作。你是这么开发的:
|
|
而商品ID图个省事儿,就使用了url中的get参数。买商品的话,如图

那么,黑客的网站可以这样开发:
|
|
这样的话,用户只需要访问一次黑客的网站,其实就相当于在你的网站中,操作了一次。然而用户却没有感知。
如果你使用了post请求来处理关键业务的,还是有办法可以破解的。我们的业务代码如下:
|
|
黑客代码如下:
|
|
效果如图

点击后,用户进行了提交,却连自己都不知情。这种情况如何防御呢?
最简单的办法就是加验证码,这样除了用户,黑客的网站是获取不到用户本次session的验证码的。但是这样也会降低用户的提交体验,特别是有些经常性的操作,如果总让用户输入验证码,用户也会非常的烦。
另一种方式,就是在用访问的页面中,都种下验证用的token,用户所有的提交都必须带上本次页面中生成的token,这种方式的本质和使用验证码没什么两样,但是这种方式,整个页面每一次的session,使用同一个token就行,很多post操作,开发者就可以自动带上当前页面的token。如果token校验不通过,则证明此次提交并非从本站发送来,则终止提交过程。如果token确实为本网站生成的话,则可以通过
网络劫持攻击
很多的时候,我们的网站不是直接就访问到我们的服务器上的,中间会经过很多层代理,如果在某一个环节,数据被中间代理层的劫持者所截获,他们就能获取到使用你网站的用户的密码等保密数据。比如,我们的用户经常会在各种饭馆里面,连一些奇奇怪怪的wifi,如果这个wifi是黑客所建立的热点wifi,那么黑客就可以结果该用户收发的所有数据。这里,建议站长们网站都使用https进行加密。这样,就算网站的数据能被拿到,黑客也无法解开。
如果你的网站还没有进行https加密的化,则在表单提交部分,最好进行非对称加密–即客户端加密,只有服务端能解开。这样中间的劫持者便无法获取加密内容的真实信息了。
控制台注入代码
我们平时开发要注意些什么?
- 开发时要提防用户产生的内容,要对用户输入的信息进行层层检测
- 要注意对用户的输出内容进行过滤(进行转义等)
- 重要的内容记得要加密传输(无论是利用https也好,自己加密也好)
- get请求与post请求,要严格遵守规范,不要混用,不要将一些危险的提交使用jsonp完成。
- 对于URL上携带的信息,要谨慎使用。
- 心中时刻记着,自己的网站哪里可能有危险。
==2. 跨域==
受浏览器同源策略的限制,本域的js不能操作其他域的页面对象(比如DOM)。但在安全限制的同时也给注入iframe或是ajax应用上带来了不少麻烦。所以我们要通过一些方法使本域的js能够操作其他域的页面对象或者使其他域的js能操作本域的页面对象
单向跨域(一般用于获取数据)
jsonp
原理:因为通过script标签引入的js是不受同源策略的限制的(正如前文提到的baidu.com的页面加载了google.com的js)。所以我们可以通过script标签引入一个js或者是一个其他后缀形式(如php,jsp等)的文件,此文件返回一个js函数的调用,如返回JSONP_getUsers([“paco”,“john”,“lili”]),也就是说此文件返回的结果调用了JSONP_getUsers函数,并且把[“paco”,“john”,“lili”]传进去,这个[“paco”,“john”,“lili”]是一个用户列表。那么如果此时我们的页面中有一个JSONP_getUsers函数,那么JSONP_getUsers就被调用到,并且传入了用户列表。此时就实现了在本域获取其他域数据的功能,也就是跨域
动态创建script标签
这种方法其实是JSONP跨域的简化版,JSONP只是在此基础上加入了回调函数。
Access Control
此跨域方法目前只在很少的浏览器中得以支持,这些浏览器可以发送一个跨域的HTTP请求(Firefox, Google Chrome等通过XMLHTTPRequest实现,IE8下通过XDomainRequest实现),请求的响应必须包含一个Access- Control-Allow-Origin的HTTP响应头,该响应头声明了请求域的可访问权限。例如baidu.com对google.com下的getUsers.php发送了一个跨域的HTTP请求(通过ajax),那么getUsers.php必须加入如下的响应头:
|
|
window.name
window 对象的name属性是一个很特别的属性,当该window的location变化,然后重新加载,它的name属性可以依然保持不变。那么我们可以在页面 A中用iframe加载其他域的页面B,而页面B中用JavaScript把需要传递的数据赋值给window.name,iframe加载完成之后(iframe.onload),页面A修改iframe的地址,将其变成同域的一个地址,然后就可以读出iframe的window.name的值了(因为A中的window.name和iframe中的window.name互相独立的,所以不能直接在A中获取window.name,而要通过iframe获取其window.name)。这个方式非常适合单向的数据请求,而且协议简单、安全。不会像JSONP那样不做限制地执行外部脚本。
服务器代理
在数据提供方没有提供对JSONP协议或者 window.name协议的支持,也没有对其它域开放访问权限时,我们可以通过server proxy的方式来抓取数据。例如当baidu.com域下的页面需要请求google.com下的资源文件getUsers.php时,直接发送一个指向 google.com/getUsers.php的Ajax请求肯定是会被浏览器阻止。这时,我们在baidu.com下配一个代理,然后把Ajax请求绑定到这个代理路径下,例如baidu.com/proxy/, 然后这个代理发送HTTP请求访问google.com下的getUsers.php,跨域的HTTP请求是在服务器端进行的(服务器端没有同源策略限制),客户端并没有产生跨域的Ajax请求。这个跨域方式不需要和目标资源签订协议,带有侵略性。
document.domain(两个iframe之间)
通过修改document的domain属性,我们可以在域和子域或者不同的子域之间通信。同域策略认为域和子域隶属于不同的域,比如baidu.com和 youxi.baidu.com是不同的域,这时,我们无法在baidu.com下的页面中调用youxi.baidu.com中定义的JavaScript方法。但是当我们把它们document的domain属性都修改为baidu.com,浏览器就会认为它们处于同一个域下,那么我们就可以互相获取对方数据或者操作对方DOM了。
问题: 1、安全性,当一个站点被攻击后,另一个站点会引起安全漏洞。 2、如果一个页面中引入多个iframe,要想能够操作所有iframe,必须都得设置相同domain。
location.hash(两个iframe之间),又称FIM,Fragment Identitier Messaging的简写
因为父窗口可以对iframe进行URL读写,iframe也可以读写父窗口的URL,URL有一部分被称为hash,就是#号及其后面的字符,它一般用于浏览器锚点定位,Server端并不关心这部分,应该说HTTP请求过程中不会携带hash,所以这部分的修改不会产生HTTP请求,但是会产生浏览器历史记录。此方法的原理就是改变URL的hash部分来进行双向通信。每个window通过改变其他 window的location来发送消息(由于两个页面不在同一个域下IE、Chrome不允许修改parent.location.hash的值,所以要借助于父窗口域名下的一个代理iframe),并通过监听自己的URL的变化来接收消息。这个方式的通信会造成一些不必要的浏览器历史记录,而且有些浏览器不支持onhashchange事件,需要轮询来获知URL的改变,最后,这样做也存在缺点,诸如数据直接暴露在了url中,数据容量和类型都有限等。
使用HTML5的postMessage方法(两个iframe之间或者两个页面之间)
高级浏览器Internet Explorer 8+, chrome,Firefox , Opera 和 Safari 都将支持这个功能。这个功能主要包括接受信息的"message"事件和发送消息的"postMessage"方法。比如baidu.com域的A页面通过iframe嵌入了一个google.com域的B页面,可以通过以下方法实现A和B的通信
A页面通过postMessage方法发送消息:
|
|
postMessage的使用方法:
otherWindow.postMessage(message, targetOrigin);
otherWindow: 指目标窗口,也就是给哪个window发消息,是 window.frames 属性的成员或者由 window.open 方法创建的窗口 message: 是要发送的消息,类型为 String、Object (IE8、9 不支持) targetOrigin: 是限定消息接收范围,不限制请使用 ‘*’
B页面通过message事件监听并接受消息:
|
|
==3.一次完整的HTTP事务是怎样的一个过程?==
基本流程: a. 域名解析 b. 发起TCP的3次握手 c. 建立TCP连接后发起http请求 d. 服务器端响应http请求,浏览器得到html代码 e. 浏览器解析html代码,并请求html代码中的资源 f. 浏览器对页面进行渲染呈现给用户
==4. 排序算法==

冒泡排序
两两比较,若反则交换位置
|
|
选择排序
每次都找最小的数
|
|
插入排序
|
|
希尔排序
|
|
归并排序

|
|
快速排序
|
|
堆排序

|
|
==5. 函数式编程==
函数式编程有一下几个特点:
- 函数是“第一等公民”:函数与其他数据类型一样,可以赋值给其他变量,也可以作为参数,传入另一个函数,或作为别的函数的返回值
- 只用“表达书”,不用语句:每一步都是单纯的运算,而且都有返回值
- 没有“副作用”:函数要保持独立,所有功能就是返回一个新的值,没有其他行为,尤其不得修改外部变量的值
- 不修改状态,返回新的值,不修改系统变量
- 引用透明:函数的运行不依赖与外部变量或“状态”,只依赖于输入的参数,任何时候只要参数相同,引用函数所得到的返回值总是相同的
优点:
- 代码简洁,开发快速:函数式编程大量使用函数,减少了代码的重复,因此程序比较短,开发速度较快
- 接近自然语言,易于理解
- 更方便的代码管理:函数式编程不依赖、也不会改变外界的状态,只要给定输入参数,返回的结果必定相同。因此,每一个函数都可以被看做独立单元,很有利于进行单元测试(unit testing)和除错(debugging),以及模块化组合。
- 易于"并发编程":函数式编程不需要考虑"死锁"(deadlock),因为它不修改变量,所以根本不存在"锁"线程的问题。不必担心一个线程的数据,被另一个线程修改,所以可以很放心地把工作分摊到多个线程,部署"并发编程"(concurrency)
- 代码的热升级:函数式编程没有副作用,只要保证接口不变,内部实现是外部无关的。所以,可以在运行状态下直接升级代码,不需要重启,也不需要停机。
==6. 函数式编程——柯里化(curry)==
curry 的概念很简单:只传递给函数一部分参数来调用它,让它返回一个函数去处理剩下的参数
|
|
我们来创建一些 curry 函数享受下(译者注:此处原文是“for our enjoyment”,语出自圣经)
|
|
我在上面的代码中遵循的是一种简单,同时也非常重要的模式。即策略性地把要操作的数据(String, Array)放到最后一个参数里。到使用它们的时候你就明白这样做的原因是什么了。
|
|
这里表明的是一种“预加载”函数的能力,通过传递一到两个参数调用函数,就能得到一个记住了这些参数的新函数。
==7. redux理解==
-
React有props和state: props意味着父级分发下来的属性,state意味着组件内部可以自行管理的状态,并且整个React没有数据向上回溯的能力,也就是说数据只能单向向下分发,或者自行内部消化。理解这个是理解React和Redux的前提。
-
一般构建的React组件内部可能是一个完整的应用,它自己工作良好,你可以通过属性作为API控制它。但是更多的时候发现React根本无法让两个组件互相交流,使用对方的数据。然后这时候不通过DOM沟通(也就是React体制内)解决的唯一办法就是提升state,将state放到共有的父组件中来管理,再作为props分发回子组件。
-
子组件改变父组件state的办法只能是通过onClick触发父组件声明好的回调,也就是父组件提前声明好函数或方法作为契约描述自己的state将如何变化,再将它同样作为属性交给子组件使用。这样就出现了一个模式:数据总是单向从顶层向下分发的,但是只有子组件回调在概念上可以回到state顶层影响数据。这样state一定程度上是响应式的。
-
为了面临所有可能的扩展问题,最容易想到的办法就是把所有state集中放到所有组件顶层,然后分发给所有组件。
-
为了有更好的state管理,就需要一个库来作为更专业的顶层state分发给所有React应用,这就是Redux。让我们回来看看重现上面结构的需求:
- 需要回调通知state (等同于回调参数) -> action
- 需要根据回调处理 (等同于父级方法) -> reducer
- 需要state (等同于总状态) -> store
对Redux来说只有这三个要素:
- action是纯声明式的数据结构,只提供事件的所有要素,不提供逻辑
- reducer是一个匹配函数,action的发送是全局的:所有的reducer都可以捕捉到并匹配与自己相关与否,相关就拿走action中的要素进行逻辑处理,修改store中的状态,不相关就不对state做处理原样返回。
- store负责存储状态并可以被react api回调,发布action.当然一般不会直接把两个库拿来用,还有一个binding叫react-redux, 提供一个Provider和connect。
很多人其实看懂了redux卡在这里。
- Provider是一个普通组件,可以作为顶层app的分发点,它只需要store属性就可以了。它会将state分发给所有被connect的组件,不管它在哪里,被嵌套多少层。
- connect是真正的重点,它是一个科里化函数,意思是先接受两个参数(数据绑定mapStateToProps和事件绑定mapDispatchToProps),再接受一个参数(将要绑定的组件本身):mapStateToProps:构建好Redux系统的时候,它会被自动初始化,但是你的React组件并不知道它的存在,因此你需要分拣出你需要的Redux状态,所以你需要绑定一个函数,它的参数是state,简单返回你关心的几个值。
mapDispatchToProps:声明好的action作为回调,也可以被注入到组件里,就是通过这个函数,它的参数是dispatch,通过redux的辅助方法bindActionCreator绑定所有action以及参数的dispatch,就可以作为属性在组件里面作为函数简单使用了,不需要手动dispatch。这个mapDispatchToProps是可选的,如果不传这个参数redux会简单把dispatch作为属性注入给组件,可以手动当做store.dispatch使用。这也是为什么要科里化的原因。
做好以上流程Redux和React就可以工作了。简单地说就是:
- 顶层分发状态,让React组件被动地渲染。
- 监听事件,事件有权利回到所有状态顶层影响状态。
==8. 虚拟dom==
相关链接:深度剖析:如何实现一个 Virtual DOM 算法
源码网址: GitHub
目录:
- 对前端应用状态管理思考
- Virtual DOM 算法
- 算法实现
- 步骤一:用JS对象模拟DOM树
- 步骤二:比较两棵虚拟DOM树的差异
- 步骤三:把差异应用到真正的DOM树上
- 结语
- References
1 对前端应用状态管理的思考
假如现在你需要写一个像下面一样的表格的应用程序,这个表格可以根据不同的字段进行升序或者降序的展示。
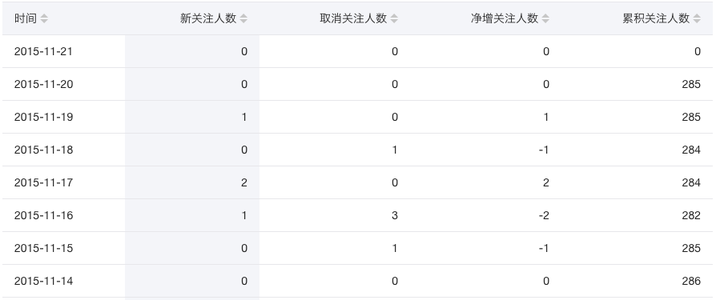
这个应用程序看起来很简单,你可以想出好几种不同的方式来写。最容易想到的可能是,在你的 JavaScript 代码里面存储这样的数据:
|
|
用三个字段分别存储当前排序的字段、排序方向、还有表格数据;然后给表格头部加点击事件:当用户点击特定的字段的时候,根据上面几个字段存储的内容来对内容进行排序,然后用 JS 或者 jQuery 操作 DOM,更新页面的排序状态(表头的那几个箭头表示当前排序状态,也需要更新)和表格内容。
这样做会导致的后果就是,随着应用程序越来越复杂,需要在JS里面维护的字段也越来越多,需要监听事件和在事件回调用更新页面的DOM操作也越来越多,应用程序会变得非常难维护。后来人们使用了 MVC、MVP 的架构模式,希望能从代码组织方式来降低维护这种复杂应用程序的难度。但是 MVC 架构没办法减少你所维护的状态,也没有降低状态更新你需要对页面的更新操作(前端来说就是DOM操作),你需要操作的DOM还是需要操作,只是换了个地方。
既然状态改变了要操作相应的DOM元素,为什么不做一个东西可以让视图和状态进行绑定,状态变更了视图自动变更,就不用手动更新页面了。这就是后来人们想出了 MVVM 模式,只要在模版中声明视图组件是和什么状态进行绑定的,双向绑定引擎就会在状态更新的时候自动更新视图(关于MV*模式的内容,可以看这篇介绍)。
MVVM 可以很好的降低我们维护状态 -> 视图的复杂程度(大大减少代码中的视图更新逻辑)。但是这不是唯一的办法,还有一个非常直观的方法,可以大大降低视图更新的操作:一旦状态发生了变化,就用模版引擎重新渲染整个视图,然后用新的视图更换掉旧的视图。就像上面的表格,当用户点击的时候,还是在JS里面更新状态,但是页面更新就不用手动操作 DOM 了,直接把整个表格用模版引擎重新渲染一遍,然后设置一下innerHTML就完事了。
听到这样的做法,经验丰富的你一定第一时间意识这样的做法会导致很多的问题。最大的问题就是这样做会很慢,因为即使一个小小的状态变更都要重新构造整棵 DOM,性价比太低;而且这样做的话,input和textarea的会失去原有的焦点。最后的结论会是:对于局部的小视图的更新,没有问题(Backbone就是这么干的);但是对于大型视图,如全局应用状态变更的时候,需要更新页面较多局部视图的时候,这样的做法不可取。
但是这里要明白和记住这种做法,因为后面你会发现,其实 Virtual DOM 就是这么做的,只是加了一些特别的步骤来避免了整棵 DOM 树变更。
另外一点需要注意的就是,上面提供的几种方法,其实都在解决同一个问题:维护状态,更新视图。在一般的应用当中,如果能够很好方案来应对这个问题,那么就几乎降低了大部分复杂性。
2. Virtual DOM算法
DOM是很慢的。如果我们把一个简单的div元素的属性都打印出来,你会看到:

而这仅仅是第一层。真正的 DOM 元素非常庞大,这是因为标准就是这么设计的。而且操作它们的时候你要小心翼翼,轻微的触碰可能就会导致页面重排,这可是杀死性能的罪魁祸首。
相对于 DOM 对象,原生的 JavaScript 对象处理起来更快,而且更简单。DOM 树上的结构、属性信息我们都可以很容易地用 JavaScript 对象表示出来:
|
|
上面对应的HTML写法是:
|
|
既然原来 DOM 树的信息都可以用 JavaScript 对象来表示,反过来,你就可以根据这个用 JavaScript 对象表示的树结构来构建一棵真正的DOM树。
之前的章节所说的,状态变更->重新渲染整个视图的方式可以稍微修改一下:用 JavaScript 对象表示 DOM 信息和结构,当状态变更的时候,重新渲染这个 JavaScript 的对象结构。当然这样做其实没什么卵用,因为真正的页面其实没有改变。
但是可以用新渲染的对象树去和旧的树进行对比,记录这两棵树差异。记录下来的不同就是我们需要对页面真正的 DOM 操作,然后把它们应用在真正的 DOM 树上,页面就变更了。这样就可以做到:视图的结构确实是整个全新渲染了,但是最后操作DOM的时候确实只变更有不同的地方。
这就是所谓的 Virtual DOM 算法。包括几个步骤:
- ==用 JavaScript 对象结构表示 DOM 树的结构;然后用这个树构建一个真正的 DOM 树,插到文档书中==
- ==当状态变更的时候,重新构造一棵新的对象树。然后用新的树和旧的树进行比较,记录两棵树差异==
- ==把2所记录的差异应用到步骤1所构建的真正的DOM树上,视图就更新了==
Virtual DOM 本质上就是在 JS 和 DOM 之间做了一个缓存。可以类比 CPU 和硬盘,既然硬盘这么慢,我们就在它们之间加个缓存:既然 DOM 这么慢,我们就在它们 JS 和 DOM 之间加个缓存。CPU(JS)只操作内存(Virtual DOM),最后的时候再把变更写入硬盘(DOM)。
3. 算法实现
3.1 步骤一:用JS对象模拟DOM树
用 JavaScript 来表示一个 DOM 节点是很简单的事情,你只需要记录它的节点类型、属性,还有子节点:
element.js
|
|
例如上面的 DOM 结构就可以简单的表示:
|
|
现在ul只是一个 JavaScript 对象表示的 DOM 结构,页面上并没有这个结构。我们可以根据这个ul构建真正的:
|
|
render方法会根据tagName构建一个真正的DOM节点,然后设置这个节点的属性,最后递归地把自己的子节点也构建起来。所以只需要:
|
|
上面的ulRoot是真正的DOM节点,把它塞入文档中,这样body里面就有了真正的ul的DOM结构:
|
|
3.2 步骤二:比较两棵虚拟DOM树的差异
正如你所预料的,比较两棵DOM树的差异是 Virtual DOM 算法最核心的部分,这也是所谓的 Virtual DOM 的 diff 算法。两个树的完全的 diff 算法是一个时间复杂度为 O(n^3) 的问题。但是在前端当中,你很少会跨越层级地移动DOM元素。所以 Virtual DOM 只会对同一个层级的元素进行对比:
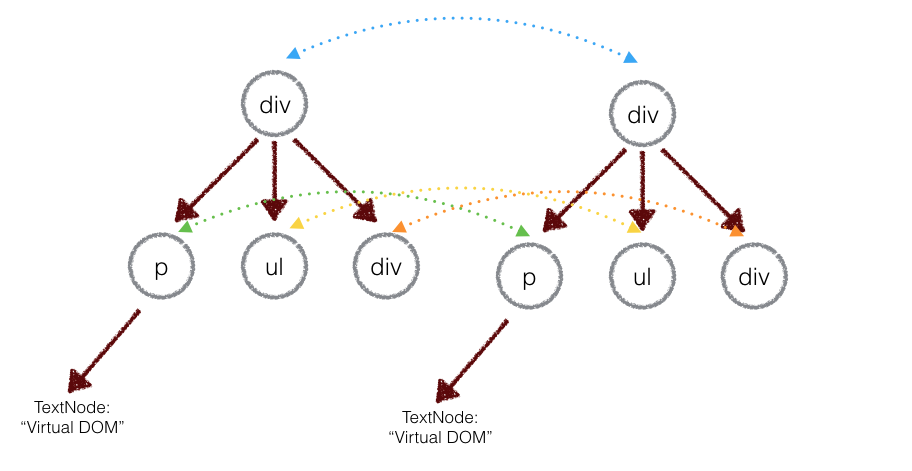
上面的div只会和同一层级的div对比,第二层级的只会跟第二层级对比。这样算法复杂度就可以达到 O(n)。
3.2.1 深度优先遍历,记录差异
在实际的代码中,会对新旧两棵树进行一个深度优先的遍历,这样每个节点都会有一个唯一的标记:
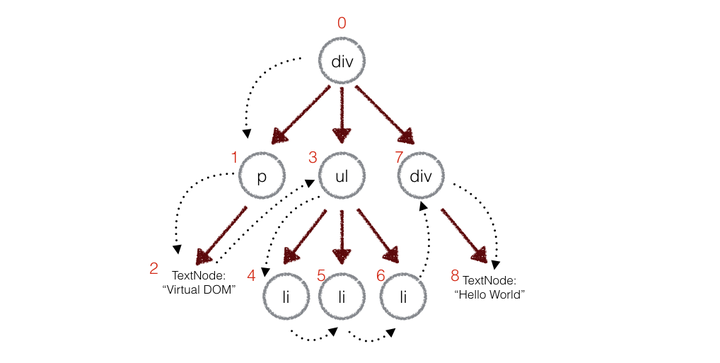
在深度优先遍历的时候,每遍历到一个节点就把该节点和新的的树进行对比。如果有差异的话就记录到一个对象里面。
|
|
例如,上面的div和新的div有差异,当前的标记是0,那么:
|
|
3.2.2 差异类型
上面说的节点的差异指的是什么呢?对 DOM 操作可能会:
- 替换掉原来的节点,例如把上面的div换成了section
- 移动、删除、新增子节点,例如上面div的子节点,把p和ul顺序互换
- 修改了节点的属性
- 对于文本节点,文本内容可能会改变。例如修改上面的文本节点2内容为Virtual DOM 2。
所以我们定义了几种差异类型:
|
|
对于节点替换,很简单。判断新旧节点的tagName和是不是一样的,如果不一样的说明需要替换掉。如div换成section,就记录下:
|
|