集合和LINQ
建议16: 元素数量在可变的情况下不应该使用数组
在C#中,数组一旦被创建,长度就不能改变。如果我们需要一个动态且可变长度的集合,就应该使用ArrayList或List来创建。 而数组本身,尤其是一维数组,在遇到要求高效率的算法时,则会专门被优化以提升其效率。一维数组也成为向量,其性能是最佳的,在IL中使用了专门的指令来 处理它们(如newarr、ldelem、ldelema、ldelen和stelem)。
从内存的使用角度来讲,数组在创建时被分配了一段固定长度的内存。如果数组的元素是值类型,则每个元素的长度等于相应的值类型的长度;如果数组的元素是引用类型,则每个元素的长度为该引用类型的IntPtr.Size(IntPtr:It's a class that wraps a pointer that is used when calling Windows API functions. The underlying pointer may be 32 bit or 64 bit, depending on the platform.)。数组的存储结构一旦被分配,就不能再变化。而ArrayList是链表结构,可以动态的增减内存空间,如果ArrayList存储的是值类型,则会为每个元素增加12字节的空间,其中4个字节拥有对象引用,8字节是元素装箱时引入的对象头。List是ArrayList的泛型实现,它省去了装箱和拆箱带来的开销。
注意:
由于数组本身在内存上的特点,因此在使用数组的过程中还应该注意大对象的问题。所谓“大对象”,是指那些占内存超过85000字节的对象,它们被分配在大对象堆里。大对象的分配和回收和小对象都不太一样,尤其是回收,大对象在回收过程中会带来效率很低的问题。所以,不能对数组指定过大的长度,这会让数组成为一个大对象。
如果一定要动态改变数组的长度,一种做法是将数组转换为ArrayList或List, 如下面的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
using System;
using System.Collections;
using System.Collections.Generic;
using System.Linq;
namespace Advice16
{
internal class Program
{
static void Main(string[] args)
{
int[] iArr = new int[] { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
ArrayList arrayList = new ArrayList(iArr);
arrayList.Add(10);
List<int> listInt = iArr.ToList();
listInt.Add(10);
foreach (var item in arrayList)
{
Console.Write(item + " ");
}
Console.WriteLine();
listInt.ForEach(x => Console.Write(x + " "));
}
}
}
|
还有一种办法是数组的复制功能, 数组继承自System.Array, 抽象类System.Array提供了一些有用的实现方法。其中就包括Copy方法,它负责将一个数组的内容复制到另外一个数组中。无论哪种方法,改变数组长度就相当于重新创建了一个数组对象。
为了让数组看上去本身就具有动态改变长度的功能,可以创建一个名为Resize的扩展方法,代码如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
using System;
namespace Advice16
{
internal class Program
{
static void Main(string[] args)
{
int[] iArr = new int[] { 0, 1, 2, 3, 4, 5, 6};
iArr = (int[])iArr.Resize(10);
for (int i = 0; i < iArr.Length; i++)
{
Console.WriteLine(iArr[i]);
}
}
}
public static class ClassForExtensions
{
public static Array Resize(this Array array, int newSize)
{
Type t = array.GetType().GetElementType();
Array newArray = Array.CreateInstance(t, newSize);
Array.Copy(array, 0, newArray, 0, Math.Min(array.Length, newSize));
return newArray;
}
}
}
|
下面对改变数组长度和改变Lisit<T>长度的耗时做一个比较,以便强调本建议的主题:在元素数量可变的情况下不应该使用数组:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
using System;
using System.Collections.Generic;
using System.Diagnostics;
namespace Advice16
{
internal class Program
{
static void Main(string[] args)
{
ResizeArray();
ResizeList();
}
private static void ResizeArray()
{
int[] iArr = { 0, 1, 2, 3, 4, 5, 6 };
Stopwatch watch = new Stopwatch();
watch.Start();
iArr = (int[])iArr.Resize(10);
watch.Stop();
Console.WriteLine("ResizeArray: " + watch.Elapsed);
}
private static void ResizeList()
{
List<int> iArr = new List<int>(new int[] { 0, 1, 2, 3, 4, 5, 6 });
Stopwatch watch = new Stopwatch();
watch.Start();
iArr.Add(0);
iArr.Add(0);
iArr.Add(0);
watch.Stop();
Console.WriteLine("ResizeList: " + watch.Elapsed);
}
}
public static class ClassForExtensions
{
public static Array Resize(this Array array, int newSize)
{
Type t = array.GetType().GetElementType();
Array newArray = Array.CreateInstance(t, newSize);
Array.Copy(array, 0, newArray, 0, Math.Min(array.Length, newSize));
return newArray;
}
}
}
|
输出为:
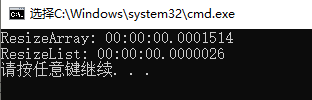
当然,严格意义上讲,List不存在改变长度的说法,本建议只是为了比较,将iArr的长度变为10,同时还进行了赋值。即便这样,我们可以看到,在时间效率上ResizeList比ResizeArray要高100倍以上。
建议17:多数情况下使用foreach进行循环遍历
这个主要是针对集合遍历的情况, 我们设想一下一般是如何对集合进行遍历的。假设存在一个数组,其遍历模式可以采用依据索引来进行遍历的方法;又假设存在一个哈希表,它的遍历模式可能是按照键值来进行遍历。无论是哪个集合,如果它们的遍历没有一个公共的接口,那么客户端在进行遍历的时候,相当于是对具体类型进行了一个编码,这样一来当需求发生变更时, 必须修改我们的代码。而且,由于客户端代码过多的关注集合内部的实现,代码的可移植性就会变得很差,这样直接违背了面向对象的开闭原则,于是迭代器模式就诞生了。
现在,我们不用管FCL是如何实现该模式的,先自己来实现一个迭代器模式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
|
namespace Advice17
{
// 要求所有迭代器全部实现该接口
interface IMyEnumerator
{
bool MoveNext();
object Current { get; }
}
// 要求所有的集合实现该接口
// 这样一来, 客户端就可以针对该接口编码, 而无需关注具体的实现
interface IMyEnumerable
{
IMyEnumerator GetEnumerator();
int Count { get; }
}
class MyList : IMyEnumerable
{
object[] items = new object[10];
IMyEnumerator myEnumerator;
public object this[int i]
{
get { return items[i]; }
set { this.items[i] = value; }
}
public int Count => items.Length;
public IMyEnumerator GetEnumerator()
{
if (myEnumerator == null)
{
myEnumerator = new MyEnumerator(this);
}
return myEnumerator;
}
}
class MyEnumerator : IMyEnumerator
{
int index = 0;
MyList myList;
public MyEnumerator(MyList myList)
{
this.myList = myList;
}
public object Current => myList[index - 1];
public bool MoveNext()
{
if (index + 1 > myList.Count)
{
index = 1;
return false;
}
else
{
index++;
return true;
}
}
}
}
|
Main函数去调用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
namespace Advice17
{
internal class Program
{
static void Main(string[] args)
{
// 使用接口IMyEnumerable代替MyList
IMyEnumerable list = new MyList();
// 得到迭代器, 在循环中针对迭代器编码, 而不是集合MyList
IMyEnumerator enumerator = list.GetEnumerator();
for (int i = 0; i < list.Count; i++)
{
object current = enumerator.Current;
enumerator.MoveNext();
}
while (enumerator.MoveNext())
{
object current = enumerator.Current;
}
}
}
}
|
MyList模拟了一个集合类,它继承了接口IMyEnumerable,这样,在客户端调用的时候,我们就可以直接调用IMyEnumerable来声明变量,如代码中的以下语句:
IMyEnumerable list = new MyList();
如果以后我们新增了其他的集合类,那么针对list的编码即使不做修改也能运行良好。在IMyEnumerable中声明了GetEnumerator方法返回一个继承了IMyEnumerator的对象。在MyList的内部,默认返回MyEnumerator,MyEnumerator就是迭代器的一个实现,如果对于迭代的需求有变化,可以重新开发一个迭代器,然后在客户端迭代的时候使用该迭代器。
在客户端的代码中,我们在迭代的过程中分别演示了for循环和while循环,到那时因为使用了迭代器的缘故,两个循环都没有针对MyList编码,而是实现了对迭代器的编码。
理解了自己实现的迭代器模式,相当于理解了FCL中提供的对应模式。以上代码中,在接口和类型中都加入了“My”字样,其实,FCL中有与之相对应的接口和类型,只不过为了演示需要,增加了其中部分内容,但是大致思路是一样的。使用FCL中相应类型进行客户端代码编写,大致应该下面这样:
1
2
3
4
5
6
7
8
9
10
11
|
ICollection<object> list = new List<Object>();
IEnumerator enumerator = list.GetEnumerator();
for (int i = 0; i < list.Count; i++)
{
object current = enumerator.Current;
enumerator.MoveNext();
}
while (enumerator.MoveNext())
{
object current = enumerator.Current;
}
|
但是目前看来, 无论是for循环还是while循环, 都有些啰嗦, 于是, foreach便出现了;
1
2
3
4
|
foreach (var current in list)
{
// ignore object current = enumerator.Current;
}
|
这里使用ildasm(il叫中间语言, dasm叫反编译)来查看一下exe文件,
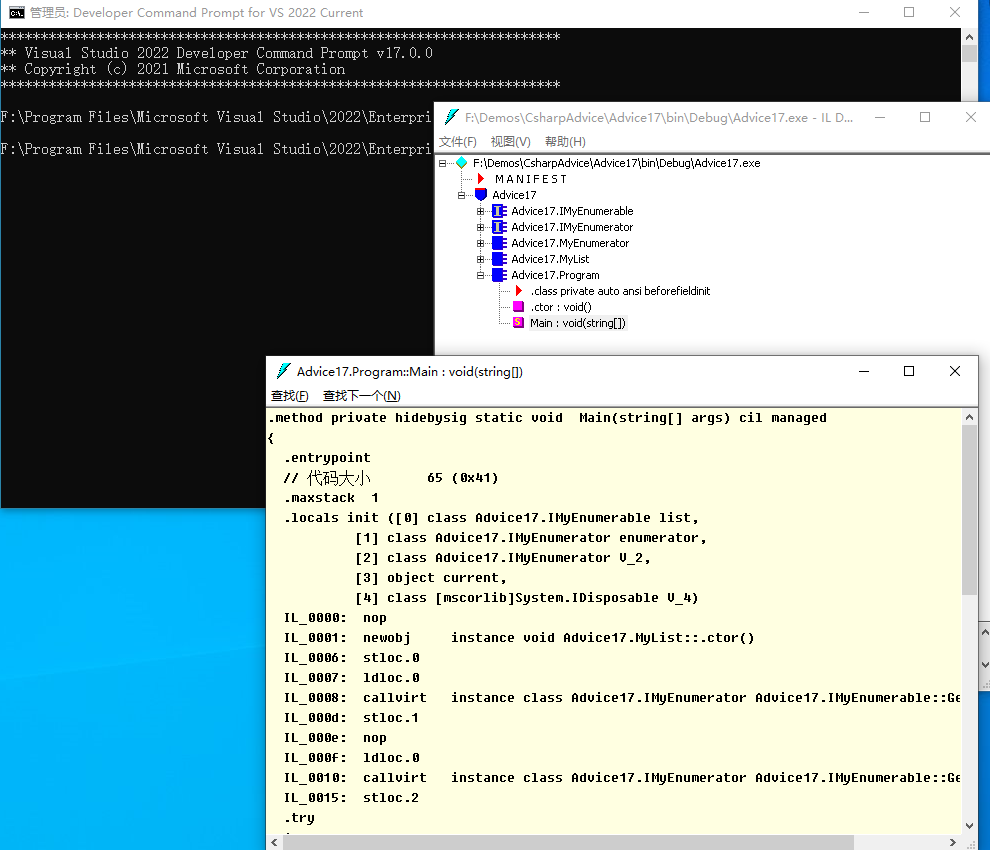
可以看到,采用foreach最大限度地简化了代码。它用于遍历一个继承了IEnumerable或IEnumerable<T>接口的集合元素。借助IL代码,我们查看使用foreach到底发生了什么事情:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
.method private hidebysig static void Main(string[] args) cil managed
{
.entrypoint
// 代码大小 65 (0x41)
.maxstack 1
.locals init ([0] class Advice17.IMyEnumerable list,
[1] class Advice17.IMyEnumerator enumerator,
[2] class Advice17.IMyEnumerator V_2,
[3] object current,
[4] class [mscorlib]System.IDisposable V_4)
IL_0000: nop
IL_0001: newobj instance void Advice17.MyList::.ctor()
IL_0006: stloc.0
IL_0007: ldloc.0
IL_0008: callvirt instance class Advice17.IMyEnumerator Advice17.IMyEnumerable::GetEnumerator()
IL_000d: stloc.1
IL_000e: nop
IL_000f: ldloc.0
IL_0010: callvirt instance class Advice17.IMyEnumerator Advice17.IMyEnumerable::GetEnumerator()
IL_0015: stloc.2
.try
{
IL_0016: br.s IL_0021
IL_0018: ldloc.2
IL_0019: callvirt instance object Advice17.IMyEnumerator::get_Current()
IL_001e: stloc.3
IL_001f: nop
IL_0020: nop
IL_0021: ldloc.2
IL_0022: callvirt instance bool Advice17.IMyEnumerator::MoveNext()
IL_0027: brtrue.s IL_0018
IL_0029: leave.s IL_0040
} // end .try
finally
{
IL_002b: ldloc.2
IL_002c: isinst [mscorlib]System.IDisposable
IL_0031: stloc.s V_4
IL_0033: ldloc.s V_4
IL_0035: brfalse.s IL_003f
IL_0037: ldloc.s V_4
IL_0039: callvirt instance void [mscorlib]System.IDisposable::Dispose()
IL_003e: nop
IL_003f: endfinally
} // end handler
IL_0040: ret
} // end of method Program::Main
|
查看IL代码就可以看出,运行时还是会调用get_Current()和MoveNext()方法。
在调用完MoveNext()方法后,如果结果是true,跳转到循环开始处。实际上foreach循环和while循环是一样的:
我们发现,foreach循环除了可以提供简化的语法外,还有另外两个优势:
- 自动将代码置入try finally语句块;
- 若类型实现了
IDisposable接口,它会在循环结束后自动调用Dispose方法。
建议18:foreach不能代替for
前面提到foreach有两个优点:语法简单,默认调用Dispose方法,因此强烈建议在在实际的代码编写中更多的使用foreach。但是,该建议也有不适合的场景。
foreach存在一个问题:它不支持循环时对集合进行增删操作。比如,运行下面代码会抛出异常InvalidOperationException:
``at System.ThrowHelper.ThrowInvalidOperationException(ExceptionResource resource)
at System.Collections.Generic.List1.Enumerator.MoveNextRare()
at System.Collections.Generic.List1.Enumerator.MoveNext()
at Advice18.Program.Main(String[] args) in F:\Demos\CsharpAdvice\Advice18\Program.cs:line 11
1
2
3
4
5
6
|
List<int> list = new List<int> { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
foreach (var item in list)
{
Console.WriteLine(item);
list.Remove(item);
}
|
取而代之的是for循环:
1
2
3
4
5
|
for (int i = 0; i < list.Count; i++)
{
Console.WriteLine(list[i]);
list.Remove(list[i]);
}
|
foreach循环使用了迭代器进行集合的遍历,它在FCL提供的迭代替内部维护了一个对集合版本的控制。
什么是集合版本?
简单来说,实际上是一个整型变量,任何对集合的增删操作都会使版本号加1. foreach会调用MoveNext方法来遍历元素,在MoveNext方法内部会进行版本号的检测,一旦检测到版本号有变动,就会抛出InvalidOperationException异常。
如果使用for就不会带来这样的问题,for直接使用索引器,它不对集合版本号进行判断,所以不会存在以为集合的变动而带来的异常(当然,超出索引长度这种异常情况除外)。
由于for循环和foreach循环实现上有所不同(前者索引器,后者迭代器),因此关于两者性能上的争议从来没有停止过。但是,即使有争议,双方都承认两者在时间和内存上有损耗,尤其是针对泛型集合时,两者的损耗是在同一个数量级别上的。
以类型List为例, 索引器如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
[__DynamicallyInvokable]
public T this[int index]
{
[TargetedPatchingOptOut("Performance critical to inline across NGen image boundaries"), __DynamicallyInvokable]
get
{
if (index >= this._size)
{
ThrowHelper.ThrowArgumentOutOfRangeException();
}
return this._items[index];
}
[TargetedPatchingOptOut("Performance critical to inline across NGen image boundaries"), __DynamicallyInvokable]
set
{
if (index >= this._size)
{
ThrowHelper.ThrowArgumentOutOfRangeException();
}
this._items[index] = value;
this._version++;
}
}
|
迭代器如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
|
[__DynamicallyInvokable]
public bool MoveNext()
{
List<T> list = this.list;
if ((this.version == list._version) && (this.index < list._size))
{
this.current = list._items[this.index];
this.index++;
return true;
}
return this.MoveNextRare();
}
|
1
2
3
4
5
6
7
8
9
|
[__DynamicallyInvokable]
public T Current
{
[__DynamicallyInvokable, TargetedPatchingOptOut("Performance critical to inline this type of method across NGen image boundaries")]
get
{
return this.current;
}
}
|
可以看到,List类内部维护着一个泛型数组:
private T[] _items;
无论是for循环还是foreach循环,内部都是对该数组的访问,而迭代器仅仅是多进行了一次版本检测。事实上,在循环内部,两者生成的IL代码也是差不多的,因为版本检测的缘故,foreach循环并不能代替for循环。
建议19:使用更有效的对象和集合初始化
依赖于属性和FCL提供的语法规则, 我们有了更加简洁有效的对象和初始化机制:对象和集合初始化设定项;
对象初始化:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
class Person
{
public string Name { get; set; }
public int Age { get; set; }
}
class Program
{
static void Main(string[] args)
{
Person person = new Person() {Name = "Mike", Age = 20};
Console.Read();
}
}
|
对象初始化设定项支持在大括号中对自动实现的属性进行赋值。以往只能依靠构造方法传值进去,或者在对象构造完毕后对属性进行赋值。现在这些步骤简化了,初始化设定项实际上相当于编译器在对象生成后对属性进行了赋值。
集合初始化同样进行了简化:
1
2
3
4
5
6
|
List<Person> personList=new List<Person>()
{
new Person(){Name = "rose",Age=19},
person,
null
};
|
使用集合初始化设定项, 编译器就会在集合对象创建完毕后对集合调用Add方法;
上面这段代码演示了如何在初始化语句中创建一个新对象或者一个现有对象,以及一个null值;
不过,初始化设定项不仅仅是为了对象和集合初始化方便,为LINQ查询返回的集合中匿名类型的属性都是只读的,如果需要为匿名类型属性赋值,或者增加属性,只能通过初始化设定项来进行。初始化设定项还能为属性使用表达式。
下面的代码LINQ查询中创建了一个新的匿名类型,该类型含有属性Name和AgeScope,而AgeScope需要通过计算Person的Age属性得到;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
using System;
using System.Collections.Generic;
using System.Linq;
namespace Advice18
{
internal class Program
{
static void Main(string[] args)
{
List<Person> personList2 = new List<Person>()
{
new Person() { Name = "Rose", Age = 19 },
new Person() { Name = "Steve", Age = 45 },
new Person() { Name = "Jessica", Age = 20 },
};
var pTemp = from p in personList2 select new { p.Name, AgeScope = p.Age > 20 ? "Old" : "Young" };
foreach (var item in pTemp)
{
Console.WriteLine(string.Format("{0}:{1}", item.Name, item.AgeScope));
}
}
}
class Person
{
public string Name { get; set; }
public int Age { get; set; }
}
}
|
建议20:使用泛型集合代替非泛型集合
我们知道,要想让代码能够高效的运行,应该尽量避免装箱和拆箱,以及尽量少的转型,很遗憾,在微软提供给我们的第一代集合类型中没有做到这一点,下面我们看ArrayList这个类的使用情况:
1
2
3
4
5
6
7
8
|
ArrayList al=new ArrayList();
al.Add(0);
al.Add(1);
al.Add("bomir");
foreach (var item in al)
{
Console.WriteLine(item);
}
|
上面这段代码充分演示了我们可以将程序写得多么糟糕。
首先,ArrayList的Add方法接受一个object参数,所以al.Add(1)首先会完成一次装箱;
其次,在foreach循环中,待遍历到它时,又将完成一次拆箱。
在这段代码中,整形和字符串作为值类型和引用类型,都会先被隐式地强制转型为object,然后在foreach循环中又被转型回来。同时,这段代码也是非类型安全的:我们然ArrayList同时存储了整型和字符串,但是缺少编译时的类型检查。虽然有时候需要有意这样去实现,但是更多的时候,应该尽量避免。缺少类型检查,在运行时会带来隐含的Bug。
集合类ArrayList如果进行如下所示的运算,就会抛出一个System.IvalidCastException (指定的转换无效):
1
2
3
4
5
6
7
8
9
10
|
ArrayList al = new ArrayList();
al.Add(0);
al.Add(1);
al.Add("bomir");
int t = 0;
foreach (int item in al)
{
t += item;
}
|
ArrayList同时还提供了一个带ICollection参数的构造方法,可以直接接收数组,如下所示:
var intArr = new int[] { 0, 1, 2, 3, 4 };
ArrayList a1 = new ArrayList(intArr);
该方法的内部实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
// Summary:
// Initializes a new instance of the System.Collections.ArrayList class that contains
// elements copied from the specified collection and that has the same initial capacity
// as the number of elements copied.
//
// Parameters:
// c:
// The System.Collections.ICollection whose elements are copied to the new list.
//
// Exceptions:
// T:System.ArgumentNullException:
// c is null.
public ArrayList(ICollection c)
{
if (c == null)
{
throw new ArgumentNullException("c", Environment.GetResourceString("ArgumentNull_Collection"));
}
int count = c.Count;
if (count == 0)
{
_items = emptyArray;
return;
}
_items = new object[count];
AddRange(c);
}
|
该AddRange方法最终调用了InsertRange方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
// Summary:
// Inserts the elements of a collection into the System.Collections.ArrayList at
// the specified index.
//
// Parameters:
// index:
// The zero-based index at which the new elements should be inserted.
//
// c:
// The System.Collections.ICollection whose elements should be inserted into the
// System.Collections.ArrayList. The collection itself cannot be null, but it can
// contain elements that are null.
//
// Exceptions:
// T:System.ArgumentNullException:
// c is null.
//
// T:System.ArgumentOutOfRangeException:
// index is less than zero. -or- index is greater than System.Collections.ArrayList.Count.
//
// T:System.NotSupportedException:
// The System.Collections.ArrayList is read-only. -or- The System.Collections.ArrayList
// has a fixed size.
public virtual void InsertRange(int index, ICollection c)
{
if (c == null)
{
throw new ArgumentNullException("c", Environment.GetResourceString("ArgumentNull_Collection"));
}
if (index < 0 || index > _size)
{
throw new ArgumentOutOfRangeException("index", Environment.GetResourceString("ArgumentOutOfRange_Index"));
}
int count = c.Count;
if (count > 0)
{
EnsureCapacity(_size + count);
if (index < _size)
{
Array.Copy(_items, index, _items, index + count, _size - index);
}
object[] array = new object[count];
c.CopyTo(array, 0);
array.CopyTo(_items, index);
_size += count;
_version++;
}
}
|
概括来讲,如果对大型集合进行循环访问、转型或装箱和拆箱操作,使用ArrayList这样的传统集合对效率影响会非常大。鉴于此,微软提供了对泛型的支持。泛型使用一对<>括号将实际类型括起来,然后编译器和运行时会完成剩余的工作。微软也不建议大家使用ArrayList这样的类型了,转而建议使用它们的泛型实现,如List。
注意,非泛型集合在System.Collections命名空间下,对应的泛型集合则在System.Collections.Generic命名空间下。
最后作者以ArrayList和List为例, 测试10000000次, 比较非泛型集合和泛型集合在运行中的效率:
输出为:
开始测试ArrayList:
耗时:2375
垃圾回收次数:26
开始测试List:
耗时:220
垃圾回收次数:5
可见这种情形, 使用泛型集合效率是比较占优的;
建议21:选择正确的集合
要选择正确的集合, 首先得回顾一下数据结构的知识,所谓数据结构,是指相互之间存在一种或多种特定关系的数据元素的集合。
集合的分类参考如下图:
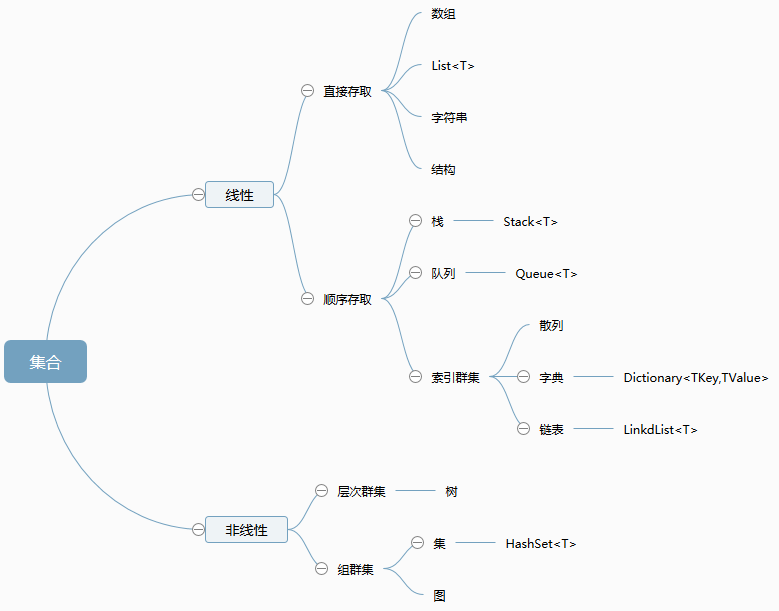
由于非泛型集合存在效率低以及非类型安全的特点, 因此我们聚焦在泛型集合上面;
如果集合的数目固定并且不涉及转型,使用数组的效率高,否则使用List;
线性表是线性结构,也是顺序存储结构。顺序存储需要开辟一个定长的空间,读写速度快,缺点不可扩充容量(如果要扩充需要开辟一个新的足够大的空间把原来的数据重写进去),链式存储无需担心容量问题,读写速度相对慢些,由于要存储下一个数据的地址所以需要的存储空间比顺序存储大。
如果元素个数已知,且插入删除较少的可以使用顺序结构,而对于频繁有插入删除操作,元素个数未知的,最好使用链式结构,编程时可结合要处理的数据的特点设计数据结构的。
例如队列Queue遵循的是先进先出模式,它在集合末尾添加元素,在集合的起始位置删除元素。根据队列的特点,可以用它来处理并发命令等场景:先让所有的客户端的命令入队,然后,由专门的工作线程来执行命令。在分布式中的消息队列就是一个典型的队列应用实例;
栈Stack遵循的是后进先出的模式,它在集合末尾添加集合,同时也在末尾删除元素;
字典Dictionary<Tkey, TValue>存储的是键值对,值在基于键的散列码的基础上进行存储。字典类对象由包含集合元素的存储桶组成,每一个存储桶与基于该元素的键的哈希值关联。如果需要根据键进行值的查找,使用Dictionary<TKey,TValue>将会是搜索和检索更快捷。
双向链表LinkedList是一个类型为LinkedListNode的元素对象的集合。当我们觉得在集合中插入和删除数据很慢时,可以考虑使用链表。如果使用LinkedList,我们会发现此类型并没有其他集合普遍具有的Add方法,取而代之的是AddAfter、AddBefore、AddFirst、AddLast等方法。双向链表的每个节点都向前指向Previous节点,向后指向Next节点。
还有几个类型:SortedList、SortedDictionary<TKye,TValue>、SortedSet,它们所对应的类分别是:List、Dictionary<TKye,TValue>、HashSet, 作用是将原来无序排列变为有序排列。
在命名空间System.Collections.Concurrent下,还涉及几个多线程集合类:ConcurrentBag、ConcurrentDictionary、ConcurrentQueue、ConcurrentStack,分别对应List、Dictionary<TKye,TValue>、Queue、Stack。在实际工作中,应该根据需要选择合适的集合类。
建议22:确保集合的线程安全
集合的线程安全是指多个线程在集合上添加或删除元素时,线程键必须保证同步;
下面代码模拟了一个线程在迭代过程中,另一个线程对元素进行了删除:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
using System;
using System.Collections.Generic;
using System.Threading;
namespace Advice
{
class Program
{
static List<Person> list = new List<Person>()
{
new Person() { Name = "Rose", Age = 19 },
new Person() { Name = "Steve", Age = 45 },
new Person() { Name = "Jessica", Age = 20 },
};
static AutoResetEvent autoSet = new AutoResetEvent(false);
static void Main(string[] args)
{
Thread t1 = new Thread(() =>
{
// 确保等待t2开始之后才运行下面的代码
autoSet.WaitOne();
foreach (var item in list)
{
Console.WriteLine("t1:" + item.Name);
Thread.Sleep(1000);
}
});
t1.Start();
Thread t2 = new Thread(() =>
{
// 确保等待t2开始之后才运行下面的代码
autoSet.Set();
// 沉睡1s是为了确保删除操作在t1的迭代过程中
Thread.Sleep(1000);
list.RemoveAt(2);
});
t2.Start();
}
}
class Person
{
public string Name { get; set; }
public int Age { get; set; }
}
}
|
以上代码运行过程会抛出InvalidOperationException:“集合已修改,可能无法执行枚举。”
早在泛型集合出现之前,非泛型集合一般提供一个SyncRoot属性,要保证非泛型集合的线程安全,可以通过锁定该属性来实现。如果上面的集合用ArrayList代替,保证其线程安全则应该在迭代和删除的时候都加上lock,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
class Program
{
static ArrayList list = new ArrayList()
{
new Person() { Name = "Rose", Age = 19 },
new Person() { Name = "Steve", Age = 45 },
new Person() { Name = "Jessica", Age = 20 },
};
static AutoResetEvent autoSet = new AutoResetEvent(false);
static void Main(string[] args)
{
Thread t1 = new Thread(() =>
{
// 确保等待t2开始之后才运行下面的代码
autoSet.WaitOne();
lock (list.SyncRoot)
{
foreach (Person item in list)
{
Console.WriteLine("t1:" + item.Name);
Thread.Sleep(1000);
}
}
});
t1.Start();
Thread t2 = new Thread(() =>
{
// 通知t1可以开始执行代码
autoSet.Set();
// 沉睡1s是为了确保删除操作在t1的迭代过程中
Thread.Sleep(1000);
lock (list.SyncRoot)
{
list.RemoveAt(2);
Console.WriteLine("删除成功");
}
});
t2.Start();
}
}
|
以上的代码不会抛出异常,因为锁定通过互斥的机制保证了同一时刻只能有一个线程操作集合元素。我们进而发现泛型集合没有这样的属性,必须要自己创建一个锁定对象来完成同步任务。可以new一个静态对象来进行锁定,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
static object syncObj = new object();
static void Main(string[] args)
{
Thread t1 = new Thread(() =>
{
// 确保等待t2开始之后才运行下面的代码
autoSet.WaitOne();
lock (syncObj)
{
foreach (var item in list)
{
Console.WriteLine("t1:" + item.Name);
Thread.Sleep(1000);
}
}
});
t1.Start();
Thread t2 = new Thread(() =>
{
// 通知t1可以开始执行代码
autoSet.Set();
// 沉睡1s是为了确保删除操作在t1的迭代过程中
Thread.Sleep(1000);
lock (syncObj)
{
list.RemoveAt(2);
Console.WriteLine("删除成功");
}
});
t2.Start();
|
建议23:避免将List作为自定义集合类的基类
如果要实现一个自定义的集合类,不应该以一个FCL集合类为基类,反而应该扩展相应的泛型接口;FCL集合类应该以组合的形式包含至自定义的集合类,需要扩展的泛型接口通常是IEnumerable和ICollection(或ICollection的子接口,如IList),前者规范了集合类的迭代功能,后者规范了一个集合通常会有的操作。
一般的情况下,下面实现的集合类都能完成默认的需求:
1
2
|
class Employees1 : List<Employee>
class Employees2 : IEnumerable<Employee>, ICollection<Employee>
|
不过,List基本上没有提供可供子类使用的protected成员(从object中继承的Finalize和MemberwiseClone方法除外),所以继承List不会带来任何继承上的优势,反而丧失了面向接口编程的灵活性,稍加不注意,隐藏的bug便会接踵而至了;
以Employees1为例,如果要在Add方法中加入某些需求方面的变化,比如,为名字添加一个后缀“Changed!",但是客户端的开发人员也许已经习惯了面向接口编程的方式,它在为集合添加一个元素是使用了如下的语法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
namespace Advice23
{
class Employee
{
public string Name { get; set; }
}
class Employees1 : List<Employee>
{
public new void Add(Employee item)
{
item.Name += " Changed";
base.Add(item);
}
}
class Program
{
static void Main(string[] args)
{
Employees1 employees1 = new Employees1()
{
new Employee() { Name = "Mike" },
new Employee() { Name = "Rose" },
};
IList<Employee> employees = employees1;
employees.Add(new Employee() { Name = "Steve" });
foreach (var item in employees1)
{
Console.WriteLine(item.Name);
}
}
}
}
|
于是, 代码的实际输出会偏离集合类的设计者的设想;输出如下:

如果要修正这类行为,应该采用Employee2的方式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
class Employees2 : IEnumerable<Employee>, ICollection<Employee>
{
List<Employee> items = new List<Employee>();
public IEnumerator<Employee> GetEnumerator()
{
return items.GetEnumerator();
}
public void Add(Employee item)
{
item.Name += " Changed!";
items.Add(item);
}
public int Count => throw new NotImplementedException();
public bool IsReadOnly => throw new NotImplementedException();
public void Clear()
{
throw new NotImplementedException();
}
public bool Contains(Employee item)
{
throw new NotImplementedException();
}
public void CopyTo(Employee[] array, int arrayIndex)
{
throw new NotImplementedException();
}
public bool Remove(Employee item)
{
throw new NotImplementedException();
}
IEnumerator IEnumerable.GetEnumerator()
{
throw new NotImplementedException();
}
}
|
输出的结果为:
建议24:迭代器应该是只读的
如果留心观察就会注意到,FCL(Framework class library)中的迭代器只有GetEnumerator方法,没有SetEnumerator方法,所有的集合类也没有一个可以写的迭代器属性。原因有二:
- 这违背了设计模式的开闭原则;被设置到集合中的迭代器可能会直接导致集合的行为发生异常或变动;一旦确实需要新的迭代要求,完全可以创建一个新的迭代器来满足需求,而不是为集合设置该迭代器,因为这样做会直接导致使用该集合对象的其他迭代场景发生不可知的行为;
- 我们有了LINQ,使用LINQ现在不用创建任何新的类型就能满足任何的迭代需求;
如果迭代器可写,危害的demo如下:
假设存在一个公共的集合对象,有两个业务类需要对这个集合进行操作:
业务类A只负责将元素迭代显示到UI上:
1
2
3
4
5
6
7
|
private IMyEnumerable list = new MyList();
private IMyEnumerator enumerator = list.GetEnumerator();
while(enumerator.MoveNext())
{
int current = enumerator.Current;
Console.WriteLine(current.ToString());
}
|
业务类B出于自己的某种需求,要实现一个新的针对集合对象的迭代器:
1
2
3
4
5
6
7
|
private MyEnumerator2 enumerator2 = new MyEnumerator2(list as MyList);
(list as MyList).SetEnumerator(enumerator2);
while(enumerator2.MoveNext())
{
int current = enumerator2.Current;
Console.WriteLine(current.ToString());
}
|
现在再回到业务A类上执行一次迭代,结果将会是B所设置的迭代器输出。这相当于B在没有通知A的情况下产生了干扰,这是应该避免的;
1
|
(list as MyList).SetEnumerator(enumerator2);
|
事实上,上面的代码即使没有下面这行代码也会运行得很好;
所以,不要为迭代器设置可写属性;
建议25:谨慎集合属性的可写操作
如果类型的属性中有集合属性,那么应该保证属性对象是由类型本身产生的。如果将属性设置为可写,则会增加抛出异常的几率;一般情况下,如果集合属性没有值,则它返回的Count等于0,而不是集合属性的值为null。下面的代码将产生一个NullReferenceException异常:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
namespace Advice25
{
class Program
{
static List<Student> studentList = new List<Student>()
{
new Student() { Name = "mike", Age = 11 },
new Student() { Name = "Rose", Age = 21 }
};
static void Main(string[] args)
{
StudentTeamA teamA = new StudentTeamA();
Thread t1 = new Thread(() =>
{
teamA.Students = studentList;
Thread.Sleep(3000);
// 模拟对集合属性进行一些运算
Console.WriteLine(studentList.Count);
});
t1.Start();
Thread t2 = new Thread(() =>
{
// 模拟在别的地方对list而不是属性本身赋值为null
studentList = null;
});
t2.Start();
}
}
class Student
{
public string Name { get; set; }
public int Age { get; set; }
}
class StudentTeamA
{
public List<Student> Students { get; set; }
}
}
|
上面代码的问题是:线程t1模拟将对类型StudentTeamA的Students属性进行赋值,它是一个可读/可写的属性。由于集合属性是一个引用类型,而当前针对该属性对象的引用却又两个,即集合本身和调用者的类型变量studentList,线程t2也许是另一个程序员写的,但他看到的只有studentList,结果,针对studentList的修改hi直接影响到另一个工作线程的对象。在例子中,我们将studentList赋值为null,模拟在StudentTeamA(或者说工作线程t1)不知情的情况下使得集合属性变为null。接着,线程t1模拟针对Students属性进行若干操作,导致抛出异常。
下面的StudentTeamA版本是一个改进过的版本。首先,将类型的集合属性设置为只读;其次,集合对象由类型自身创建,这保证了集合属性永远只有一个引用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
namespace Advice25
{
class Program
{
static List<Student> studentList = new List<Student>()
{
new Student() { Name = "mike", Age = 11 },
new Student() { Name = "Rose", Age = 21 }
};
static void Main(string[] args)
{
StudentTeamA teamA = new StudentTeamA();
teamA.Students.Add(new Student() { Name = "Steve", Age = 22 });
teamA.Students.AddRange(studentList);
Console.WriteLine(teamA.Students.Count);
// 也可以像下面一样实现
StudentTeamA teamA1 = new StudentTeamA(studentList);
Console.WriteLine(teamA1.Students.Count);
}
}
class Student
{
public string Name { get; set; }
public int Age { get; set; }
}
class StudentTeamA
{
public List<Student> Students { get; private set; }
public StudentTeamA()
{
Students = new List<Student>();
}
public StudentTeamA(IEnumerable<Student> studentList) : this()
{
Students.AddRange(studentList);
}
}
}
|
在改进版本的StudentTeamA中尝试对属性Students进行赋值:
1
|
teamA.Students = listStudent;
|
这将会导致编译通不过;
建议26:使用匿名类型存储LINQ查询结果
从.NET3.0开始,C#开始支持一个新特性:匿名类型。匿名类型有var、赋值运算符和一个非空初始值(或以new开头的初始化项)组成。匿名类型有如下基本特性:
- 即支持简单类型也支持复杂类型。简单类型必须是一个非空初始值,复杂类型则是一个以new开头的初始化项。
- 匿名类型的属性是只读的,没有属性设置器,它一旦被初始化就不可更改。
- 如果两个匿名类型的属性值相同,那么就认为这两个匿名类型相等。
- 匿名类型可以在循环中用作初始化器。
- 匿名类型支持智能感知。
- 匿名类型可以拥有方法。
在类型仅仅被当前的代码使用,或者被用于存储某种查询结果的场景中,匿名类型的用途会很大。匿名类型是保存LINQ查询结果的最佳搭档;
如下场景:
将Person或Person相关类(如Company)从数据库中取出来,我们需要将Person中的属性Name和根据CompanyID对应起来的Company的属性Name联系起来,形成一个新的类型。这个新的类型也许用于某个UI控件的绑定源,也许用于某个特殊算法的输入。总之,数据库中的格式一旦设计完毕并投入使用,很少会有变动,但是需求却千变万化,实际需求需要创建很多这样的临时类型。如果这临时类型全部使用普通的自定义类型,代码将会膨胀起来变得难以维护。这个时候,匿名类型就派上用场了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
using System;
using System.Collections.Generic;
using System.Linq;
namespace Advice26
{
class Program
{
static void Main(string[] args)
{
//为了演示需要companyList并不从数据库读取,而是直接赋值
List<Company> companyList = new List<Company>()
{
new Company(){ ComanyID = 0, Name = "Microsoft" },
new Company(){ ComanyID = 1, Name = "Google" }
};
//为了演示需要personList并不从数据库读取,而是直接赋值
List<Person> personList = new List<Person>()
{
new Person(){ Name = "Mike", CompanyID = 1 },
new Person(){ Name = "Rose", CompanyID = 0 },
new Person(){ Name = "Steve", CompanyID = 1 }
};
var personWithCompanyList = from person in personList
join company in companyList on person.CompanyID equals company.ComanyID
select new { PersonName = person.Name, CompanyName = company.Name };
foreach (var item in personWithCompanyList)
{
Console.WriteLine(string.Format("{0}\t:{1}", item.PersonName, item.CompanyName));
}
}
}
class Person
{
public string Name { get; set; }
public int CompanyID { get; set; }
}
class Company
{
public int ComanyID { get; set; }
public string Name { get; set; }
}
}
|

我们用ildasm查看IL的代码,可以看见匿名类型在IL中会生成 一个类, 也称之为投影;

非匿名类型包括的Equals、GetHashcode、ToString等方法匿名类型都有。并且编译器为我们重载了ToString方法,它返回的是类型的属性即对应的值。
建议27:在查询中使用Lambda表达式
LINQ实际上是基于扩展方法和lambda表达式的,任何LINQ的查询都能通过扩展方法的方式来代替:
1
2
3
4
5
6
|
var personWithCompanyList = from person in personList
select new { PersonName = person.Name, CompanyName = person.CompanyID == 0 ? "Micro" : "Sun" };
foreach (var person in personWithCompanyList)
{
Console.WriteLine(person.ToString());
}
|
其等价于:
1
2
3
4
|
foreach (var item in personList.Select( person=>new { PersonName=person.Name,CompanyName=person.CompanyID==0?"Micro":"Sun"}))
{
Console.WriteLine(item.ToString());
}
|
针对LINQ设计的扩展方法大多应用了泛型委托。System命名空间定义了泛型委托Action, Func和Predicate。Action用于执行一个动作,所以它没有返回值;Func用于执行一个操作并返回一个值;Predicate用于定义一组条件并判读参数是否符合条件。
Select扩展方法接受的就是一个Func委托,而Lambda表达式就是一个简洁的委托,运算符“=>”左边代表的是方法的参数,右边的是方法体。我们通过直接调用扩展方法来使用Lambda表达式,这样即完成了功能,也减少了一行代码。在实际工作中,应该灵活运用这种方式。
1
2
3
4
|
foreach (var item in personWithCompanyList.Where(p => p.CompanyName == "Sun"))
{
Console.WriteLine(item.PersonName);
}
|
调用OrderByDescending扩展方法, 针对PersonName进行排序:
1
2
3
4
|
foreach (var item in personList.OrderByDescending(person => person.Name))
{
Console.WriteLine(item.Name);
}
|
建议28:理解延迟求值和主动求值之间的区别
要理解延迟求值(lazy evaluation)和主动求值(eager evaluation),先看个demo:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
using System;
using System.Collections.Generic;
using System.Linq;
namespace Advice28
{
internal class Program
{
static void Main(string[] args)
{
List<int> list = new List<int> { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 };
var temp1 = from c in list where c > 5 select c;
var temp2 = (from c in list where c > 5 select c).ToList();
list[0] = 11;
Console.WriteLine("temp1: ");
foreach (var item in temp1)
{
Console.WriteLine(item + " ");
}
Console.WriteLine("temp2: ");
foreach (var item in temp2)
{
Console.WriteLine(item+ " ");
}
}
}
}
|
在延迟求值的情况下, 只是定义了一个查询,而不会立刻执行;对查询的访问每次都会遍历原集合,如这个例子中的temp1的迭代,在迭代前我们修改了list[0]的值,可见,修改直接影响了迭代的输出。对查询结果调用ToList、ToArray等方法,将会使其立即执行,由于对list[0]的修改是在temp2查询之后进行的,所以针对list[0]的修改不会影响到temp2的结果;
在使用LINQ to SQL时候,延迟求值能带来显著的性能提升。例如,如果定义了两个查询,而且采用了延迟求值,CLR会合并两次查询并生成一个最终的查询;
事实上,应该仔细体会延迟求值和主动求值的差别,去体会在具体应用中带来的输出结果;不然我们可能会遭遇到意想不到的bug;
建议29:区别LINQ查询中的IEnumerable和IQueryable
查询一共提供了两类i扩展方法,在System.Linq的命名空间下,有两个静态类:Enumerable类,它针对继承了IEnumerable接口的集合进行扩展;Queryable类,它针对继承了IQueryable接口的集合类进行扩扎。接口IQueryable也是继承了IEnumerable接口的,所以,致使两个接口的方法在很大程度上时一致的。
LINQ查询从功能上来讲实际上可分为3类:
- LINQ to OBJECTS
- LINQ to SQL
- LINQ to XML
设计两套接口的目的在于区分LINQ to OBJECTS,LINQ TO SQL , 两者对于查询的结果在内部使用的是完全不同的机制。
针对LINQ to OBJECTS时,使用Enumerable中的扩展方法对本地集合进行排序和查询等操作,查询参数接受的是Func<>。Func<>叫做谓语表达式,相当于一个委托。针对LINQ to SQL时,则使用Queryable中的扩展方法,它接受的是Expression<>。Expression<>用于包装Func<>。LINQ to SQL最终会将表达式树转换成相应的SQL语句,然后在数据库中执行。
简单的说:本地数据源用IEnumerable,远程数据源用IQueryable。
在使用IEnumerable和IQueryable的时候还需要注意,IEnumerable查询的逻辑可言直接用我们自定义的方法,而IQueryable则不能使用自定义的方法,它必须先生成表达式树,查询由LINQ to SQL引擎处理。在使用IQueryable查询的时候,若果使用自定义方法,则会抛出异常。
1
2
3
4
5
6
7
|
DataContext ctx = new DataContext("server=192.168.0.102;database=Temp;uid=sa;pwd=sa123");
Table<Person> persons = ctx.GetTable<Person>();
var temp1 = from p in persons where OlderThan20(p.Age) select p;
foreach (var item in temp1)
{
Console.WriteLine(string.Format("Name:{0}\tAge:{1}", item.Name, item.Age));
}
|
这将会抛出异常NotSupportedException:方法“Boolean OlderThan20(Int32)”不支持转换为SQL。
但是,如果我们将查询转换成一个IEnumerable查询,这种模式是支持的:
建议30:使用LINQ取代集合中的比较器和迭代器
LINQ提供了类似SQL语句的语法来实现遍历,筛选与投影集合的功能;
1
2
3
4
5
6
7
8
9
10
|
List<Salary> companySalary = new List<Salary>()
{
new Salary() { Name = "Mike", BaseSalary = 3000, Bonus = 1000 },
new Salary() { Name = "Rose", BaseSalary = 2000, Bonus = 4000 },
new Salary() { Name = "Jeffry", BaseSalary = 1000, Bonus = 6000 },
new Salary() { Name = "Steve", BaseSalary = 4000, Bonus = 3000 }
};
var orderByBaseSalary = from s in companySalary orderby s.BaseSalary select s;
var orderByBonus = from s in companySalary orderby s.Bonus select s;
|
foreach实际隐含调用的是集合对象orderByBaseSalary和orderByBouns的迭代器。以往,如果我们要绕开集合的Sort方法对集合按照一定的顺序进行迭代,则需要让类型继承IEnumerable接口(泛型集合是IEnumerable接口),实现一个或多个迭代器。现在从LINQ查询生成匿名类来看,相当于可以无限为集合增加迭代需求。
我们可以利用LINQ的强大功能来简化我们的代码,但是LINQ功能的实现本身就是借助FCL泛型集合的比较器、迭代器、索引器的。LINQ相当于封装了这些功能,让我们使用起来更加方便。在命名空间System.Linq下存在很多静态类,这些静态类存在的意义就是为FCL的泛型集合提供扩展方法。
这条语句:
1
|
var orderByBaseSalary = from s in companySalary orderby s.BaseSalary select s;
|
orderby实际上是调用了System.Linq.Enumerable类型的OrderBy方法:
1
2
3
4
|
public static IOrderedEnumerable<TSource> OrderBy<TSource, TKey>(this IEnumerable<TSource> source, Func<TSource, TKey> keySelector)
{
//省略
}
|
这是一个扩展方法,它为继承了IEnumerable接口的集合类型提供排序的功能。
作者老师在这条建议中强烈推荐我们利用LINQ所带来的的便捷性,但是我们仍需掌握比较器、迭代器、索引器的原理,以便更好的理解LINQ的思想,写出更高质量的代码;
建议31:在LINQ查询中避免不必要的迭代
无论是SQL查询还是LINQ查询,搜索到结果立刻返回总比搜索完所有的结果再将结果返回的效率要更高;现在来创建一个自定义的集合类型来说明:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
|
using System;
using System.Collections;
using System.Collections.Generic;
using System.Linq;
namespace Advice31
{
class Program
{
static void Main(string[] args)
{
MyList list = new MyList();
var temp = (from c in list where c.Age == 20 select c).ToList();
Console.WriteLine(list.IteratedNum.ToString());
list.IteratedNum = 0;
var temp2 = (from c in list where c.Age >= 20 select c).First();
Console.WriteLine(list.IteratedNum.ToString());
list.IteratedNum = 0;
}
}
class MyList : IEnumerable<Person>
{
public IEnumerator<Person> GetEnumerator()
{
foreach (var item in list)
{
IteratedNum++;
yield return item;
}
}
IEnumerator IEnumerable.GetEnumerator()
{
return GetEnumerator();
}
List<Person> list = new List<Person>()
{
new Person(){ Name = "aehyok", Age = 23 },
new Person(){ Name = "kris", Age = 20 },
new Person(){ Name = "leo", Age = 25 },
new Person(){ Name = "niki", Age = 21 },
};
public int IteratedNum { get; set; }
public Person this[int i]
{
get { return list[i]; }
set { this.list[i] = value; }
}
}
public class Person
{
public string Name { get; set; }
public int Age { get; set; }
}
}
|
通过结果发现,第二种的性能明显要比第一种的性能要好很多;第一种查询用了4次,而第二种仅有1次;
与First方法类似的还有Take方法,Take方法接收一个整型参数,然后为我们返回该参数指定的元素个数。与First一样,它满足条件以后,会从当前的迭代过程直接返回,而不是等到整个迭代过程完毕再返回。如果一个集合包含了很多的元素,那么这种查询会为我们带来可观的时间效率。
再来看下面的例子,虽然LINQ查询的最后结果都是返回包含了两个元素"Niki"对象,但是实际上,使用Take方法仅仅为我们迭代了2次,而使用where查询方式带来的确实整个集合的迭代,首先修改一下集合类中的元素:
1
2
3
4
5
6
7
8
|
List<Person> list = new List<Person>()
{
new Person(){ Name="Niki",Age=25},
new Person(){ Name="Niki",Age=30},
new Person(){ Name="Kris",Age=20},
new Person(){ Name="Leo",Age=25},
new Person(){ Name="aehyok",Age=30}
};
|
调用:
1
2
3
4
5
6
7
8
|
var temp = (from c in list select c).Take(2).ToList();
Console.WriteLine(list.IteratedNum.ToString());
list.IteratedNum = 0;
var temp2 = (from c in list where c.Name == "Niki" select c).ToList();
Console.WriteLine(list.IteratedNum.ToString());
Console.ReadLine();
|
在实际的代码中,应充分的应用First和Take等方法,这样才能为我们的应用带来高效性,而不会让时间耗费在一些无效的迭代中;