高并发处理框架—Tornado
Tornado介绍
Tornado是一个可扩展的非阻塞式Web服务器及其相关工具的开源版本。Tornado每秒可以处理数以千计的;连接,对于实时的Web服务来说,Tornado是一个理想的Web框架。
Tornado是使用Python编写的一个强大的可扩展的Web服务器,它在处理高网络流量时表现得足够强健,却在创建和编写时有着足够的轻量级,并且能够被用在大量的应用和工具中。相比于其他的Python网络框架,Tornado有如下特点。
-
完备的Web框架:与Django,Flask等一样,Tornado也提供了URL路由映射、Request上下文、基于模板的页面渲染技术等开发Web应用的必备工具。
-
是一个高效的网络库,性能与Twisted、Gevent等底层Python框架相媲美:提供了异步I/O支持、超时事件处理。这使得Tornado除了可以作为Web应用服务器框架,还可以用来做爬虫应用、物联网关、游戏服务器等后台应用。
-
提供高效的HTTPClient:除了服务器端框架,Tornado还提供了基于异步框架的HTTP客户端。
-
提供高效的内部HTTP服务器:虽然其他Python网络框架(Django,Flask)也提供了内部HTTP服务器,但它们的HTTP服务器由于性能原因只能用于测试环境。而Tornado的HTTP服务器与Tornado异步调用紧密结合,可以直接用于生产环境。
-
完备的WebSocket支持:WebSocket是HTML5的一种新标准,实现了浏览器与服务器之间的双向实时通信。
因为Tornado的上述特点,Tornado常被用作大型站点的接口服务框架,而不像Django那样着眼于建立完整的大型网站,着重讲解Tornado的异步及协程编程、身份认证框架、独特的非WSGI部署方式。
安装Tornado
Tornado已经被配置到PyPI网站中,使得Tornado的安装非常简单。在Windows和Linux中都可以通过一条pip命令来完成安装。
pip install tornado
该条命令可以运行在操作系统中或python虚环境中。安装信息如下图所示:
异步及协程基础
协程是Tornado中推荐的编程方式,使用协程可以开发出简捷,高效的异步处理代码。本章从同步I/O、异步I/O开始,逐步理解和掌握基于Tornado协程的编程技术。
同步和异步I/O
从计算机硬件发展的角度来看,当今计算机系统的CPU和内存发展速度日新月异,摩尔定律体现的十分明显。与之同时的硬盘、网络等于I/O相关的速度指标却进度缓慢。因此,在如今的计算机应用开发中,减少程序在I/O操作中的等待是对资源消耗、提高并发程度的必要考虑。
根据Unix Network Programing 一书中的定义,同步I/O操作(synchronous I/O operation)导致请求进程阻塞,直到I/O操作完成;异步I/O操作(asynchronous I/O operation)不导致请求进程阻塞。在Python中,同步I/O可以被理解为一个被调用的I/O函数会阻塞调用函数的执行,而异步I/O则不会阻塞调用函数的执行。代码举例如下:
|
|
HTTPClient是Tornado的同步访问HTTP客户端。上述代码中的synchronous_visit()函数使用了典型的同步I/O操作访问www.baidu.com网站,该函数的执行时间取决于网络速度、对方服务器响应速度等,只有等到对www.baidu.com的访问完成后并获取到结果后,才能完成对synchronous_visit函数的执行。
而使用异步I/O访问www.baidu.com网站的函数无需等待访问完成才能返回,譬如:
|
|
AsyncHTTPClient是Tornado的异步访问HTTP客户端。在上述代码的asynchronous_visit函数中使用AsyncHTTPClient对第三方网站进行异步访问,http_client.fetch()函数会在调用后立刻返回而无需等待实际返回的完成,从而导致asynchronous_visit()也会立刻执行完成。当对www.baidu.com的访问实际完成后,AsyncHTTPClient会调用callback参数指定的函数,开发者可以在其中写入处理访问结果的逻辑代码。
yield关键字
协程是Tornado中进行异步I/O代码开发的方法,协程使用了Python的关键字yield将调用者挂起和恢复执行。在理解协程概念前,应首先理解Python中yield关键字的概念和使用方法,而学习yield之前需要了解迭代器的概念。
1. 迭代器
迭代器(Iterator)是访问集合内元素的一种方式。迭代器对象从集合的第1个元素开始访问,直到所有元素都被访问一遍后结束。迭代器不能回退,只能往前进行迭代。
Python中最常使用迭代器的场景是循环语句for,它用迭代器封装集合,并且逐个访问集合元素以执行循环体。比如:
|
|
其中的range()返回一个包含所指定元素的集合,而for语句将其封装一个迭代器后访问,使用iter()调用可以将列表、集合转换为迭代器,比如:
|
|
其中,t就是迭代器。迭代器与普通的Python对象的区别是迭代器有一个next()方法,每次调用该方法可以返回一个元素。调用者可以通过不断调用next()方法来逐个访问集合元素。比如:
|
|
调用者可以一直这样调用next()方法来访问迭代器,直到next()方法返回StopIteration异常以表示迭代已经完成,比如:
|
|
2. 使用yield
迭代器在Python编程中适用范围很广,开发者可以使用yield定制自己的迭代器。调用任何定义中包含yield关键字的函数都不会执行该函数,而是会获得一个对应该函数的迭代器。
|
|
执行该部分代码结果如下:
|
|
每次调用迭代器的next()函数,将执行迭代器函数。并返回yield的结果作为迭代返回元素。当迭代器函数return时,迭代器会抛出StopIteration异常使迭代终止。
注:在Python中,使用yield关键字定义的迭代器也被称为"生成器"。
协程
使用Tornado协程可以开发出类似同步代码的异步行为,并且因为协程本身不使用线程,所以减少了线程上下文切换的开销,是一种更为高效的开发模式。
1. 编写协程函数
使用协程技术开发网页访问的代码如下:
|
|
本例中仍然使用异步客户端AsyncHTTPClient进行页面访问,使用@gen.coroutine表明用装饰器声明这是一个协程函数。由于yield关键字的使用,使得代码中不用再编写回调函数用于处理访问结果,而可以直接在yield语句的后面编写结果处理语句。
2. 编写协程函数
由于Tornado协程基于Python的yield关键字实现,所以不能像调用普通函数一样调用协程函数。 协程函数可以通过以下三种方式进行调用。
-
在本身是协程的函数内通过yield关键字调用。
-
在IOLoop尚未启动时,通过IOLoop的run_sync()函数调用。
-
在IOLoop已经启动时,通过IOLoop的spawn_callback()函数调用。
举一个“通过协程函数调用协程函数”的例子:
|
|
本例中coroutine_visit和outer_coroutine都是协程函数,所以它们之间可以通过yield关键字进行调用。IOLoop是Tornado的主事件循环对象,Tornado程序通过它监听外部客户端的访问请求,并执行相应的操作。当程序尚未进入IOLoop的running状态时,可以通过run_sync()函数调用协程函数。比如:
|
|
此处无需过分了解IOLoop,后面会逐步了解IOLoop的具体概念及应用方法。
上例中引用tornado.ioloop包中的IOLoop对象,之后在普通函数中使用run_sync()函数调用经过lambda封装的协程函数。run_sync()函数将阻塞当前函数的执行,直到被调用的协程执行完成。
事实上,Tornado要求协程函数在IOLoop的runing状态中才能被调用,只不过run_sync函数自动完成了启动、停止IOLoop的步骤,它的实现逻辑为:启动IOLoop—>调用被lambda封装的协程函数—>停止IOLoop。当Tornado程序已经处于running状态时的协程函数的调用示例如下:
|
|
本例中spawn_callback()函数将不会等待被调用协程执行完成。所以spawn_callback()之前和之后的print语句将会被连续执行,而coroutine_visit本身将会由IOLoop在合适的时机进行调用。
IOLoop的spawn_callback()函数没有为开发者提供获取协程函数调用返回值的方法,所以只能用spawn_callback()调用没有返回值的协程函数。
3. 在协程中调用阻塞函数
在协程中直接调用阻塞函数会影响协程本身的性能,所以Tornado提供了在协程中利用线程池调度阻塞函数,从而不影响协程本身继续执行的方法。示例如下:
|
|
代码中首先引用了concurrent.futures中的ThreadPoolExecutor类,并实例化了一个有两个线程的线程池thread_pool。在需要调用阻塞函数的协程call_blocking中,使用thread_pool.submit调用阻塞函数,并通过yield返回。这样便不会阻塞协程所在线程的继续执行,也保证了阻塞函数前后代码的执行顺序。
4. 在协程中等待多个异步调用
目前只讲述了协程中一个yield关键字等待一个异步调用,实际上tornado允许在协程中用一个yield关键字等待多个异步调用,只需要把这些调用用列表(list)或字典(dictionary)的方式传递给yield关键字即可。
使用列表方式传递多个异步调用的示例代码如下:
|
|
在代码中仍然用@gen.coroutine装饰器定义协程,在需要yield的地方用列表传递若干个异步调用,只有在列表中的所有调用都执行完成后,yield才会返回并继续执行。yield以列表形式返回N个调用的输出结果,可以通过for语句逐个访问。
使用字典方式传递多个异步调用的示例代码如下:
|
|
本例中以字典形式给yield关键字传递异步调用要求,并且Tornado以字典形式返回异步调用的结果。
Tornado框架知识
Tornado概述
Tornado全称是Tornado Web Server,是一个用Python语言写成的Web服务器兼网络框架。特点和性能总结如下:
特点:
-
轻量级的Web框架,其拥有异步非阻塞IO的处理方式。
-
作为Web服务器,Tornado有较为出色的抗负载能力,官方用Nginx反向代理的方式部署Tornado和其它Python Web应用框架,为了最大化的利用Tornado的性能,推荐同时使用tornado和其它Python Web应用框架进行对比,结果最大浏览量超过第二名近40%.
性能:
-
Tornado性能优异,它试图解决 C10K问题,即处理大于或等于一万的并发连接。
Tornado框架和服务器一起可以组成一个WSGI的全栈替代品,如果单独在WSGI容器中使用tornado网络框架或者tornaod http服务器 ,存在一定的局限性。为了最大化的利用tornado的性能,推荐同时使用tornado+HTTP服务器。
应用场景
-
用户量大,高并发
如秒杀抢购,双11某宝购物、春节抢火车票等。
-
大量的HTTP持久连接
使用同一个TCP连接来发送和接收多个HTTP请求 or 应答,而不是为每一个请求 or 应答打开新的连接的方法。
对于HTTP 1.0,可以在请求的包头(Header)中添加Connection:Keep-Alive。
对于HTTP 1.1,所有的连接默认为持久连接。
Tornado与Django比较
Tornado
Tornado走的是少而精的方向,注重的是性能优越,最为出名的是它的异步非阻塞的设计方式。
-
HTTP服务器
-
异步编程
-
WebSocket
Djangoo
Django走的是大而全的方向,注重开发高效,最为出名的是它自动化的管理后台,只需要使用起ORM,做简单的对象定义,它就能自动生成数据库,以及功能齐全的管理后台。
Django所提供的方便,意味着Django内置的ORM跟框架内的其他模块耦合度高,应用程序必须使用Django内置的ORM,否则就不能享受到框架内提供的种种基于ORM的便利。
-
Session功能
-
后台管理
-
ORM
简单Tornado示例
|
|
上述代码解释说明:
tornado的基础Web框架模块
-
RequestHandler
封装了对应一个请求的所有信息和方法,write(响应信息)就是写响应信息的一个方法;对应每一种http请求方式(get、post等),把对应的处理逻辑写进同名的成员方法中(如对应get请求方式,就将对应的处理逻辑写在get()方法中),当没有对应请求方式的成员方法时,会返回“405: Method Not Allowed”错误。
-
Application
Tornado Web框架的核心应用类,是与服务器对接的接口,里面保存了路由信息表,其初始化接收的第一个参数就是一个路由信息映射元组的列表;其listen(端口)方法用来创建一个http服务器实例,并绑定到给定端口(注意:此时服务器并未开启监听)。
Tornado核心IOLoop循环模块
tornado的核心io循环模块,封装了Linux的epoll和BSD的kqueue,也是tornado高性能的基石。以Linux的epoll为例,其原理如下图:
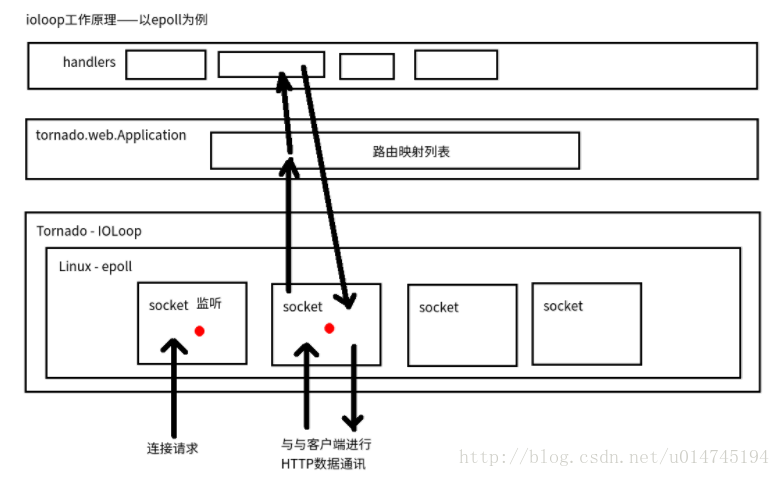
针对具体实例,访问路径如下图:
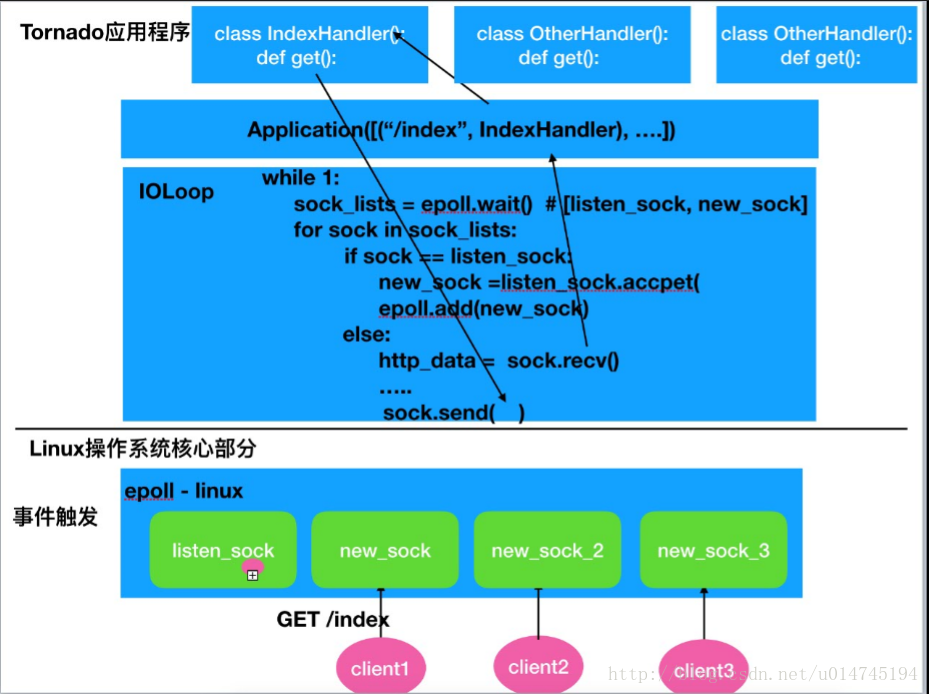
- IOLoop.current()返回当前线程的IOLoop实例。
- IOLoop.start() 启动IOLoop实例的I/O循环,同时服务器监听被打开。
2.6 Tornado Web程序编写思路
- 创建Web应用实例对象,第一个初始化参数为路由映射列表。
- 定义实现路由映射表中的handler类。
- 创建服务器实例,绑定服务器端口。
- 启动当前线程的IOLoop。
开发Tornado网站
下面会展示使用Tornado建立Web站点的方法。
网站结构
通过编写hellowowld学习Tornado网站的基本结构:
|
|
下面逐行解析上面的代码做了些什么。
(1) 首先是通过import语句引入tornado包中ioloop和web类。引入这两个类是Tornado程序的基础。
(2) 实现一个web.RequestHandler子类,重载其中的get()函数,该函数负责相应定位到该Request
Handler的HTTP GET请求的处理。本例中简单的使用self.write()函数输出hello world。
(3) 定义了make_app()函数,该函数返回一个web.Application对象。该对象的第1个参数用于定义Tornado程序的路由映射。本例中将对根URL的访问映射到了RequestHandler子类MainHandler中。
(4) 用web.Application.listen()函数指定服务器监听的端口。
(5) 用tornado.ioloop.IOLoop.current().start()启动IOLoop,该函数将一直运行且不退出,用于处理完所有的客户端的访问请求。
路由解析
向web.Application对象传递的第1个参数URL路由映射列表的配置方式与Django类似,用正则字符串进行路由匹配。Tornado的路由字符串有两种,固定字符路径和参数字串路径。
-
固定字串路径
固定子串是普通的字符串固定匹配,比如:
|
|
- 参数字串路径
参数字串可以将具备一定模式的路径映射到同一个RequestHandler中处理,其中路径中的参数部分用小括号"()“标识,下面是一个参数路径的例子:
|
|
例中用 "/entry/([^/]+)" 定义以/entry/开头的URL模式。小括号的内容是正则表达式,URL尾部的变量部分以参数形式传递给RequestHandler中的get()函数,本例中将该参数命名为slug。
- 带默认值的参数路径
之前例子中的handlers = [(r"/entry/([^/]+)",EntryHandler),]模式定义了客户端必须输入路径参数。比如,其能够匹配如下路径:
|
|
但是其无法匹配,http://xx.xx.xx.xx/entry ,
对于需要匹配客户端未传入时的路径,则需要用如下方法改变URL路径和对get()函数的定义:
|
|
本例中首先用星号”*“取代加号”+“定义了URL模式,然后为RequestHandler子类的get()函数的slug参数配置了默认值default。
-
多参数路径
参数路径还允许在一个URL模式中定义多个可变参数,比如:
|
|
本例中的URL模式定义了year、month、day、slug等4个参数。
RequestHandler
经过前面的学习,大致了解到RequestHandler类在Tornado网站程序中的重要作用,它是配置和响应URL请求的核心类,下面将介绍RequestHandler的更多内容。
- 接入点函数
需要子类继承并定义具体行为的函数在RequestHandler中被称为接入点函数(Entry Point),之前常用的get()函数就是典型的接入点函数。其它可用的接入点函数如下所述。
(1)RequestHandler.initialize()
该方法被子类重写,实现了RequestHandler子类实例的初始化过程。可以将该函数传递参数,参数来源于配置URL映射时的定义。比如:
|
|
本例中的initialize有参数database,该参数由Application定义URL映射时以dict形式给出。
(2)RequestHandler.prepare()、RequestHandler.on_finish()
prepare()方法用于调用请求处理(get、post等)方法之前的初始化处理,而on_finish()用于请求处理结束后的一些清理工作,这两种方法一个在处理前,一个在处理后,可以根据实际需要进行重写。通常prepare()方法做资源初始化操作,而用on_finish()方法可做清理对象占用的内存或者关闭数据库连接等工作。
(3)HTTP Action处理函数
每个HTTP Action在RequestHandler中都以单独的函数进行处理。
-
RequestHandler.get(*args,**kargs)
-
RequestHandler.head(*args,**kargs)
RequestHandler.post(*args,**kargs)
-
RequestHandler.delete(*args,**kargs)
-
RequestHandler.patch(*args,**kargs)
-
RequestHandler.put(*args,**kargs)
RequestHandler.options(*args,**kargs)
每个处理函数都以它们对应的HTTP Action小写的方式命名。
输入捕获
输入捕获是指在RequestHandler中获取客户端输入的工具函数和属性,比如获取URL查询字符串、POST提交参数等。
(1)RequestHandler.get_argument(name)、RequestHandler.get_arguments(name)
都是返回给定参数的值。get_argument获得单个值;而get_arguments是针对参数存在多个值的情况下使用的,返回多个值的列表。用get_argument/get_arguments()方法获取的是URL查询字符串参数与Post提交参数的参数合集。
(2) RequestHandler.get_query_argument(name)、RequestHandler.get_query_argument
(name)
它们与get_argument、get_arguments的功能类似,但是仅从URL查询参数中获取参数值。
(3)RequestHandler.get_body_argument(name)、RequestHandler.get_body_arguments
(name)
与get_argument、get_arguments的功能类似,但是仅从Post提交参数中获取参数值。
一般来说,使用get_argument/get_arguments即可。因为它们是get_query_argument/get_query_arguments和get_body_argument/get_body_arguments的合集。
(4)RequestHandler.get_cookie(name,default=None)
根据Cookie名称获取Cookie值。
(5)RequestHandler.request
返回tornado.httputil.HTTPServerRequest对象实例的属性,通过该对象可以获取关于HTTP请求的一切信息。比如:
|
|
常用的httputil.HTTPServerRequest对象属性如下表所示:
| 属性名 | 说明 |
|---|---|
| method | HTTP请求方法,比如GET、POST等 |
| url | 客户端请求的url的完整内容 |
| query | url中的查询字符串 |
| version | 客户端发送请求时使用的HTTP版本,比如HTTP/1.1 |
| headers | 以字典方式表达的HTTP Headers |
| body | 以字符串方式表达的HTTP消息体 |
| remote_ip | 客户端的IP地址 |
| Protocol | 请求协议,比如HTTP、HTTPS |
| host | 请求消息中的主机名 |
| arguments | 客户端提交的所有参数 |
| files | 以字典方式表达的客户端上传的文件,每个文件名对应一个HTTPFile |
| cookies | 客户端提交的cookie字典 |
- 输出响应函数
输出响应函数是指一组为客户端生成处理结果的工具函数,开发者调用它们以控制URL的处理结果。常用的输出相应函数如下。
(1) RequestHandler.set_status(status_code,reason=None)
设置HTTP Resource中的返回码,如果有描述性的语句,则可以赋值给reason参数。
(2)RequestHandler.set_header(name,value)
以键值对的方式配置HTTP Response中的HTTP头参数。使用set_header配置的Header值将覆盖之前配置的Header,比如:
|
|
本例中的get()函数调用了3次set_header,但是只配置了两个header参数,最后的HTTP Header中的参数将会是:
|
|
(3)RequestHandler.add_header(name,value)
以键值对的方式设置HTTP Response中的HTTP头参数。与set_header不同的是add_header配置的Header值将不会覆盖之前配置的Header,比如:
|
|
最后HTTP Header中的参数将会是:
|
|
(4)RequestHandler.write(chunk)
将给定的块作为HTTP Body发送给客户端。在一般情况下,用本函数输出字符串给客户端,如果给定的块是一个字典,则会将这个块以JSON格式发送给客户端,同时将HTTP header中的Content_type设置成application/json。
(5)RequestHandler.finish(chunk=None)
本方法通知Tornado:Response的生成工作已完成,chunk参数是需要传递给客户端的HTTP body。调用finish()后,Tornado将向客户端发送HTTP Response。本方法适用于对RequestHandler的异步请求处理,异步请求的具体方法详见3.4节。
注意:在同步或协程访问处理的函数中,无需调用finish()函数。
(6)RequestHandler.render(template_name, **kwargs)
用给定的参数渲染模板,可以在本函数中传入模板文件名称和模板参数,比如:
|
|
render()的第1个参数是对模板文件的命名,之后以命名参数的形式传入多个模板参数。Tornado的基本模板语法和Django相同,功能上弱化,高级过滤器不可用。
(7) RequestHandler.redirect(url,permanent=False,status=None)
进行页面重定向。在RequestHandler处理过程中,可以随时调用redirect()函数进行页面重定向,比如:
|
|
在本例LoginHandler的post处理函数中,根据验证是否成功将客户端重定向到不同的页面,如果成功则重定向到next参数所指向的URL;如果不成功,则重定向到”/login"页面。
(8) RequestHandler.clear()
清空所有在本次请求中之前写入的Header和Body内容,比如:
|
|
(9) RequestHandler.set_cookie(name,value)
按键值对设置Response中的Cookie值。
(10) RequestHandler.clear_all_cookies
清空本次请求中的所有Cookie。
异步化及协程化
上述例子都是用同步的方法来处理用户的请求,即在RequestHandler的get()和post()函数中完成所有的处理,当退出get()和post()等函数后马上向客户端返回Response。但是处理逻辑比较复杂或需要等待外部I/O时,这样的处理机制会阻塞服务器线程,并不适合大量客户端高并发的应用场景。
Tornado有两种方式改变同步的处理流程。
- 异步化:针对RequestHandler的处理函数,使用@tornado.web.asynchronous修饰器,将默认的同步机制改为异步机制。
- 协程化:针对RequestHandler的处理函数,使用@tornado.gen.coroutine修饰器,将默认的同步机制改为协程机制。
-
异步化
异步化的RequestHandler处理如下:
|
|
本例中用装饰器tornado.web.asynchronous定义了HTTP访问处理函数get()。这样,当get()函数返回时,对该HTTP访问的请求尚未完成,所以Tornado无法发送HTTP Response给客户端。只有当在随后的on_response()中的finish()函数被调用时,Tornado才知道本次处理已完成,可以发送给Response给客户端。
异步编程虽然提高了服务器的并发能力,但编程方法繁琐。
2.协程化
协程的编程方法示例如下:
|
|
本例中展示仍然是一个转发网站内容的处理器,代码量与相应的同步版本差不多。协程化的关键技术点如下。
- 用tornado.gen.coroutine装饰MainHandler的get()、post()等处理函数。
- 使用异步对象处理耗时操作,比如本例的AsyncHTTPClient。
- 调用yield关键字获取异步对象的处理结果。