章节内容概要
如何操作字符串?
- 如何进行转型?
- 什么是clone?
- 什么是相等型?
- 为什么需要Hashcode?
使用一门语言编程的时候,就应该会遇到到这些问题,而且我们要尝试想想这些问题,为什么会是这样?
一些建议
建议1:正确操作字符串
字符串是常用的一种基本数据类型,不恰当的使用会造成许多额外的性能开销;
先看两行代码:
1
2
|
String str1 = "str1" + 9;
String str2 = "str2" + 9.ToString();
|
第一行代码我们通过ildasm工具查看IL代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
.method private hidebysig static void Main(string[] args) cil managed
{
.entrypoint
// 代码大小 23 (0x17)
.maxstack 2
.locals init (string V_0,
int32 V_1)
IL_0000: nop
IL_0001: ldstr "str1"
IL_0006: ldc.i4.s 9
IL_0008: stloc.1 // 以前的版本, 这里有一个box, 代表会装箱
IL_0009: ldloca.s V_1
IL_000b: call instance string [System.Runtime]System.Int32::ToString()
IL_0010: call string [System.Runtime]System.String::Concat(string,
string)
IL_0015: stloc.0
IL_0016: ret
} // end of method Program::Main
|
第二行代码的IL代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
.method private hidebysig static void Main(string[] args) cil managed
{
.entrypoint
// 代码大小 23 (0x17)
.maxstack 2
.locals init (string V_0,
int32 V_1)
IL_0000: nop
IL_0001: ldstr "str2"
IL_0006: ldc.i4.s 9
IL_0008: stloc.1
IL_0009: ldloca.s V_1
IL_000b: call instance string [System.Runtime]System.Int32::ToString()
IL_0010: call string [System.Runtime]System.String::Concat(string,
string)
IL_0015: stloc.0
IL_0016: ret
} // end of method Program::Main
|
作者给出自己编写的代码中,提出应该尽可能的避免不必要的装箱代码的准则:
原因是, 装箱之所以带来性能损耗,因为它需要完成以下三个步骤:
- 首先,会为值类型在托管堆中分配内存,除了值类型本身分配的内存外,内存总量还需要加上类型对象的指针和同步索引块所占用的内存;
- 将值类型的值复制到新分配的堆内存中;
- 返回已经成为引用类型的对象的地址;
第二个方面: 避免额外的分配内存空间;对于CLR来说,string(字符串) 对象是个特殊的对象,它一旦被赋值就不可改变。在运行时调用System.String类中任何方法或进行任何计算(比如赋值,拼接操作),都会在内存中创建新的字符串对象,这也就意味这要为这些新对象分配新的空间;(这些就是额外的开销)
对于重复拼接字符串,推荐使用StringBuilder来弥补String的不足;
StringBuilder 对象是动态对象,允许扩充它所封装的字符串中字符的数量,但是您可以为它可容纳的最大字符数指定一个值,当修改 StringBuilder 时,在达到容量之前,它不会为其自己重新分配空间。当达到容量时,将自动分配新的空间且容量翻倍。
实际上, 微软提供了一种更为简化的方法, 即string.Format方法, string.Format方法内部使用StringBuilder来进行字符串的格式化;
建议2:使用默认转型方法
大家在编程中经常会碰到的一个问题是,如何对数据进行转换类型?在大部分情况下,当需要对FCL提供的类型进行转换时,都应该使用FCL提供的转换方法。
-
使用类型的转换运算符
显式转换和隐式转换,自定义类型重载运算符转换等;
-
使用内置的Parse, TryParse, 或者ToString(), ToDouble()等方法;
-
使用帮助类提供的方法
类似System.Convert类, System.BitConverter等类进行类型的转换;
-
使用CLR支持的转型
CLR支持的转型,分为上溯转型和下溯转型,实际上就是父类和子类之间的相互转换;
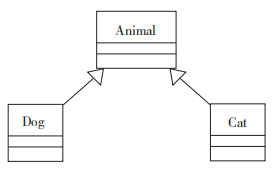
在进行子类向基类转型的时候支持隐式转换。比如Dog显然就是一个Animal;而当Animal转型为Dog的时候,必须是显式转换,因为Animal还可能是个Cat,示例如下:
1
2
3
4
5
|
Animal animal;
Dog dog = new Dog();
animal = dog; // 隐式转换
// dog = animal; // 编译不通过
dog = (Dog)animal; // 必须存在一个显式转换
|
建议3:区分对待强制转型与as和is
secondType = (SecondType)firstType // 这个代码就是强制转型
强制转型可能意味着两件不同的事情:
- FirstType和SecondType彼此依靠转换操作符来完成两个类型之间的转型;
- FirstType是SecondType的基类;
类型之间如果存在强制转换,那么它们之间的关系就在以上两者之间;
建议: 如果类型之间都上溯了某个共同的基类,那么根据此基类进行的转型(基类转型为子类本身)应该使用as。子类和子类之间的转型,则应该提供转换操作符,以便进行强制转型;
as操作符永远不会抛出异常,如果类型不匹配(被转换对象的运行时类型既不是所转换的目标类型, 也不是其派生类型),或者转型的源对象是null, 那么转型之后的值也是null;
1
2
3
4
5
6
7
8
|
static void DoWithSomeType1(object obj)
{
SecondType secondType = obj as SecondType;
if (secondType != null)
{
// ...
}
}
|
对于第二种情况,即FirstType是SecondType的基类;这种情形下,既可以使用强制转型,也可以使用as操作符;
1
2
3
4
5
6
7
8
|
static void DoWithSomeType2(object obj)
{
if (obj is SecondType)
{
SecondType secondType = obj as SecondType;
// ...
}
}
|
这个版本没有上一个版本的效率高,因为进行了两次类型检测, 但是要注意到as运算符有一个问题,就是不能操作基元类型。如果涉及到基元类型的操作,还是需要通过is转型前的判断,以避免转型失败;
建议4:TryParse比Parse好
我们注意到除string外的所有基元类型,会发现它们都有两个将字符串转换为本身的方法:Parse和TryParse, 以类型int为例,这两个方法最简单的原型为:
1
2
|
public static Int32 Parse(string s);
public static bool TryParse(string s, out Int32 result);
|
两者最大的区别是,如果字符串格式不满足的要求,Parse方法触发一个异常;TryParse方法则不会引发异常,它会返回false,同时将result置为0;
写一个demo测试一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
|
static void Test()
{
int res;
long ticks;
Stopwatch sw = Stopwatch.StartNew();
for (int i = 1; i < 1000; i++)
{
try
{
res = int.Parse("123");
}
catch
{
res = 0;
}
}
sw.Stop();
ticks = sw.ElapsedTicks;
Console.WriteLine("int.Parse() 成功, {0} ticks", ticks);
sw = Stopwatch.StartNew();
for (int i = 1; i < 1000; i++)
{
if (int.TryParse("123", out res) == false)
{
res = 0;
}
}
sw.Stop();
ticks = sw.ElapsedTicks;
Console.WriteLine("int.TryParse() 成功, {0} ticks", ticks);
sw = Stopwatch.StartNew();
for (int i = 1; i < 1000; i++)
{
try
{
res = int.Parse("aaa");
}
catch
{
res = 0;
}
}
sw.Stop();
ticks = sw.ElapsedTicks;
Console.WriteLine("int.Parse() 失败, {0} ticks", ticks);
sw = Stopwatch.StartNew();
for (int i = 1; i < 1000; i++)
{
if (int.TryParse("aaa", out res) == false)
{
res = 0;
}
}
sw.Stop();
ticks = sw.ElapsedTicks;
Console.WriteLine("int.TryParse() 失败, {0} ticks", ticks);
}
|
测试的结果如下:
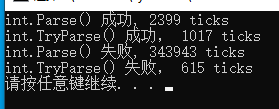
我们可以看到,执行T成功的时候,Parse和TryParse的效率是一个数量级,一个循环里边,TryParse略高于Parse;但是转换执行失败的时候,Parse的效率就会比TryParse低太多了;
建议5:使用int?来确保值类型也可以为null
基元类型可能为null的一些场景:
-
数据库中一个int字段可以被设置为null, 在C#中, int变量去承载这个字段,那么就有必要先判断它是否为null,如果是为null直接赋值给int类型,会报异常;
-
在一个分布式系统中,服务器需要接收并解析来自客户端的数据,一个int型的数据可能在传输过程中丢失或被篡改了,转型失败后应该保存为null值,而不是提供一个初始值;
需要为null的场景还是挺多的,一个可以为空的int类型表示为: Nullable<int> i = null;
可以简写成 int? i = null; 语法T? 是 Nullable<T>的简写;可以为null的类型表示其基础值类型的正常范围内的值再加上一个null值;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
// 可空类型和基元类型的互相转换
int? i = null;
int j = 0;
i = j;
// 可空类型不可隐式转换为对应的基元类型
int? i = 123;
int j;
if (i.HasValue)
{
j = i.Value;
}
else
{
j = 0;
}
// 上一段代码, 可以简写成:
int? i = 123;
int j = i ?? 0;
|
建议6: 区别readonly和const的使用方法
初学者很不容易搞明白readonly和const的使用场合,我也Confuse了很久,一直理解的不好;陆敏技老师的观点是,使用const的理由只有一个,那就是为了效率;但大多数情形下,效率并没有这么高的地位,可能更愿意采用readonly, 因为readonly赋予了代码更多的灵活性;
const和readonly本质的区别是:
-
const是一个编译期的常量,readonly是一个运行时常量;
-
const只能修饰基元类型、枚举类型或者字符串类型,readonly则没有限制;
const是编译期常量,天生就是static的,不可以再给它加上static的修饰符;
而const变量的效率高,是因为经过编译器编译后,我们在代码中引用到const变量的地方会用const变量所对应的
实际值来代替;
readonly是运行时变量,其赋值行为发生在运行时。readonly的全部意义在于:它在运行时第一次被赋值后将不可以改变。”不可以”改变分为两层意思:
- 对于值类型变量,值类型本身不可改变;(readonly, 只读);
- 对于引用变量,引用本身(理解为指针)不可改变;
对于值类型变量:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
class Sample
{
public readonly int ReadOnlyValue;
public Sample(int value)
{
ReadOnlyValue = value;
}
}
static void Main(string[] args)
{
Sample sample = new Sample(100);
sample.ReadOnlyValue = 300;
// A readonly field can only take an assignment in a constructor or at declaration. For more information, see Constructors.
// CS0191 also results if the readonly field is static and the constructor is not marked static.
}
|
报错信息就是: 无法对只读的字段赋值(构造函数或变量初始值指定项中除外)
对于引用类型变量:
Sample2的ReadOnlyValue是一个Student类型的引用类型变量,经过赋值后,变量不能再指向其他的Student实例;
建议7:将0值作为枚举的默认值
允许使用的枚举类型有byte、sbyte、short、ushort、int、uint、long、ulong、应该始终将0值作为枚举的默认值。接下来我们通过示例来说明问题:
1
2
3
4
5
6
7
8
9
10
|
enum Week
{
Money = 1,
Tuesday = 2,
Wednesday = 3,
Thursday = 4,
Friday = 5,
Saturday = 6,
Sunday = 7
}
|
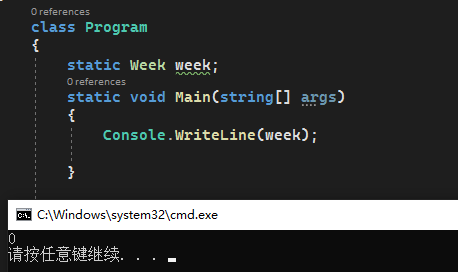
打印出来的值是一个0,可在枚举中并没有定义该值,让人感觉怎么是第八个值出现了。所以建议将0设置为枚举的默认值。(做法可以是: 可以将显式为元素赋值去掉,编译器会自动从0值开始计数,然后逐个为元素的值+1)
建议8:避免给枚举类型的元素提供显式的值
一般情况下,没有必要给枚举类型的元素提供显式的值。创建枚举的理由之一,就是为了代替使用实际的值。不正确的为枚举类型的元素设定显式的值,会带来意想不到的错误。
在建议7的实例下, 给枚举类型Week增加一个元素;
1
2
3
4
5
6
7
8
9
10
11
|
enum Week
{
Money = 1,
Tuesday = 2,
ValueTemp,
Wednesday = 3,
Thursday = 4,
Friday = 5,
Saturday = 6,
Sunday = 7
}
|
1
2
3
4
5
6
|
static void Main(string[] args)
{
Week week = Week.ValueTemp;
Console.WriteLine(week);
Console.WriteLine(week == Week.ValueTemp);
}
|
比较让人困惑的是, Week的赋值为ValueTemp, 但是打印的时候却是Wednesday;
通过调试可以发现。当编译器发现元素ValueTemp的时候,它会自动在Tuesday=2的基础上+1,所以ValueTemp的值和Wednesday的值都是3。可见,枚举元素允许设定重复的值。
注意: 本建议也有例外的情况。例如,当为一个枚举类型指定System.FlagsAttribute属性就意味着可以为这些值执行And、Or、Not、Xor按位运算了,这样一来,枚举的每个元素的值就要求都是2的若干次幂,指数依次递增。
1
2
3
4
5
6
7
8
9
10
11
12
|
[Flags]
enum NewWeek
{
None = 0x0,
Money = 0x1,
Tuesday = 0x2,
Wednesday = 0x4,
Thursday = 0x8,
Friday = 0x10,
Saturday = 0x20,
Sunday = 0x40
}
|
1
2
3
4
5
6
7
8
9
|
static void Main(string[] args)
{
NewWeek newWeek = NewWeek.Thursday | NewWeek.Sunday;
Console.WriteLine(newWeek);
Console.ReadLine();
}
// 运行结果是:
Thursday, Sunday
|
建议9: 习惯重载运算符
在开发的过程中,应该习惯于使用微软提供给我们的语法特性。我想大部分人应该喜欢看到这样的语法特性:
1
2
3
|
int x = 7;
int y = 8;
int total = x + y;
|
而不是看到下面的语法:
1
2
3
|
int x = 7;
int y = 8;
int total = int.Add(x, y);
|
所以我们在自定义类型的时候,也可以考虑看看类型是否可以使用运算符重载。
1
2
3
4
5
6
7
8
9
|
public class Salary
{
public int RMB { get; set; }
public static Salary operator +(Salary s1, Salary s2)
{
s2.RMB += s1.RMB;
return s2;
}
}
|
重载了运算符之后, 现在我们来进行调用的时候就方便了很多。
1
2
3
|
Salary s1 = new Salary() { RMB = 10 };
Salary s2 = new Salary() { RMB = 20 };
Salary s3 = s1 + s2;
|
建议10: 创建对象时需要考虑是否实现比较器
有对象的地方就会存在比较, 在C#的世界也一样; 举个简单的例子, 假设有10个人的Salary列表. 根据排序的需要, 列表需要支持针对基本工资来排序Salary. 这个时候IComparable就会有作用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
class Program
{
static void Main(string[] args)
{
ArrayList array = new ArrayList();
array.Add(1100);
array.Add(1200);
array.Add(1160);
array.Sort();
foreach (var obj in array)
{
Console.WriteLine(obj.ToString());
}
Console.ReadLine();
}
}
|
可以用ArrayList.Sort()方法即可完成排序的任务。不过ArrayList这里只能是一个字段的。假如有姓名、工资两个字段,然后根据工资进行排序那么按照现在的情况来看,ArrayList是无法实现的。所以接口IComparable现在可以派上用场了。现在先定义一个实体,并且实现接口IComparable。
1
2
3
4
5
6
7
8
9
10
11
|
class Salary : IComparable<Salary>
{
public string Name { get; set; }
public int BaseSalary { get; set; }
public int Bonus { get; set; }
public int CompareTo(Salary staff)
{
return BaseSalary.CompareTo(staff.BaseSalary);
}
}
|
实现了IComparable接口之后, 就可以根据BaseSalary来进行排序了;
1
2
3
4
5
6
7
8
9
10
11
|
ArrayList array = new ArrayList();
array.Add(new Salary() { Name = "aehyok", BaseSalary = 12000 });
array.Add(new Salary() { Name = "Kris", BaseSalary = 11200 });
array.Add(new Salary() { Name = "Leo", BaseSalary = 18000 });
array.Add(new Salary() { Name = "Niki", BaseSalary = 20000 });
array.Sort();
foreach (Salary obj in array)
{
Console.WriteLine(string.Format("{0} BaseSalary:{1}", obj.Name, obj.BaseSalary));
}
Console.ReadLine();
|
如果现在不想以基本工资BaseSalary进行排序, 而是以奖金Bonus进行排序, 该如何处理呢? 答案是: 可以使用IComparer来实现一个自定义的比较器 (当然修改Salary实体类中继承的接口方法进行处理肯定是没问题了,但是比较麻烦).
1
2
3
4
5
6
7
8
9
|
public class BounsComparer:IComparer
{
public int Compare(object x, object y)
{
Salary s1 = x as Salary;
Salary s2 = y as Salary;
return s1.Bouns.CompareTo(s2.Bouns);
}
}
|
然后进行排序:
1
2
3
4
|
// code
// 排序时候为Sort方法提供比较器
array.Sort(new BounsComparer());
...
|
我们可以观察到上面的代码, 使用了一个已经不建议的类ArrayList(当泛型出来后, 就建议尽量不使用所有非泛型集合类); 另外一点是, Compare函数中进行了转型处理,这是会影响性能的。如果集合中有成千上万个复杂的实体对象,那么进行排序时耗费的时间是巨大的。所以需要泛型登场,很好的解决了这个问题。
实现的代码如下:
- 实体类实现接口IComparable
- 自定义比较器实现接口IComparer
- 进行排序的调用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
using System;
namespace Advice10
{
class Salary : IComparable<Salary>
{
public string Name { get; set; }
public int BaseSalary { get; set; }
public int Bonus { get; set; }
public int CompareTo(Salary staff)
{
return BaseSalary.CompareTo(staff.BaseSalary);
}
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
|
using System.Collections.Generic;
namespace Advice10
{
class BonusComparer : IComparer<Salary>
{
public int Compare(Salary x, Salary y)
{
return x.Bonus.CompareTo(y.Bonus);
}
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
using System;
using System.Collections.Generic;
namespace Advice10
{
class Program
{
static void Main(string[] args)
{
List<Salary> companySalary = new List<Salary>();
companySalary.Add(new Salary() { Name = "Mike", BaseSalary = 3000, Bonus = 1000, });
companySalary.Add(new Salary() { Name = "Rose", BaseSalary = 2000, Bonus = 4000 });
companySalary.Add(new Salary() { Name = "Jeffry", BaseSalary = 1000, Bonus = 6000 });
companySalary.Add(new Salary() { Name = "Steve", BaseSalary = 4000, Bonus = 3000 });
companySalary.Sort(new BonusComparer()); // 提供一个非默认的比较器
foreach (Salary item in companySalary)
{
Console.WriteLine(item.Name + "\t BaseSalary: " + item.BaseSalary.ToString() + "\t Bonus: " + item.Bonus);
}
}
}
}
|
建议11: 区分对待==和Equals
需要先去明白"相等性"的概念, CLR中将"相等性"分为两类, “值相等性"和"引用相等性”, 如果要比较的两个变量所包含的数值相等, 那么将其定义为"值相等性"; 如果比较的两个变量的引用的是内存中的同一个对象, 那么将其定义为"引用相等性";
无论是操作符"==“还是方法"Equals”, 都倾向于表达这样一个原则;
- 对于值类型, 如果类型的值相等, 就应该返回True;
- 对于引用类型, 如果类型指向同一个对象, 则返回True;
一般说来, 对于值类型, 两者是相同的, 都是比较变量的值; 而对于引用类型, ,等号(==)比较的是两个变量的引用是否一样,即是引用的”地址”是否相同。而对于equals来说仍然比较的是变量的 **”内容”**是否一样;
同时我们也要了解, 无论是操作符"==“还是"Equals"方法都是可以被重载的. 比如, 对于string这样一个特殊的引用类型, 微软认为它的意义更接近于值类型, 因此在Framework Class Library中, string的比较被重载为针对"类型的值"的比较, 而不是针对"引用本身"的比较;
从设计而言, 很多自定义类型(尤其是自定义的引用类型)会存在和string类型比较相近的情况, 如生活中的Person, 如果他们的ID是相等的, 我们就认为两者是同一个人, 这个时候, 需要重载Equals方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
namespace Advice11
{
class Person
{
public string ID { get; private set; }
public Person(string id)
{
this.ID = id;
}
public override bool Equals(object obj)
{
return ID == (obj as Person).ID;
}
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
using System;
namespace Advice11
{
class Program
{
static void Main(string[] args)
{
object a = new Person("NB123");
object b = new Person("NB123");
Console.WriteLine(a == b);
Console.WriteLine(a.Equals(b));
}
}
}
|
这里再引出操作符”==“和"Equals"方法之间的一些区别. 一般来说, 对于引用类型, 如果我们是要去定义"值相等性”, 那应该仅仅去重载Equals方法, 同时让"=="来表示"引用相等性";
建议12: 重写Equals时也要重写GetHashCode
除非考虑到自定义类型会被用作基于散列的集合的键值, 否则不建议重写Equals方法, 因为这会带来一些问题;
如果编译建议11的Person这个类型, 编译器会给出一个警告:
1
2
3
4
5
|
Rebuild started...
1>------ Rebuild All started: Project: Advice11, Configuration: Debug Any CPU ------
1>F:\Demos\CsharpAdvice\Advice11\Person.cs(3,11,3,17): warning CS0659: 'Person' overrides Object.Equals(object o) but does not override Object.GetHashCode()
1> Advice11 -> F:\Demos\CsharpAdvice\Advice11\bin\Debug\Advice11.exe
========== Rebuild All: 1 succeeded, 0 failed 0 skipped ==========
|
如果重写Equals方法而不重写GetHashCode(), 在使用如FCL的Dictionary类的时候, 可能会有一些bug, 我们在Advice11的代码上进行验证:
建议两个实体类, 来使用以下的Dictionary类型:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
using System;
using System.Collections.Generic;
namespace Advice11
{
class Program
{
static Dictionary<Person, PersonMoreInfo> PersonValues = new Dictionary<Person, PersonMoreInfo>();
static void Main(string[] args)
{
AddPerson();
Person bomir = new Person("morn423");
// Console.WriteLine(bomir.GetHashCode());
Console.WriteLine(PersonValues.ContainsKey(bomir));
}
static void AddPerson()
{
Person bomir = new Person("morn423");
PersonMoreInfo bomirValue = new PersonMoreInfo() { SomeInfo = "Bomir's Info" };
PersonValues.Add(bomir, bomirValue);
// Console.WriteLine(bomir.GetHashCode());
Console.WriteLine(PersonValues.ContainsKey(bomir));
}
}
public class PersonMoreInfo
{
public string SomeInfo { get; set; }
}
}
|
结果为True, False.
理论上来说,我们重写了Person类中的Equals方法,也就是说在AddPerson方法中的bomir和在Main函数中的bomir属于”值相等“。从上面的结果可以发现,针对同一个实例,这种结论是正确的,针对不同的实例,这种结果就是有问题的。
实际上, 基于键值的集合(如上面的Dictionary)会根据Key值来查找Value值。CLR内部会优化这种查找,实际上,最终是根据Key值的HashCode来查找Value值。代码运行的时候,CLR首先会调用Person类型的GetHashCode,由于发现Person没有实现GetHashCode,所以CLR最终会调用Object的 GetHashCode方法。
为什么两者实际对一个调用的Object的 GetHashCode会不同?
Object为所有的CLR类型都提供了GetHashCode的默认实现。每new一个对象,CLR都会为该对象生成一个固定的整形值,该整形值在对象的生存周期内不会改变,而该对象默认的GetHashCode实现就是对该整型值求HashCode。所以,在上面的代码中,两个mike兑现虽然属性值都一致,但是它们默认实现的HashCode不一致,这就导致Dictionary中出现异常的行为。
将上面代码中的两行注释代码去掉,运行程序得到输出两个hashcode是不一样的;
要修正上面的问题就需要重写GetHashCode, 简单的重写GetHashCode如下:
1
2
3
4
|
public override int GetHashCode()
{
return this.ID.GetHashCode();
}
|
这时候, 两者的HashCode是一致的,而dictionary也会找到相应的键值。
一些Code上的优化:
- 就语法特性而言, Person类的ID是可读可写的, 但是现实意义下, 一个人一旦踏入社会, ID不应该发生改变, 就像身份证号码一样, 发生改变意味着是另一个人了; 所以应该只实现ID的只读属性, 同理GetHashCode方法也应该基于那些只读的属性或者特性生成HashCode.
- 另外一个问题是, GetHashCode永远只返回一个整型, 而整型类型的容量显然无法满足字符串的容量; 下面这个例子就产生了相同的hashcode:
1
2
3
4
|
string str1 = "NB0903100006";
string str2 = "NB0904140001";
Console.WriteLine(str1.GetHashCode());
Console.WriteLine(str2.GetHashCode());
|
为了减少不同类型之间根据字符串产生相同的HashCode的概率, 一个稍作改进版本的GetHashCode方法如下:
1
2
3
4
|
public override int GetHashCode()
{
return (System.Reflection.MethodBase.GetCurrentMethod().DeclaringType.FullName + "#" + this.ID).GetHashCode();
}
|
Note: 重写Equals方法的同时, 也应该实现一个类型安全的接口IEquatable,所以Person类型的最终代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
using System;
namespace Advice11
{
class Person : IEquatable<Person>
{
public string ID { get; private set; }
public Person(string id)
{
this.ID = id;
}
public override bool Equals(object obj)
{
return ID == (obj as Person).ID;
}
public override int GetHashCode()
{
return (System.Reflection.MethodBase.GetCurrentMethod().DeclaringType.FullName + "#" + this.ID).GetHashCode();
}
public bool Equals(Person other)
{
return ID == other.ID;
}
}
}
|
建议13: 为类型输出格式化字符串
有两种方法可以为类型提供格式化的字符串输出。
一种是意识到类型会产生格式化字符串输出,于是让类型继承接口IFormattable。这对类型来说,是一种主动实现的方式,要求开发者可以预见类型在格式化方面的要求。
更多的时候,类型的使用者需为类型自定义格式化器,这就是第二种方法,也是最灵活多变的方法,可以根据需求的变化为类型提供多个格式化器。
下面我们就来看一下这两种方式的实现。
最简单的字符串输出是为类型重写ToString()方法,如果没有为类型重写该方法,默认会调用Object的ToString方法,它会返回当前类型的类型名称。但即使是重写了ToString()方法,提供的字符串输出也是非常单一的,而通过实现IFormattable接口的ToString()方法,可以让类型根据用户的输入而格式化输出。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
using System;
namespace Advice13
{
class Person : IFormattable
{
public string IDCode { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
// 实现接口IFormattable的方法ToString()
public string ToString(string format, IFormatProvider formatProvider)
{
switch (format)
{
case "ch":
return this.ToString();
case "eg":
return string.Format("{0} {1}", FirstName, LastName);
default:
return this.ToString();
}
}
// 重写Object.ToString()
public override string ToString()
{
return string.Format("{0} {1}", LastName, FirstName);
}
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
using System;
namespace Advice13
{
class Program
{
static void Main(string[] args)
{
Person person = new Person() { FirstName="Bomir", LastName="Wang", IDCode="Morn423" };
Console.WriteLine(person);
Console.WriteLine(person.ToString("ch", null));
Console.WriteLine(person.ToString("eg", null));
}
}
}
|
上面这种方法是在意识到类型会存在格式化字符出输出的需求时, 提前为类型继承了接口IFormattable. 如果类型本身没有提供格式化字符串输出的功能, 这个时候, 格式化器就有用了; 使用格式化器的好处就是可以根据需求的变化, 随时增加或者修改它.
首先定义一个实体类Person:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
using System;
namespace Advice13
{
class Person : IFormattable
{
public string IDCode { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
// 实现接口IFormattable的方法ToString()
public string ToString(string format, IFormatProvider formatProvider)
{
switch (format)
{
case "ch":
return this.ToString();
case "eg":
return string.Format("{0} {1}", FirstName, LastName);
default:
// return this.ToString();
ICustomFormatter customFormatter = formatProvider as ICustomFormatter;
if (customFormatter == null)
{
return this.ToString();
}
return customFormatter.Format(format, this, null);
}
}
// 重写Object.ToString()
public override string ToString()
{
return string.Format("{0} {1}", LastName, FirstName);
}
}
}
|
一个典型的格式化器应该继承IFormatProvider和ICustomerFormatter,看代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
using System;
namespace Advice13
{
class PersonFomartter : IFormatProvider, ICustomFormatter
{
// ICustomFormatter的成员
public string Format(string format, object arg, IFormatProvider formatProvider)
{
Person person = arg as Person;
if (person == null)
{
return string.Empty;
}
switch (format)
{
case "ch":
return string.Format("{0} {1}", person.LastName, person.FirstName);
case "eg":
return string.Format("{0} {1}", person.FirstName, person.LastName);
case "chM":
return string.Format("{0} {1} : {2}", person.FirstName, person.LastName, person.IDCode);
default:
return string.Format("{0} {1}", person.FirstName, person.LastName);
}
}
// IFormatProvider的成员
public object GetFormat(Type formatType)
{
if (formatType == typeof(ICustomFormatter))
return this;
else
return null;
}
}
}
|
可以使用变通的形式,就是将这两种方式合并一起使用的过程;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
using System;
namespace Advice13
{
class Program
{
static void Main(string[] args)
{
Person person = new Person() { FirstName="Bomir", LastName="Wang", IDCode="Morn423" };
PersonFomartter pFomartter = new PersonFomartter();
// 从第一类格式化输出语法
Console.WriteLine(pFomartter.Format("ch", person, null));
Console.WriteLine(pFomartter.Format("eg", person, null));
Console.WriteLine(pFomartter.Format("chM", person, null));
// 从第二类格式化输出语法, 更简洁
Console.WriteLine(person.ToString("ch", pFomartter));
Console.WriteLine(person.ToString("eg", pFomartter));
Console.WriteLine(person.ToString("chM", pFomartter));
}
}
}
|
建议14: 正确实现浅拷贝和深拷贝
为对象创建副本的技术成为拷贝(也叫克隆)。我们将拷贝分为浅拷贝和深拷贝。
浅拷贝 将对象中的所有字段复制到新的对象(副本)中。其中,值类型字段的值被复制到副本中后,在副本中的修改不会影响到源对象对应的值。 而引用类型的字段被复制到副本中的是引用类型的引用,而不是引用的对象,在副本中对引用类型的字段值做修改会影响到源对象本身。
深拷贝 同样,将对象中的所有字段复制到新的对象中。不过无论是对象的值类型字段,还是引用类型字段,都会被重新创建并赋值,对于副本的修改,不会影响到源对象本身。
无论是浅拷贝还是深拷贝,微软都建议用类型继承ICloneable接口的方式明确告诉调用者:该类型可以被拷贝。当然,ICloneable接口只提供了一个声明为Clone的方法,我们可根据需求在Clone方法内实现浅拷贝或深拷贝。一个简答的浅拷贝的实现代码如下所示:
首先定义实体类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
using System;
namespace Advice14
{
class Employee : ICloneable
{
public string IDCode { get; set; }
public int Age { get; set; }
public Department Department { get; set; }
public object Clone()
{
return MemberwiseClone();
}
}
public class Department
{
public string Name { get; set; }
public override string ToString()
{
return Name;
}
}
}
|
调用方代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
using System;
namespace Advice14
{
class Program
{
static void Main(string[] args)
{
Employee bomir = new Employee()
{
IDCode = "morn423",
Age = 30,
Department = new Department() { Name = "Dep1" }
};
Employee kiki = bomir.Clone() as Employee;
Console.WriteLine(kiki.IDCode);
Console.WriteLine(kiki.Age);
Console.WriteLine(kiki.Department);
Console.WriteLine("开始改变bomir的值: ");
bomir.IDCode = "morn456";
bomir.Age = 22;
bomir.Department.Name = "Dep2";
Console.WriteLine(kiki.IDCode);
Console.WriteLine(kiki.Age);
Console.WriteLine(kiki.Department);
}
}
}
|
输出的结果是:
1
2
3
4
5
6
7
8
|
orn423
30
Dep1
开始改变bomir的值:
morn423
30
Dep2
请按任意键继续. .
|
注意到Employee的IDCode属string类型。理论上string类型是引用类型,但是由于该引用类型的特殊性(无论是实际还是语义),Object.MemberwiseClone方法仍旧为其创建了副本。也就是说,在浅拷贝过程,我们应该将字符串看成是值类型。Employee的Department属性是一个引用类型,所以,如果改变了源对象bomir中的值,那么副本kiki中的值也会随之一起变动。
Employee的深拷贝有多种实现方法,最简单的方式是手动的对字段进行逐个的赋值。但是这种方法容易出错,也就是说,如果类型的字段发生变化或有增减,那么该拷贝方法也要发生相应的变化,所以,建议使用序列化的形式来进行深拷贝。Employee深拷贝的一种实现方式如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
using System;
using System.IO;
using System.Runtime.Serialization;
using System.Runtime.Serialization.Formatters.Binary;
namespace Advice14
{
[Serializable]
class Employee : ICloneable
{
public string IDCode { get; set; }
public int Age { get; set; }
public Department Department { get; set; }
public object Clone()
{
using (Stream objectstram = new MemoryStream())
{
IFormatter formatter = new BinaryFormatter();
formatter.Serialize(objectstram, this);
objectstram.Seek(0, SeekOrigin.Begin);
return formatter.Deserialize(objectstram) as Employee;
}
}
}
[Serializable]
public class Department
{
public string Name { get; set; }
public override string ToString()
{
return Name;
}
}
}
|
可以发现, 例子中再次更改bomir的值已经不会影响副本kiki的值了;
由于接口ICloneable只有一个模棱两可的Clone方法, 所以, 如果要在一个类中同时实现浅拷贝和深拷贝, 只能由我们自己实现两个额外的方法, 声明为DeepClone和Shallow。 Employee的最终版本看起来像如下的形式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
[Serializable]
class Employee : ICloneable
{
public string IDCode { get; set; }
public int Age { get; set; }
public Department Department { get; set; }
public object Clone()
{
return MemberwiseClone();
}
public Employee DeepClone()
{
using (Stream objectstram = new MemoryStream())
{
IFormatter formatter = new BinaryFormatter();
formatter.Serialize(objectstram, this);
objectstram.Seek(0, SeekOrigin.Begin);
return formatter.Deserialize(objectstram) as Employee;
}
}
public Employee ShallowClone()
{
return Clone() as Employee;
}
}
|
建议15: 使用dynamic来简化反射实现
Dynamic是Framework4.0的新特性。dynamic的出现让C#具有了弱类型的特性。编译器在编译的时候不再对类型进行检查,编译器默认dynamic对象支持开发者想要的任何类型。如果运行时不包含指定的特性,运行时程序会抛出一个RuntimeBinderException异常。
注意区分dynamic和var关键字的区别, 实际上, var和dynamic完全是两个概念, 不应该放在一起比较;
- var实际上是编译器给我们的“语法糖”, 一旦被编译, 编译器会自动匹配var变量的实际类型, 并用实际类型来替换该变量的声明,这看起来就是好像在编码时候用实际类型来声明的。
- dynamic被编译后,实际上是一个object类型, 只不过编译器会对dynamic类型进行特殊处理,让它在编译期间进行任何的类型检查,而是把类型检查放到了运行期;
- 从VS的编辑窗口能看出来, var声明的“智能感知”, 从VS中能推断出var类型的实际类型。而dynamic不支持智能感知, 因为编译器对运行期的类型一无所知;
看下简单的demo:
作者以10000000次的调用测试中发现,有着非常明显的区别, 普通方法调用发射执行效率远远的低于使用dynamic。第三种方式是优化了发射之后的执行时间,比使用dynamic也有所提升,但是并不是特别明显,虽然带来了性能的提升,不过却牺牲了代码的整洁性。这种实现方式其实是得不偿失的。所以建议大家使用dynamic来优化发射。